데이터 부분집합 추출
Overview
Teaching: 35 min
Exercises: 15 minQuestions
R에서 데이터 일부를 추출하는 작업을 어떻게 수행할 수 있을까요?
Objectives
벡터, 요인, 행렬, 리스트, 데이터프레임 부분집합을 뽑아낼 수 있다.
개별, 다수 요소를 다음 기준으로 뽑아낼 수 있다: 색인, 명칭, 비교 연산을 사용
다양한 자료구조로부터 원소를 건너뛰거나 제거할 수 있다.
R에는 강력한 부분집합 연산자를 다수 구비되어 있다. 이를 완전히 익히게 되면 어떤 유형의 데이터셋에 대해서도 복잡한 연산을 수월하게 수행할 수 있게 된다.
어떤 유형의 객체에서 부분집합을 뽑아낼 수 있는 방식은 6가지가 있다. 다른 자료구조에 대한 부분집합을 뽑아내는 연산자는 3가지가 있다.
R의 핵심으로 가장 많은 일은 하는 것부터 시작해본다: 원자 숫자형 벡터(atomic vector)
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
a b c d e
5.4 6.2 7.1 4.8 7.5
원자 벡터(Atomic vectors)
R에서 문자열, 숫자, 논리 값을 갖는 간단한 벡터를 원자(atomic) 벡터라고 부르는데 이유는 더 이상 단순화할 수 없기 때문이다.
이제 가지고 놀 마루타 벡터를 생성하자. 해당 벡터 내용물을 손에 넣는 방식은 무엇인가?
색인을 사용한 요소 접근
벡터 요소를 추출하는데, 대응되는 색인을 부여하는데, 1부터 시작된다:
x[1]
a
5.4
x[4]
d
4.8
꺾쇠 괄호 연산자는 다른 어떤 함수와 비슷한다. 원자 벡터(그리과 행렬)에 대해, “n번째 요소를 뽑아낸다”라는 의미다.
한번에 다수 요소를 뽑아낼 수도 있다:
x[c(1, 3)]
a c
5.4 7.1
혹은, 벡터 슬라이스로 뽑아낼 수도 있다:
x[1:4]
a b c d
5.4 6.2 7.1 4.8
: 연산자는 왼쪽 요소부터 우측 요소까지 연속된 숫자를 생성한다.
예를 들어, x[1:4] 은 x[c(1,2,3,4)]와 동등하다:
1:4
[1] 1 2 3 4
c(1, 2, 3, 4)
[1] 1 2 3 4
동일한 원소를 여러번 추출하는 것도 가능하다:
x[c(1,1,3)]
a a c
5.4 5.4 7.1
벡터를 벗어난 숫자를 뽑아내려고 하면, R은 결측값을 반환한다:
x[6]
<NA>
NA
길이 1을 갖는 벡터로 NA가 담겨있고, 명칭도 NA다.
0번째 요소를 뽑아내려고 하면, 공벡터가 반환된다:
x[0]
named numeric(0)
R에서 벡터 번호매기는 것은 1에서 시작
대다수 프로그래밍 언어(C와 파이썬)에서, 벡터 첫번째 요소는 색인 0을 갖는다. R에서, 첫번째 요소는 1 이다.
요소 건너뛰고 제거하기
벡터 색인으로 음수를 사용하면, R은 명세된 숫자를 제외한 모든 요소를 반환한다:
x[-2]
a c d e
5.4 7.1 4.8 7.5
다수 요소를 건너뛸 수도 있다:
x[c(-1, -5)] # or x[-c(1,5)]
b c d
6.2 7.1 4.8
Tip: 연산작업 순서
초보자가 범하는 일반적인 실수는 벡터 슬라이스 건너뛰기 연산을 시도할 때 일어나다. 먼저 사람 대부분은 순열을 다음과 같이 부정연산을 통해 변경하려 한다:
x[-1:3]다소 암호스런 오류가 제시된다:
Error in x[-1:3]: only 0's may be mixed with negative subscripts하지만, 연산작업 우선수위를 기억해보자.
:연산자는 사실 함수다. 그래서, 일어난 상황은 -1을 첫번째 인자로 받고, 두번째 인자로 3을 받아서, 연속된 숫자를 생성해낸다:c(-1, 0, 1, 2, 3).올바른 해법은 함수 호출을 괄호로 감싸는 것이다.
-연산자가 결과를 도출한다:x[-(1:3)]d e 4.8 7.5{.callout}
벡터에서 요소를 제거하려면, 결과를 다시 벡터에 대입할 필요가 있다:
x <- x[-4]
x
a b c e
5.4 6.2 7.1 7.5
도전과제 1
다음과 같이 코드가 주어졌다:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)다음 출력결과를 산출하는 적어도 서로 다른 명령어 2개 제시해보자:
{.r, echo=FALSE} x[2:4]서로 다른 정답을 찾은 후에, 작업결과를 옆 사람과 비교한다. 서로 다른 전략을 취했나요?
도전과제 1에 대한 해답
x[2:4]b c e 6.2 7.1 7.5x[-c(1,5)]b c e 6.2 7.1 7.5x[c(2,3,4)]b c e 6.2 7.1 7.5
명칭으로 부분집합 뽑아내기
색인 대신에 명칭을 사용해서, 요소를 뽑아낼 수 있다:
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # we can name a vector 'on the fly'
x[c("a", "c")]
a c
5.4 7.1
명칭을 사용한 것이 객체에 대한 부분집합을 뽑아내는 훨씬 더 신뢰성 있는 방식이다: 다양한 요소 위치는 부분집합을 뽑아내는 연산자를 연결해서 적용할 때 종종 변경되지만, 명칭은 항상 동일하게 남게 마련이다!
논리 연산자를 통해서 부분집합 뽑아내기
부분집합을 뽑아내는데 논리 벡터를 사용할 수도 있다:
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
c e
7.1 7.5
비교연산자(예를 들어, >, <, ==)로 논리 벡터가 생성되기 때문에,
이를 사용해서 간결하게 벡터 부분집합을 추출할 수 있다: 다음 문장은
앞선 문장과 동일한 결과를 출력한다.
x[x > 7]
c e
7.1 7.5
상기 문장을 분해하면, 첫째로 x>7을 평가해서, 논리벡터
c(FALSE, FALSE, TRUE, FALSE, TRUE)을 만들어내고,
TRUE 값에 대응되는 벡터 x 원소를 추출하게 된다:
==을 사용해서 명칭으로 색인을 두어 추출하는 방식을 모사할 수 있다
(비교로 = 대신에 ==을 사용함을 기억한다):
x[names(x) == "a"]
a
5.4
Tip: Combining logical conditions
We often want to combine multiple logical criteria. For example, we might want to find all the countries that are located in Asia or Europe and have life expectancies within a certain range. Several operations for combining logical vectors exist in R:
&, the “logical AND” operator: returnsTRUEif both the left and right areTRUE.|, the “logical OR” operator: returnsTRUE, if either the left or right (or both) areTRUE.You may sometimes see
&&and||instead of&and|. These two-character operators only look at the first element of each vector and ignore the remaining elements. In general you should not use the two-character operators in data analysis; save them for programming, i.e. deciding whether to execute a statement.
!, the “logical NOT” operator: convertsTRUEtoFALSEandFALSEtoTRUE. It can negate a single logical condition (eg!TRUEbecomesFALSE), or a whole vector of conditions(eg!c(TRUE, FALSE)becomesc(FALSE, TRUE)).Additionally, you can compare the elements within a single vector using the
allfunction (which returnsTRUEif every element of the vector isTRUE) and theanyfunction (which returnsTRUEif one or more elements of the vector areTRUE).
도전과제 2
코드가 다음과 같이 주어져 있다:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)a b c d e 5.4 6.2 7.1 4.8 7.5
x값에서 4보다 크고, 7보다 작은 것을 추출하는 코드를 작성해보자.도전과제 2에 대한 해답
x_subset <- x[x<7 & x>4] print(x_subset)a b d 5.4 6.2 4.8
Tip: 유일무이하지 않은 명칭(Non-unique names)
벡터에 원소 다수가 동일 명칭을 갖을 수 있음에 유의해야만 된다. (데이터프레임에서, 칼럼이 동일한 명칭을 갖을 수 있다 — R에서 이런 점을 회피하려고 하지만 — 하지만, 행 명칭은 유일무이해야 된다.) 다음 예제를 고려해보자:
x <- 1:3 x[1] 1 2 3names(x) <- c('a', 'a', 'a') xa a a 1 2 3x['a'] # only returns first valuea 1x[names(x) == 'a'] # returns all three valuesa a a 1 2 3
Tip: 연산자에 대한 도움말 얻기
인용부호 내부에 찾고자 하는 연산자를 감싸서 도움말을 검색할 수 있다:
help("%in%")혹은?"%in%".
이름을 갖는 원소 건너뛰기
이름을 갖는 원소를 건너뛰거나 제거하는 것은 다소 더 어렵다. 문자열에 마이너스를 붙여 이름이 붙은 원소를 건너뛰기 하고자 한다면, R이 불평을 하는데, 이유는 문자열에 마이너스를 어떻게 처리할지 모르기 때문이다:
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # we start again by naming a vector 'on the fly'
x[-"a"]
Error in -"a": 단항연산자에 유효한 인자가 아닙니다
하지만, != 연산자를 사용하면 논리 벡터를 생성해서 원하는 바를 쟁취할 수 있다:
x[names(x) != "a"]
b c d e
6.2 7.1 4.8 7.5
다수 명칭을 갖는 인덱스로 건너뛰는 것도 그리 녹록하지 않다. "a", "c" 원소를 누락시키고자 한다고 가정하고, 다음과 같이 시도해 보자:
x[names(x)!=c("a","c")]
Warning in names(x) != c("a", "c"): 두 객체의 길이가 서로 배수관계에 있지
않습니다
b c d e
6.2 7.1 4.8 7.5
R이 뭔가 작업을 수행하는데, 주의가 필요하다는 경고를 보내고, 명확히 잘못된 답을 준다(벡터에 "c" 원소가 여전히 포함되어 있다)!
이 경우에 !=이 실제로 하는 작업은 무엇일까? 정말 좋은 질문이다.
재사용(Recycling)
다음 코드에 대해서 비교연산 구성요소에 대해서 살펴보자:
names(x) != c("a", "c")
Warning in names(x) != c("a", "c"): 두 객체의 길이가 서로 배수관계에 있지
않습니다
[1] FALSE TRUE TRUE TRUE TRUE
names(x)[3] != "c"이 명백히 false일때, 왜 R은 벡터의 세번째 원소에 FALSE를 던질까?
!=을 사용할 때, R은 왼쪽편의 각 원자와 우측편의 대응 원자와 비교를 한다.
다른 길이를 갖는 벡털르 비교할 때 무슨 일이 일어날까?
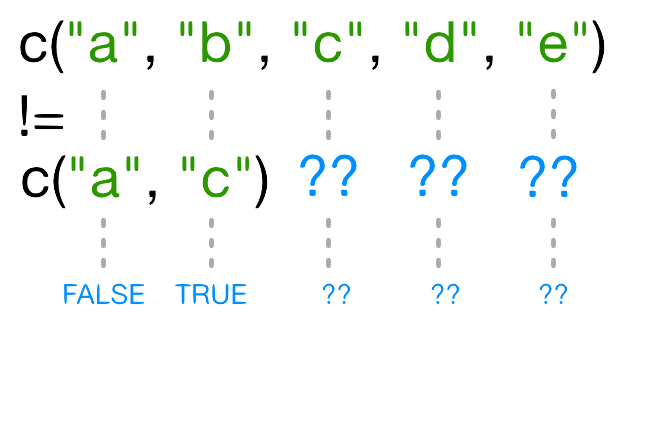
한 벡터가 다른 벡터보다 길이가 짧을 때, 재사용(recycle)이 발생된다:
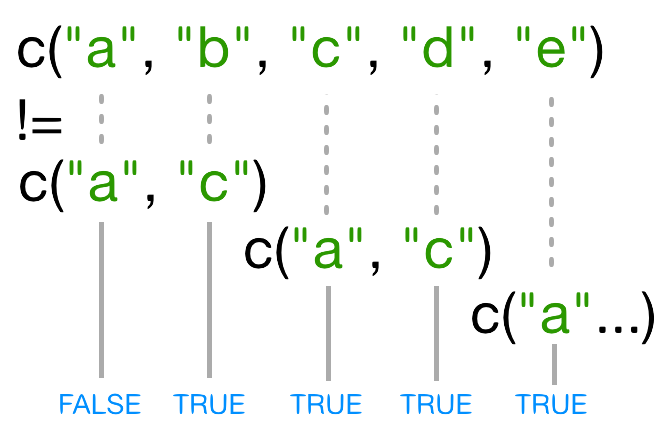
이번 사례의 경우, R은 names(x)과 매칭이 되도록 필요한만큼 c("a", "c")을 반복한다.
즉, c("a","c","a","c","a")이 된다.
재사용된 "a"이 names(x)의 세번째 원소와 매칭이 되지 않기 때문에 != 값은 TRUE가 된다.
이번 경우에, 더 긴 벡터 길이가 5라서 짧은 벡터 길이 2의 배수가 되지 않기 때문에,
R에서 경고 메시지를 띄운다.
운이 나빠서 names(x)에 여섯번째 원소가 포함된다면, R은 조용하게 잘못된 작업을 수행하다.
즉, 코드를 작성했던 분이 의도하지 않는 작업을 수행한다.
이러한 재활용 규칙은 참 발견하기 어렵고 미묘한 버그를 만들어 낼 수 있다!
R로 하여금 정말 원하는 바(우측편의 모든 원소와 매칭되는 왼쪽의 원소를 찾아내는 바)를 수행하도록 하는 방법은 %in% 연산자를 사용하는 것이다.
%in% 연산자는 좌측편의 각 원소를 탐색하는데 이번 경우 x의 명칭을 찾아보고 “해당 원소가 두번째 인자에도 존재하는가?”라고 묻는다.
여기서는 값을 제외하고자 하기 때문에 !연산자를 사용해서 “in”을 부정하는 “not in”이 되도록 한다:
x[! names(x) %in% c("a","c") ]
b d e
6.2 4.8 7.5
도전과제 3
리스트 특정 원소와 매칭되는 원소를 뽑아내는 작업은 데이터 분석 작업에서 매우 흔한 일이다. 예를 들어, gapminder 데이터셋에
country와continent변수가 포함되어 있다. 두 척도 간에는 어떤 공통 정보도 없다. 동남아시아에서 정보를 추출한다고 가정해보자: 동남아시아에 속한 모든 국가에는TRUE가 되고, 그렇지 않는 경우는FALSE가 되는 논리 벡터를 생성하는 연산을 어떻게 구성할 수 있을까?다음 데이터를 가지고 있다고 가정하자:
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos") ## read in the gapminder data that we downloaded in episode 2 gapminder <- read.csv("data/gapminder_data.csv", header=TRUE) ## extract the `country` column from a data frame (we'll see this later); ## convert from a factor to a character; ## and get just the non-repeated elements countries <- unique(as.character(gapminder$country))
==만 사용하는 경우 잘못된 방식으로 경고가 뜰 것이다;==와|을 사용하는 경우 투박한 방식이 된다;%in%을 사용하는 방법이 훨씬 깔끔하다. 세가지 방식을 적용해서 원하는 바를 얻을 수 있는지 살펴보고, 동작하는 방식(동작하지 않는 방식)을 설명해 보라.도전과제 3에 대한 해법
countries==seAsia을 사용하는 것은 문제에 대한 틀린 방식이다. 이유는"In countries == seAsia : longer object length is not a multiple of shorter object length"경고를 주는 것은 물론이고, 잘못된 오답을 주는데 이유는seAsia벡터의 재사용 값이country에 매칭되는 값과 제대로 대응되지 않기 때문이다.- 문제에 대한 투박한 (하지만, 기술적으로 맞는) 방식은 다음과 같다.
(countries=="Myanmar" | countries=="Thailand" | countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")(혹은
countries==seAsia[1] | countries==seAsia[2] | ...). 이런 코딩방식은 올바른 정답을 주지만, 얼마나 어색한지 바로 알 수 있다. (만약 좀더 긴 목록에서 국가를 선택하게 되면 어떨까?)
- 이번 문제에 대한 최선의 방식은
countries %in% seAsia와 같이 코드를 작성하는 것이다. 정답이기도 하고 타이핑하기 쉽고 가독성도 높다.
특수값 처리하기
어느 지점에 다다르면, R 함수에 처리할 수 없는 결측값, 무한값, 정의되지 않는 값을 갖는 데이터와 마주하게 된다.
이런 유형의 데이터를 필터링하는데 사용되는 특수 함수가 있다:
is.na는 벡터, 행렬, 데이터프레임에 포함된NA위치를 반환한다.- 마찬가지로,
is.nan와is.infinite함수도NaN와Inf값에 대한 동일한 작업을 수행한다. is.finite함수는NA,NaN,Inf값을 포함하지 않는 벡터, 행렬, 데이터프레임에 대한 모든 위치정보를 반환한다.na.omit는 벡터에서 모든 결측값을 필터링해서 제외시키다.
요인 부분집합으로 뽑아내기
지금까지 벡터 부분집합을 뽑아내는 다양한 방식을 탐색했다. 다른 자료구조에 대한 부분집합은 어떻게 뽑아낼 수 있을까?
요인 부분집합 뽑아내기는 벡터 부분집합 뽑아내기와 동일한 방식으로 동작한다.
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
[1] a a
Levels: a b c d
f[f %in% c("b", "c")]
[1] b c c
Levels: a b c d
f[1:3]
[1] a a b
Levels: a b c d
중요한 주의점 하나는 건너뛰는 요소가 설사 해당 범주가 요인으로 존재하지 않더라도, 수준(level)을 제거하지 않는다는 점이다:
f[-3]
[1] a a c c d
Levels: a b c d
행렬 부분집합 뽑아내기
행렬의 경우도 [ 함수를 사용해서 부분집합을 뽑아낸다.
이번 경우에는 인자를 두개 사용한다: 첫번째 인자는 행에 적용되고, 두번째 인자는 칼럼에 적용된다:
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808
첫번째 혹은 두번째 인자를 공백으로 남겨놓을 수도 있는데, 모든 행 혹은 칼럼을 각각 불러올 경우 사용한다:
m[, c(3,4)]
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.98935170
행 혹은 칼럼 하나만 접근하고자 하면, R이 자동으로 결과값을 벡터로 전환시킨다:
m[3,]
[1] -0.8356286 0.5757814 1.1249309 0.9189774
결과값을 행렬로 그대로 유지하고자 한다면, 세번째 인자를 명세할 필요가 있다;
drop = FALSE:
m[3, , drop=FALSE]
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774
벡터와 달리, 행렬 외부 행과 칼럼을 접근하고자 하면, R이 오류를 던진다:
m[, c(3,6)]
Error in m[, c(3, 6)]: 첨자의 허용 범위를 벗어났습니다
Tip: 고차원 배열 {.callout}
다차원 배열을 다룰 때,
[에 넘겨지는 각 인자가 차원에 대응된다. 예를 들어, 3D 배열에서 첫세개 인자는 각각 행, 열, 깊이 차원에 대응된다.
행렬을 까면 정말 자료형이 벡터라서, 단지 인자 하나로만 부분집합을 추출할 수도 있다:
m[5]
[1] 0.3295078
보통 유용하지는 않다. 하지만, 행렬이 열우선형식(column-major format)으로 기본디폴트 설정으로 되어있음에 주목한다. 즉, 벡터 요소가 칼럼방향으로 배열된다는 것을 의미한다:
matrix(1:6, nrow=2, ncol=3)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
행렬을 행우선으로 쭉 펼치고자 한다면, byrow=TRUE를 사용한다:
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
행과 칼럼 색인 대신에 행명칭(rownames)과 열명칭(column names)을 사용해서 배열 부분집합을 뽑아낼 수 있다.
도전과제 4
코드가 다음과 같이 주어져 있다:
m <- matrix(1:18, nrow=3, ncol=6) print(m)[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 4 7 10 13 16 [2,] 2 5 8 11 14 17 [3,] 3 6 9 12 15 18
- 다음 중 어떤 명령어가 값 11과 14를 추출하는 하는가?
A.
m[2,4,2,5]B.
m[2:5]C.
m[4:5,2]D.
m[2,c(4,5)]Solution to challenge 4
D
리스트 부분집합 뽑아내기
이제 몇가지 새로운 부분집합을 뽑아내는 연산자를 소개한다.
리스트 부분집합을 뽑아내는데 사용되는 함수가 세가지 있다;
원자벡터와 행렬에서 살펴본 [, 그리고 [[, $이 있다.
[을 사용하면, 항상 리스트만 반환한다.
리스트 부분집합을 뽑아내고자 하지만, 원소는 뽑아내고 싶지 않다면, 아마도 [ 연산자를 사용할 것이다.
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(iris))
xlist[1]
$a
[1] "Software Carpentry"
상기 명령어는 원소 하나만 갖는 리스트를 반환한다.
[ 연산자를 사용해서 원자벡터에 적용한 그대로 리스트 원소를 부분집합으로 뽑아낼 수 있다.
하지만, 리스트가 재귀적으로 되어 있지 않다면, 비교 연산자는 동작하지 않는다.
이유는 비교 연산자가 데이터 구조 내부 개별 요소가 아닌, 리스트 각 요소에 내재한 자료구조로 되어있기 때문이다.
xlist[1:2]
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10
리스트 개별 원소를 추출하려면, 이중 꺾쇠 함수를 사용한다: [[.
xlist[[1]]
[1] "Software Carpentry"
이제 결과값이 리스트가 아닌 벡터에 주목한다.
한번에 요소 하나이상을 추출할 수는 없다:
xlist[[1:2]]
Error in xlist[[1:2]]: 첨자의 허용 범위를 벗어났습니다
요소를 건너뛰는 것도 사용할 수 없다:
xlist[[-1]]
Error in xlist[[-1]]: attempt to select more than one element in get1index <real>
하지만, 명칭을 사용해서 요소에 대한 부분집합으로 뽑아내거나, 요소를 추출할 때 사용할 수 있다:
xlist[["a"]]
[1] "Software Carpentry"
$ 함수는 명칭으로 요소를 뽑아내는데 사용되는 초간편 방법이다:
xlist$data
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
도전과제 5
리스트가 다음과 같이 주어져 있다:
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(iris))리스트와 벡터 부분집합을 추출하는 지식을 활용해서,
xlist에서 숫자 2를 추출한다. 힌트: 숫자 2는 리스트 “b” 항목 내부에 담겨있다.도전과제 5에 대한 해답
xlist$b[2][1] 2xlist[[2]][2][1] 2xlist[["b"]][2][1] 2
도전과제 6
선형 모형이 다음과 같이 주어져 있다:
mod <- aov(pop ~ lifeExp, data=gapminder)잔차 자유도를 추출하라. 힌트:
attributes()함수가 도움을 줄 것이다.도전과제 6에 대한 해법
attributes(mod) ## `df.residual` is one of the names of `mod`mod$df.residual
데이터프레임
데이터프레임을 까면 내부는 리스트로 구성된 것이라는 점을 기억한다. 그래서 유사한 규칙이 적용된다. 하지만, 데이터프레임도 2차원 객체다:
[함수에 인자를 하나만 넣으면 리스트와 동일하게 동작한다.
즉, 각 리스트 요소는 칼럼에 대응된다.
작업결과 나오는 객체는 데이터프레임이다:
head(gapminder[3])
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372
유사하게, [[ 함수는 칼럼 한개만 추출하는데 동작된다:
head(gapminder[["lifeExp"]])
[1] 28.801 30.332 31.997 34.020 36.088 38.438
명칭으로 칼럼을 추출하는데 사용되는 편리한 단축어가 $이다:
head(gapminder$year)
[1] 1952 1957 1962 1967 1972 1977
인자가 두개 있는 경우, [ 함수는 행렬에 대해서와 마찬가지로 동작한다:
gapminder[1:3,]
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
행 하나만 부분집합으로 뽑아내면, 결과는 데이터프레임이 되는데 이유는 각 요소가 혼합된 자료형으로 구성되었기 때문이다:
gapminder[3,]
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
하지만, 단일 칼럼에 대해서 결과는 벡터다. drop = FALSE를 세번째 인자로 넣으면 바꿀 수 있다.
도전과제 7
데이터프레임 부분집합을 뽑아내는 오류가 다음에 나와 있는데 이를 버그없이 수정하라:
- 1957년에 수집된 관측점을 뽑아내라.
gapminder[gapminder$year = 1957,]
- 1에서 4를 제외한 모든 칼럼을 뽑아내라.
gapminder[,-1:4]
- 기대수명이 80세 이상 되는 행을 추출하라.
gapminder[gapminder$lifeExp > 80]
- 첫번째 행과 4번째 5번째 칼럼(
lifeExp,gdpPercap)을 뽑아내라. .gapminder[1, 4, 5]
- 고급: 2002년과 2007년에 대한 정보를 담고 있는 행을 추출하라.
gapminder[gapminder$year == 2002 | 2007,]도전과제 7에 대한 해법
데이터프레임 부분집합을 뽑아내는 오류가 다음에 나와 있는데 이를 버그없이 수정하라:
1957년에 수집된 관측점을 뽑아내라.
# gapminder[gapminder$year = 1957,] gapminder[gapminder$year == 1957,]1에서 4를 제외한 모든 칼럼을 뽑아내라.
# gapminder[,-1:4] gapminder[,-c(1:4)]기대수명이 80세 이상 되는 행을 추출하라.
# gapminder[gapminder$lifeExp > 80] gapminder[gapminder$lifeExp > 80,]첫번째 행과 4번째 5번째 칼럼(
lifeExp,gdpPercap)을 뽑아내라. (continentandlifeExp).# gapminder[1, 4, 5] gapminder[1, c(4, 5)]고급: 2002년과 2007년에 대한 정보를 담고 있는 행을 추출하라.
# gapminder[gapminder$year == 2002 | 2007,] gapminder[gapminder$year == 2002 | gapminder$year == 2007,] gapminder[gapminder$year %in% c(2002, 2007),]
도전과제 8
gapminder[1:20]명령어는 왜 오류를 반환하는가?gapminder[1:20,]와 어떻게 다른가?
gapminder_small이라는 데이터프레임을 생성하는데 1에서 9까지 행과 19에서 23까지 행만 포함한다. 이 작업을 하나 혹은 두 단계로 작성한다.도전과제 8에 대한 해답
gapminder는 데이터프레임이라, 이차원에서 부분집합을 추출할 필요가 있다.gapminder[1:20, ]명령어는 첫 20행과 모든 칼럼을 추출한다.gapminder_small <- gapminder[c(1:9, 19:23),]
Key Points
R에서 인덱스는 0이 아니라, 1에서 시작.
위치로 개별값을 접근하는데,
[]을 사용.
[low:high]을 사용해서 데이터 슬라이스 작업 수행.Access arbitrary sets of data using
[c(...)]을 사용해서 임의 지점 데이터에 접근하는데 사용.논리 연산자와 논리 벡터를 사용해서 데이터 일부 부분집합으로 추출.