Xpath를 사용해서 웹페이지 콘텐츠 선택하기
Overview
Teaching: 30 min
Exercises: 15 minQuestions
웹페이지에서 특정 요소(element)를 선택하는 방법은 무엇인가요?
XPath는 무엇이고 어떻게 사용하나요?
Objectives
XPath 쿼리를 소개한다.
XML 혹은 HTML 문서 구조를 설명한다.
브라우저에서 잠재된 웹페이지 HTML 콘텐츠를 보는 방법을 설명한다.
브라우저에서 XPath 쿼리를 실행하는 방법을 설명한다.
XPath 구문을 소개한다.
XPath 구문을 사용해서 웹페이지 요소를 선택한다.
본격적으로 웹스래핑을 시작하기 전에, 먼저 스크래핑할 웹페이지에서 추출 대상을 명확히 하는데 필요한 기술을 소개하는데 일부 시간을 할애한다.
이번 학습 교재는 Kim Pham (@tolloid)님이 토론토 2016년 Library Carpentry workshop을 위해 작성된 XPath and XQuery Tutorial에서 차용한 것임을 밝혀둔다.
들어가며
XPath(XML Path Lanuage 줄임말)는 표현언어(Expression Language)로 XML 문서 일부를 지정하는데 사용된다. XPath 그 자체로 사용되는 경우는 매우 드물고 XML 문서를 조작용도로 사용되는 소프트웨어와 프로그래밍 언어 내부에 조합되어 사용된다. 해당 XML 문서에는 XSLT, XQuery 혹은 학습 후반부에 소개되는 웹스크래핑 도구가 포함된다. XPath는 HTML처럼 XML과 유사한 구조를 갖는 문서에서도 활용될 수 있다.
마크업 언어
XML과 HTML 모두 마크업 언어(markup languages)다. 이것이 의미하는 바는 태그와 규칙 집합을 사용해서 데이터에 관한 정보를 구조화하고 제공한다는 것이다. 이런 구조를 통해 해당 정보를 처리하고, 편집하고, 외양을 지정하고, 화면에 표시하고, 출력하는 등 다양한 작업을 자동화하는데 도움이 된다.
XML 문서는 데이터를 일반 평문 텍스트 형태로 저장한다. 이를 통해 데이터를 저장하고, 전송하고 공유하는데 소프트웨어와 하드웨어에 종속되지 않아도 되는 기능을 제공한다. XML 포맷은 공개된 오픈 포맷이라서 특정 소프트웨어에 구속되지 않음을 의미한다. 누구나 XML 문서를 임의 텍스트 편집기로 열 수 있고 XML 문서에 담긴 데이터는 원래 형태 그래도 읽을 수 있음을 의미한다. 이를 통해서 호화되지 않는 시스템간에 교환이 가능하고 데이터 변환 수월성을 획득하게 된다.
XML과 HTML
HTML과 XML은 매우 유사한 구조를 갖고 있어, 이런 이유로 인해서 XPath를 사용해서 HTML 문서와 XML 문서간에 자유로이 넘나들 수 있게 된다. 사실 HTML5가 시작되면서, HTML 문서는 완전한 XML 문서가 되었다. 이런 의미에서 HTML은 XML의 방언처럼 굳어지게 되었다.
XML 문서는 다음과 같은 기본 구문 규칙을 따른다:
- XML 문서는 노드(node)를 사용하여 구성되고, 노드에는 요소(element) 노드, 속성(attribute) 노드, 텍스트 노드가 포함된다.
- XML 요소 노드는 시작 태그와 마무리 태그를 갖추어야 한다. 예를 들어,
<catfood>시작 태그와</catfood>마무리 태그. - XML 태그는 대소문자를 구별한다. 예를 들어,
<catfood>태그와</catfood>태그는 같지 않다. - XML 요소는 올바르게 중첩되어(nested)야 된다:
<catfood>
<manufacturer>Purina</manufacturer>
<address> 12 Cat Way, Boise, Idaho, 21341</address>
<date>2019-10-01</date>
</catfood>
- Text nodes (data) are contained inside the opening and closing tags
-
XML attribute nodes contain values that must be quoted, e.g.
- 텍스트 노드(데이터)는 시작 태그와 마무리 태그 사이에 담겨져야만 된다.
- XML 속성 노드는 인용부호로 감싼 값을 포함해야 된다.
<catfood type="basic"></catfood>
XPath 표현식(Expressions)
XPath는 표현식을 활용해서 작성된다. XML 문서에 표현식 평가가 마무리 되면, 선택하고자 하는 노드가 포함된 객체를 반환시킨다. 평문 텍스트 문서와 달리, XML 데이터는 노드와 하위 노드로 엮어져 구조화되어 있다. 따라서, XPath를 사용할 때, 정규 표현식을 사용할 때처럼 원문 텍스트 혹은 데이터값을 쿼리하는 것은 아니다. 대신에 XPath는 XML 문서로 구조화된 사실을 활용해서 찾고자 하는 데이터를 선택하는데 노드 구조를 훑어 나가는 방식을 취한다.
XPath is typically used to select and compare nodes, not edit them. To manipulate or edit nodes, another language such as XQuery would be used instead.
XPath는 노드를 선택하고 비교하는데 사용되는 것이 일반적이고 편집할 때는 사용되지 않는다. 노드를 조작하거나 편집하는데 XQuery 같은 또 다른 언어를 일반적으로 대안으로 사용한다.
XPath 는 구조화된(structured) 데이터를 가정한다.
XPath사용을 비유하면 고급 검색 함수를 사용해서 도서관 카탈로그 검색하는 것으로 간주할 수도 있다. 도서 카탈로그에 서지정보가 도서관 데이터베이스에 차곡차곡 구조화되어 있다는 사실을 이용할 때, 쿼리하고자 하는 메타데이터 특정 필드명을 명세하는 것으로 갈음하는 것과 같다. 예를 들어, 저자가 Shakespeare가 아니고 Shakespeare에 대한 책을 검색할 때, “도서 제목” 필드만 해당 검색어 Shakespeare를 넣어 고급 검색작업을 수행하는 것과 같다.정규 표현식과 달리, 상기 사실이 의미하는 바는 검색하고자 하는 데이터가 어떨지 미리 알 필요가 없다는 것을 의미한다. 단지, 해당 정보가 위치한 노드(필드)만 알면된다.
이제 XPath 사용을 시작하자.
XPath를 사용해서 HTML 노드 나무를 탐색
XML 혹은 HTML 문서 구조를 표현하는 인기있는 방식은 노드 나무(node tree)를 채택하는 것이다:
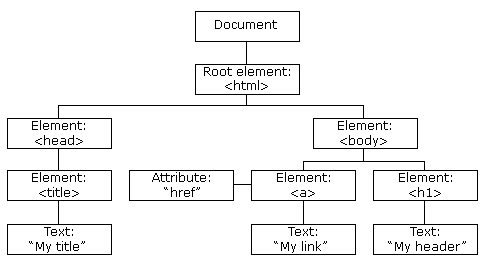
HTML 문서에서 모든 것이 노드다:
- 전체 문서가 문서 노드(document node)다.
- 모든 HTML 요소도 요소 노드(element node)다.
- HTML 요소 내부 텍스트도 텍스트 노드(text node)다.
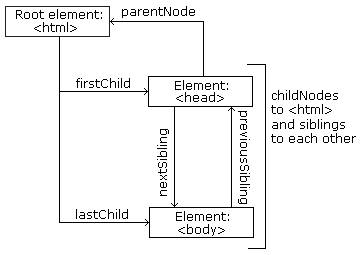
이런 나무에서 노드는 서로 서로 위계 관계를 갖는다. 부모(parent), 자식(child), 형제자매(sibling) 용어를 사용해서 노드간의 관계를 기술한다:
- 노드로 구성된 나무에서, 최상위 노드를 루트 혹은 루트 노드라고 부른다.
- 모든 노드는 정확하게 한부모를 갖는다. 루트 노드는 예외로 부모가 없다.
- 노드는 자식이 없거나 하나 혹은 다수를 갖을 수 있다.
- 형제자매 노드는 같은 부모를 갖는 노드를 일컫는다.
- 노드에서 노드로 연결 순열을 경로(path)라고 일컫는다.
XPath에서 경로는 슬래쉬(/)를 사용해서 노드 연결 순열에 단계를 구분한다.
URL 혹은 유닉스 디렉토리와 대단히 유사하다.
XPath에서 모든 표현식은 문맥 노드(context node)에 기반해서 평가된다.
문맥 노드는 경로가 시작되는 노드가 된다.
기본설정된 문맥 노드는 루트 노드로 슬래쉬(/)로 표기된다.
가장 유용한 경로 표현식(Path Expression)은 다음과 같다:
| 표현식 | 상세설명 |
|---|---|
nodename |
“nodename” 노드 명칭을 갖는 모든 노드를 선택한다. |
/ |
시작하는 단일 슬래쉬는 루트 노드에서 선택임을 지칭하고, 후속 슬래쉬는 현재노드에서 자식노드 선택임을 지칭함. |
// |
현재 노드에서 문서의 직간접 자식 노드를 선택하게 한다. 이를 통해서 “레벨 건너뛰기” 능력이 부여된다. |
. |
현재 문맥 노드를 선택한다. |
.. |
문맥노드의 부모를 선택한다. |
@ |
문맥 노드의 속성을 선택한다. |
[@attribute = 'value'] |
특정 속성값을 갖는 노드를 선택한다. |
text() |
노드의 텍스트 문맥을 선택한다. |
| | | 파이프 사슬 표현식. 이거 아니면 저것 표현식으로 결과를 가져온다. 합집합 기호로 생각하면 편하다. |
브라우저 콘솔을 사용해서, XPath로 웹페이지 탐색하기
HTML 코들 사용해서 예제로 읽어들인 웹페이지를 기술해보자. 기본디폴트 설정으로, 웹브라우저는 HTML 코드를 해석해서 다양한 문서 요소에 어떤 마크업을 적용할지 결정하는 반면에, 코드는 보이지 않게 된다. 내재된 코드를 볼 수 있도록, 모든 브라우저는 웹페이지 HTML 원 콘텐츠를 표시할 수 있는 함수가 제공된다.
웹페이지 소스 화면에 표시하기
본인이 선호하는 웹브라우저를 사용해서, 해당 페이지 HTML 소스코드를 화면에 표시한다.
팁: 브라우저 대부분, 해야되는 작업은 해당 웹페이지에서 우클릭하고 “View Page Source” 선택옵션을 선택한다. (맥 사바리에서는 “Show Page Source”)
해당 웹페이지를 제작하는데 사용된 원문 HTML이 탭이 새로 생성되면서 열리게 된다. 다양한 HTML 요소를 저정할 수 있는지, 특히
웹페이지 소스 화면에 표시하기박스도 지정 가능한지 확인한다.
맥 사파리 웹브라우저를 사용하는 경우
If you are using Safari, you must first turn on the “Develop” menu in order to view the page source, and use the functions that we will use later in this section. To do so, navigate to Safari > Preferences and in the Advanced tab select the “Show Develop in menu bar” option. Note: In recent versions of Safari you must first turn on the “Develop” menu (in Preferences) and then navigate to
Develop > Show Javascript Consoleand then click on the “Console” tab.
현재 읽고 있는 웹페이지 HTML 구조는 다음과 같다(명확하게 할 수 있도록, 텍스트와 요소 대부분을 제거함):
<!doctype html>
<html lang="en">
<head>
(...)
<title>Xpath를 사용해서 웹페이지 콘텐츠 선택하기</title>
</head>
<body>
(...)
</body>
</html>
소스코드에서 해당 웹페이지 제목은 head 요소 내부 title 요소로 배치된 것을 확인할 수 있다.
head 자체는 html 요소 내부에 위치하고 html은 다시 전체 웹페이지 콘텐츠를 담고 있다.
웹스크핑하는 프로그램이 해당 웹페이지 제목(title)을 찾도록 지시한다고 가정하자.
이러한 정보를 사용해서, 웹스크핑하는 프로그램이 해당 웹페이지 HTML 콘텐츠를 탐색하여 title 요소에 도달하도록
경로(path)를 지정하도록 알고리즘을 설계하고 코딩한다.
XPath를 통해 이 작업이 가정하다.
시장을 지배하는 현세대 웹브라우저에서 XPath 쿼리문을 실행시킬 수 있다. 실행시키는 방법은 내장 자바스크립트 콘솔을 활성화시키면 된다.
웹브라우져에서 콘솔을 표시하는 방법
- 파이어 폭스, Tools > Web Developer > Web Console 메뉴 아이템에서 사용.
- 크롬에서, View > Developer > JavaScript Console 메뉴 아이템에서 사용.
- 사파리에서, Develop > Show Error Console 메뉴 아이템에서 사용. 사파리 웹브라우저에서
Develop메뉴가 없는 경우,Preferences에서 해당 선택옵션을 먼저 활성화시키고 나서 다시 상기 방법을 따라 실행해 본다.
파이어폭스 웹브라우저에서 콘솔을 실행시킨 경우 다음과 같은 화면이 나타난다:

현재시점에서, 콘솔이 열릴 때 있을지 모를 오류 메시지에 대해서 그다지 걱정할 필요는 없다.
콘솔에 프롬프트 > 문자(파이어 폭스는 >>)로 깜빡이는데 명령을 기다리고 있음을 나타낸다.
자바스크립트 콘솔에서 XPath 쿼리를 실행하는 구문은 $x("XPATH_QUERY")와 같다. 예를 들어;
$x("/html/head/title/text()")
다음과 유사한 결과가 출력된다.
<- Array [ #text "Xpath를 사용해서 웹페이지 콘텐츠 선택하기" ]
출력결과는 사용된 브라우저에 따라 다소 차이가 날 수 있다. 예를 들어, 크롬에서 콘텐츠를 보려면 실행된 명령어로 반환된 객체를 “open”해서 열어야 된다.
상기 예제에서 사용된 XPath 쿼리를 좀더 자세히 살펴보자: /html/head/title/text().
첫번째 /은 문서 루트(root)를 나타낸다. 쿼리가 의미하는 바는, 브라워저로 하여금 다음 작업을 수행하도록 한 것이다.
/ |
문서 루트에서 시작하라… |
html/ |
… html 노드로 이동하라 … |
head/ |
… 그리고 head 노드로 가서 내부로 들어가라… |
title/ |
… 그리고 title 노드로 가서 내부로 들어가라… |
text() |
그리고 텍스트 노드를 선택하라. |
상기 구문을 사용해서 XPath는 노드에 대한 정확한 경로를 결정하도록 하는 역할을 수행한다.
“들어가며” 제목 선택하기
XPath 쿼리를 작성해서 “들어가며” 제목을 선택하도록 하고 콘솔에서 직접 실행해본다.
팁: 쿼리 실행결과 다수 요소가 반환되는 경우,
element[1]구문을 사용하면 유용하다. XPath는 1부터 시작하는 인덱스 체계를 갖고 있어서, 첫번째 요소는 인덱스 1, 두번째 요소는 인덱스 2 등…해답
$x("/html/body/div/article/h1[1]")위와 같이 코드를 작성해서 실행하면 다음과 같은 결과를 얻게 된다.
<- Array [ <h1#introduction> ]
XPath를 사용해서 특정 HTML 노드에 도달하는 다른 방법을 살펴보기 전에, 문서 내부에서 노드가 어떻게 배열되고 서로간에 관계는 어떻게 정의되는지 좀더 자세히 살펴보자.
예를 들어, 강의 웹페이지에서 모든 blockquote를 선택하는 경우 다음과 같이 코드를 작성한다.
$x("/html/body/div/article/blockquote")
상기 코드를 실행하면 객체 배열이 만들어진다:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.keypoints> ]
html/body/div 아래 위치한 모든 blockquote 요소가 선택된다.
대신에 웹페이지 문서에서 blockquote 요소를 선택하는자 하는 경우 // 구문을 사용할 수 있다:
$x("//blockquote")
상기 코드를 실행하게 되면 더 긴 객체 배열이 만들어 진다:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.solution>, <blockquote.challenge>, <blockquote.solution>, 3 more… ]
왜 두번째 배열은 더 길이가 길까?
상기
$x("//blockquote")쿼리가 반환하는 배열을 좀더 자세히 살펴보면, 첫번째 쿼리 결과에 포함되지 않은<blockquote.solution>같은 객체가 포함된 것을 알 수 있다. 왜 이럴까?팁: 소스 코드를 보고 도전과제(challenge)와 해답(solution) 요소가 조직된 방식을 살펴본자.
출력결과를 필터링하는데 특정 요소의 class 속성을 사용할 수 있다.
예를 들어, 이전 쿼리에서 반환된 blockquote 요소 리스트와 웹페이지 소스코드를 살펴보면,
blockquote 요소의 클래스(challenge, solution, callout, 등)가 다른 것을 알 수 있다.
challenge 클래스의 blockquote 모든 요소만 얻도록 상기 쿼리를 마사지하면 다음과 같이 코드를 바꿀 수 있다:
$x("//blockquote[@class='challenge']")
상기 코드는 다음과 같은 결과를 반환한다.
Array [ <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge> ]
ID로 “들어가며” 제목 선택하기
이전 도전과제에서, “들어가며” 제목을 선택할 수 있는 이유는 웹페이지에서 첫번째
h1요소라는 사실을 알고 있었기 때문이다. 하지만, 웹페이지에 그런 요소가 얼마나 많은지 모르는 경우는 어떨까? 말을 바꾸어서, 유일무이하게 제목 요소를 식별하는 다른 속성은 존재하는가?앞에서 소개된 경로 표현식(path expression)을 사용해서 XPath 쿼리를 다시 작성해서,
[1]인텍스 표기법을 사용하지 않고 “들어가며” 제목을 선택하도록 해보자.팁:
- 웹페이지 소스코드를 살펴보거나 웹브라우저 “Inspect element” 함수를 사용해서 해당 요소를 유일무이하게 식별하는데 다른 정보를 활용할 수 있는지 살펴본다.
<div id="mytarget">와 같이 요소를 선택하는 구문은div[@id = 'mytarget']와 같이 작성한다.해답
$x("/html/body/div/h1[@id='introduction']")상기 코드 실행결과는 다음 결과를 출력한다.
<- Array [ <h1#introduction> ]
도전과제박스 선택하기웹브라우저 자바스크립트 콘솔에서 XPath 쿼리를 사용해서 현재 읽고 있는 웹페이지에서 텍스트를 담고 있는 요소만 선택하라.
팁:
- 원론적으로 보면, HTML에서
id속성은 해당 페이지에서 겹치지 않는 유일무이한 값이다. 찾고자 하는id요소를 알고 있는 경우, 노드 나무에서 위치한 곳을 전혀 걱정할 필요 없이 XPath를 구성해서 해당 값을 찾을 수 있음을 의미한다.<div id="mytarget">와 같은 요소를 선택하는 XPath 구문은div[@id = 'mytarget']이 된다.- XPath 쿼리는 문맥 노드에 상대적으로 정해지고 기본 디폴트 설정으로 해당 문맥 노드는 루트 노드가 된다.
//구문을 사용해서 찾고자 하는 요소가 나무 어디에 있는지 관계없이 해당 요소를 특정할 수 있다.- 문맥 노드에서 상대적으로 부모 요소를 선택하는 구문은
..이다.- 자바스크립트
$x(...)구문은 쿼리가 반환하는 노드 갯수에 상관없이, 항상 노드 배열을 반환한다. XPath와 달리, 자바스크립트는 0부터 시작하는 인덱스 체계를 갖고 있다. 따라서, 배열의 첫번째 요소를 얻는 구문은$x(...)[0]와 같이 작성하면 된다.전체 도전과제(challenge) 상자를 선택하도록 한다. 작성한 쿼리가 도전과제 제목만 출력하는 경우, 문서 HTML 구조를 다시 살펴보고 전체 도전과제 상자가 선택되도록 “확장”하는 방법을 찾아본다.
해답
웹브라우저에서 (“View Source” 선택옵션을 사용) 도전과제 상자 주변의 HTML 코드를 살펴보자. 다음과 같이 HTML 코드가 보일 것이다:
<!doctype html> <html lang="en"> <head> (...) </head> <body> <div class="container"> (...) <blockquote class="challenge"> <h2 id="select-this-challenge-box">Select this challenge box</h2> <p>Using an XPath query in the JavaScript console of your browser...</p> (...) </blockquote> (...) </div> </body> </html>
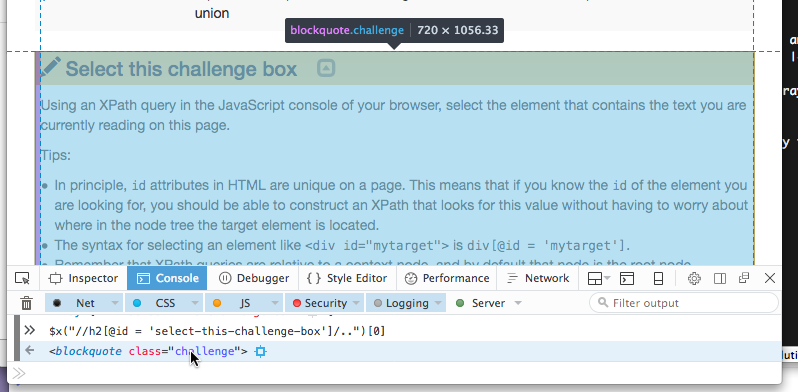
id속성은 겹치지 않고 유일무이해야 되기 때문에, 이런 점을 적극 활용해서 도전과제 상자 내부에h2요소를 선택한다:$x("//h2[@id = 'select-this-challenge-box']/..")[0]상기 코드를 실행하면 다음과 같은 결과가 출력된다.
<- <blockquote class="challenge">이제 작성한 구문 각각을 하나씩 따져보자:
$x("브라우저에 XPath 쿼리를 실행시킨다는 사실을 전달한다. //문서 전체를 검색한다… h2… h2 요소만 찾는다… [@id = 'select-this-challenge-box']… id속성을select-this-challenge-box으로 고정시킨다…..h2 요소의 부모 노드를 선택한다 ")"XPath 쿼리문 종료를 알림. [0]쿼리 실행결과 배열의 첫번째 요소를 선택 ( $x()가 반환하는 노드 배열의 첫번째 요소만 관심이 있기 때문)콘솔에서 XPath 쿼리가 반환한 객체 주변을 맴돌아보면, 웹브라우저가 웹페이지 해당 객체를 하일라이트 하는 것을 알 수 있는데, 이를 통해서 제대로 도전과제 박스가 선택된 것을 확인할 수 있다:
Advanced XPath syntax
FIXME: All the content below is from the original XPath lesson. Adapt content to use current example.
Operators
Operators are used to compare nodes. There are mathematical operators, boolean operators. Operators can give you boolean (true/false values) as a result. Here are some useful ones:
| Operator | Explanation |
|---|---|
= |
Equivalent comparison, can be used for numeric or text values |
!= |
Is not equivalent comparison |
>, >= |
Greater than, greater than or equal to |
<, <= |
Less than, less than or equal to |
or |
Boolean or |
and |
Boolean and |
not |
Boolean not |
Examples
| Path Expression | Expression Result |
|---|---|
| html/body/div/h3/@id=’exercises-2’ | Does exercise 2 exist? |
| html/body/div/h3/@id!=’exercises-4’ | Does exercise 4 not exist? |
| //h1/@id=’references’ or @id=’introduction’ | Is there an h1 references or introduction? |
Predicates
Predicates are used to find a specific node or a node that contains a specific value.
Predicates are always embedded in square brackets, and are meant to provide additional filtering information to bring back nodes. You can filter on a node by using operators or functions.
Examples
| Operator | Explanation |
|---|---|
[1] |
Select the first node |
[last()] |
Select the last node |
[last()-1] |
Select the last but one node (also known as the second last node) |
[position()<3] |
Select the first two nodes, note the first position starts at 1, not = |
[@lang] |
Select nodes that have attribute ‘lang’ |
[@lang='en'] |
Select all the nodes that have a “attribute” attribute with a value of “en” |
[price>15.00] |
Select all nodes that have a price node with a value greater than 15.00 |
Examples
| Path Expression | Expression Result |
|---|---|
| //h1[2] | Select 2nd h1 |
| //h1[@id=’references’ or @id=’introduction’] | Select h1 references or introduction |
Wildcards
XPath wildcards can be used to select unknown XML nodes.
| Wildcard | Description |
|---|---|
* |
Matches any element node |
@* |
Matches any attribute node |
node() |
Matches any node of any kind |
Examples
| Path Expression | Result | //*[@id=”examples-2”] |
|---|---|---|
//*[@class='solution'] |
Select all elements with class attribute ‘solution’ |
In-text search
XPath can do in-text searching using functions and also supports regex with its matches() function. Note: in-text searching is case-sensitive!
| Path Expression | Result |
|---|---|
//author[contains(.,"Matt")] |
Matches on all author nodes, in current node contains Matt (case-sensitive) |
//author[starts-with(.,"G")] |
Matches on all author nodes, in current node starts with G (case-sensitive) |
//author[ends-with(.,"w")] |
Matches on all author nodes, in current node ends with w (case-sensitive) |
//author[matches(.,"Matt.*")] |
regular expressions match 2.0 |
Complete syntax: XPath Axes
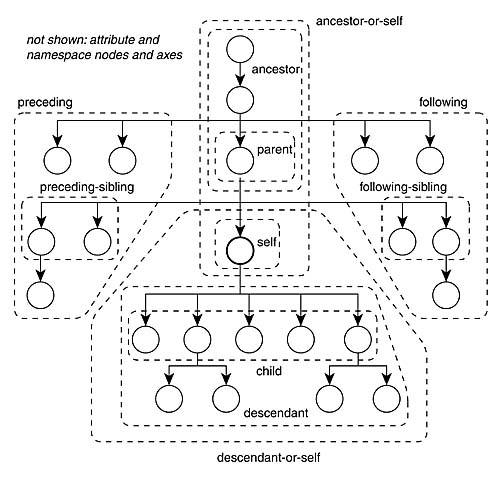
XPath Axes fuller syntax of how to use XPath. Provides all of the different ways to specify the path by describing more fully the relationships between nodes and their connections. The XPath specification describes 13 different axes:
- self ‐‐ the context node itself
- child ‐‐ the children of the context node
- descendant ‐‐ all descendants (children+)
- parent ‐‐ the parent (empty if at the root)
- ancestor ‐‐ all ancestors from the parent to the root
- descendant‐or‐self ‐‐ the union of descendant and self • ancestor‐or‐self ‐‐ the union of ancestor and self
- following‐sibling ‐‐ siblings to the right
- preceding‐sibling ‐‐ siblings to the left
- following ‐‐ all following nodes in the document, excluding descendants
- preceding ‐‐ all preceding nodes in the document, excluding ancestors • attribute ‐‐ the attributes of the context node
| Path Expression | Result |
|---|---|
/html/body/div/h1[@id='introduction']/following-sibling::h1 |
Select all h1 following siblings of the h1 introduction |
/html/body/div/h1[@id='introduction']/following-sibling::* |
Select all h1 following siblings |
//attribute::id |
Select all id attribute nodes |
Oftentimes, the elements we are looking for on a page have no ID attribute or other uniquely identifying features, so the next best thing is to aim for neighboring elements that we can identify more easily and then use node relationships to get from those easy to identify elements to the target elements.
For example, the node tree image above has no uniquely identifying feature like an ID attribute.
However, it is just below the section header “Navigating through the HTML node tree using XPath”.
Looking at the source code of the page, we see that that header is a h2 element with the id
navigating-through-the-html-node-tree-using-xpath.
$x("//h2[@id='navigating-through-the-html-node-tree-using-xpath']/following-sibling::p[2]/img")
Additions
FIXME: add more XPath functions such as concat() and normalize-space().
FIXME: mention XPath Checker for Firefox
FIXME: Firefox sometime cleans up the HTML of a page before displaying it, meaning that the DOM tree
we can access through the console might not reflect the actual source code. <tbody> elements are
typically not reliable.
The Scrapy documentation
has more on the topic.
References
Key Points
XML과 HTML은 마크업 언어로 문서에 구조를 생성시킨다.
XML과 HTML 문서는 노드(node)로 구성되고 노드는 위계(hierarchy)를 형성한다.
문서내부 노드 위계를 노드 나무(node tree)라고 부른다.
XPath 쿼리를 경로(path)로 생성시켜서 노드 나무 위아래로 오르내리게 된다.
$x()함수를 사용해서 브라우저에서 XPath 쿼리를 실행시키다.