들어가며: 웹스크래핑이란 무엇인가?
Overview
Teaching: 10 min
Exercises: 0 minQuestions
웹스크래핑은 무엇이고 왜 유용한가?
웹스크래핑을 사용하는 전형적인 사례(use case)는 무엇인가?
Objectives
구조화가 잘된 데이터 개념을 소개한다
웹페이지에서 데이터를 어떻게 추출할 수 있는지 토론한다
이번 학습에서 사용될 예제를 소개한다
웹스크래핑은 무엇인가?
웹스크래핑(Web Scraping)은 웹사이트에서 정보를 추출하는 기법이다. 데이터 추출작업을 수작업으로도 할 수 있지만, 자동화하게 되면 대체로 더 빠르고, 효율적이고, 오류가 적게 수반된다.
웹스크래핑을 통해서 표형식이 아니거나(non-tabular) 구조화되지 않은 데이터를 유용하고 구조화된 형태로 변환하게 된다.
유용하고 구조화된 데이터 형태로 .csv 혹은 스프레드쉬트를 예로 들 수 있다.
스크래핑 작업을 통해 온라인 화면에 표시된 방식으로는 접근할 수 없는 데이터도 습득할 수 있게 도와준다. 하지만, 스크래핑은 단순히 데이터를 습득하는 것 이상이다: 온라인 데이터 변경사항을 추적하고, 데이터를 아카이브하여 저장하는 것도 도와준다. 요약하면, 배워둘 가치가 있는 기술이다.
웹스크래핑은 웹 인덱싱 작업과 매우 밀접하게 연결되어 있다. 웹인덱싱은 구글같은 검색엔진이 검색 색인을 만드는데 웹을 분석하는 기술을 지칭한다. 웹인덱싱(web indexing)이 일반적으로 웹페이지 전체 콘텐츠를 파싱하여 검색가능하게 만드는 것과 달리, 웹스크래핑(web scraping)은 방문한 웹페이지에서 특정 정보를 목표로만 한다는 점에서 차이가 있다.
예를 들어, 온라인 전자상거래 사업자는 공개된 경쟁사 웹페이지를 샅샅이 뒤져 제품가격을 긁어와서, 긁어온 정보를 사용해서 자사 가격을 조정한다. 또다른 활용사례로 “연락처 정보 스크래핑(contact scraping)”으로 연락처 정보(전자우편 주소, 핸드폰 번호 등)를 마케팅 목적으로 수집하는 것을 꼽을 수 있다.
학계에서도 연구자들이 웹스크래핑을 점점 많이 사용되는데, 저널 논문과 디지털화된 텍스트를 수집하는데 활용되는 텍스트 마이닝 프로젝트가 이에 포함된다. 특히, 데이터 저널리즘(data journalism)에서 탐사전문 기자의 경우 기사화되지 않은 데이터를 모아 분석 가능한 형태로 바꾸어 기사를 작성하는데 필요한 기본기술이 된다.
시작하기 전에 점검사항
스크래핑이 유용한 만큼 더 나은 선택지가 있을 수도 있다. 해당 작업에 올바른(즉, 가장 쉬운) 도구를 선택하라.
- 웹사이트 데이터를 복사해서 붙여넣기해서 엑셀 혹은 구글 쉬트(Google Sheets)로 가져올 수 있는지 확인한다.
- (존재하는 경우) 구조화된 데이터가 존재하는지 찾는다.
- 정보 요청의 자유(Freedom of information requests)를 활용한다. (입수하고자 하는 데이터 형태에 대해 구체적으로 적시하라.)
사례: 연락 주소를 얻고자 정부 웹사이트에서 스크래핑
이번 학습에서 활용할 사례로 의원님이 등재된 선거구 정부 웹사이트에서 연락처 정보를 추출한다. 이런 정보가 유용한 실무적인 이유는 특정 이슈에 대해 시민 대표자인 의원님을 시민이 더욱 쉽게 접촉할 수 있도록 하기 위한 것이다.
현재 캐나다 국회의원 명부를 살펴보는 것부터 시작하자; Parliament of Canada website 웹사이트에서 해당 정보를 살펴볼 수 있다.
2016년 11월 기준 해당 웹페이지를 방문하면 다음과 같이 보인다:
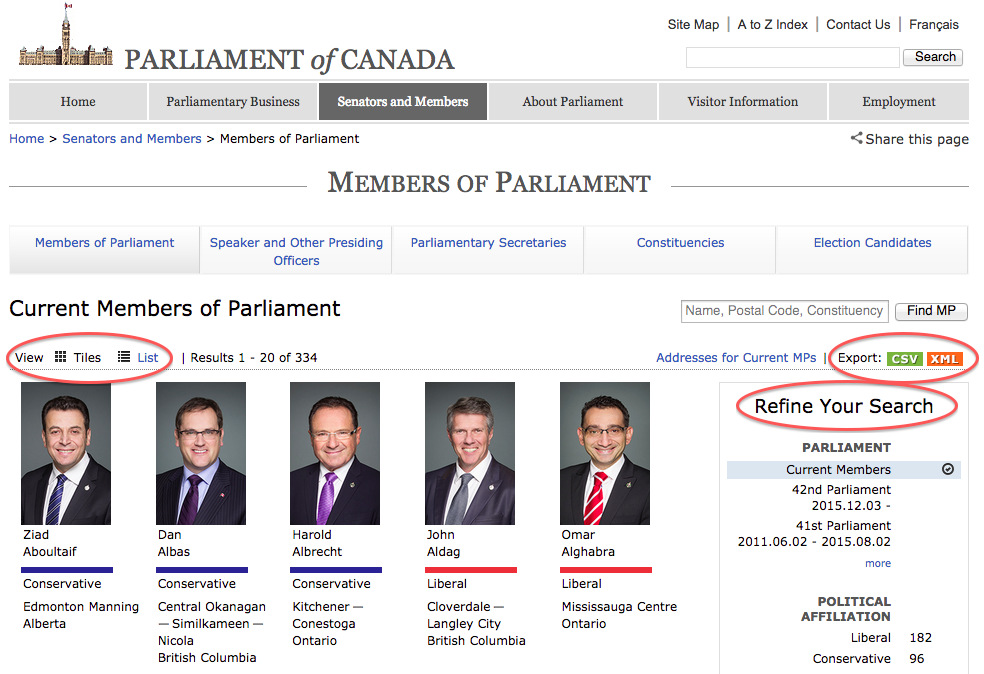
해당 웹페이지에서 작업하기 쉬운 형태로 데이터를 다룰 수 있도록 몇가지 기능(빨간색 원)을 지원한다. 검색, (다시)정렬, 표시 방식과 다양한 다듬기 선택옵션을 통해 데이터가 실제로는 (구조화된) 데이터베이스로 저장되어 있고 이를 사용자 요청에 맞춰 웹페이지에 보여지게 됨을 유추할 수 있다. 해당 원본 데이터는 콤마구분자(CSV) 파일 혹은 XML로 바로 다운로드받을 수도 있다. 이를 통해 누구나 본인 소유 데이터베이스, 스프레드쉬트 혹은 데이터를 활용하는 컴퓨터 프로그램에 올려 활용하는게 가능하다.
화면에 표시되는 정보가 라벨이 붙어있지 않지만, 캐나다 지리와 정치에 대한 지식을 보유하신 분이 웹사이트를 방문하게 되면 정치인 이름, 지역구, 정당이 어떤 정보에 대응되는지 재빨리 파악하게 된다. 이유는 재빨리 정보를 범주화하는데 맥락과 사전 지식을 사용함에 있어 능숙하기 때문이다.
다른 한편으로 추가 정보를 제공하지 않을 경우 사람이 잘 하는 작업을 컴퓨터는 할 수 없다. 다행히, 해당 웹페이지 HTML 소스코드를 보게 되면 화면에 표시되는 정보가 실제로 라벨을 갖는 요소(element)들로 잘 구조화된 것을 볼 수 있다:
(...)
<div>
<a href="/Parliamentarians/en/members/Ziad-Aboultaif(89156)">
<img alt="Photo - Ziad Aboultaif - Click to open the Member of Parliament profile" title="Photo - Ziad Aboultaif - Click to open the Member of Parliament profile" src="http://www.parl.gc.ca/Parliamentarians/Images/OfficialMPPhotos/42/AboultaifZiad_CPC.jpg" class="picture" />
<div class="full-name">
<span class="honorific"><abbr></abbr></span>
<span class="first-name">Ziad</span>
<span class="last-name">Aboultaif</span>
</div>
</a>
<div class="caucus-banner" style="background-color:#002395"></div>
<div class="caucus">Conservative</div>
<div class="constituency">Edmonton Manning</div>
<div class="province">Alberta</div>
</div>
(...)
이러한 라벨 덕분에, 상대적으로 수월하게 앨버타주 모든 국회의원에 대한 정보(의원명과 정당 등)를 컴퓨터로 하여금 검색할 수 있게 된다.
구조화된 데이터 vs. 비구조화된 데이터
When presented with information, human beings are good at quickly categorizing it and extracting the data that they are interested in. For example, when we look at a magazine rack, provided the titles are written in a script that we are able to read, we can rapidly figure out the titles of the magazines, the stories they contain, the language they are written in, etc. and we can probably also easily organize them by topic, recognize those that are aimed at children, or even whether they lean toward a particular end of the political spectrum. Computers have a much harder time making sense of such unstructured data unless we specifically tell them what elements data is made of, for example by adding labels such as this is the title of this magazine or this is a magazine about food. Data in which individual elements are separated and labelled is said to be structured.
영국하원(UK House of Commons) 의회 현직 의원을 살펴보자.
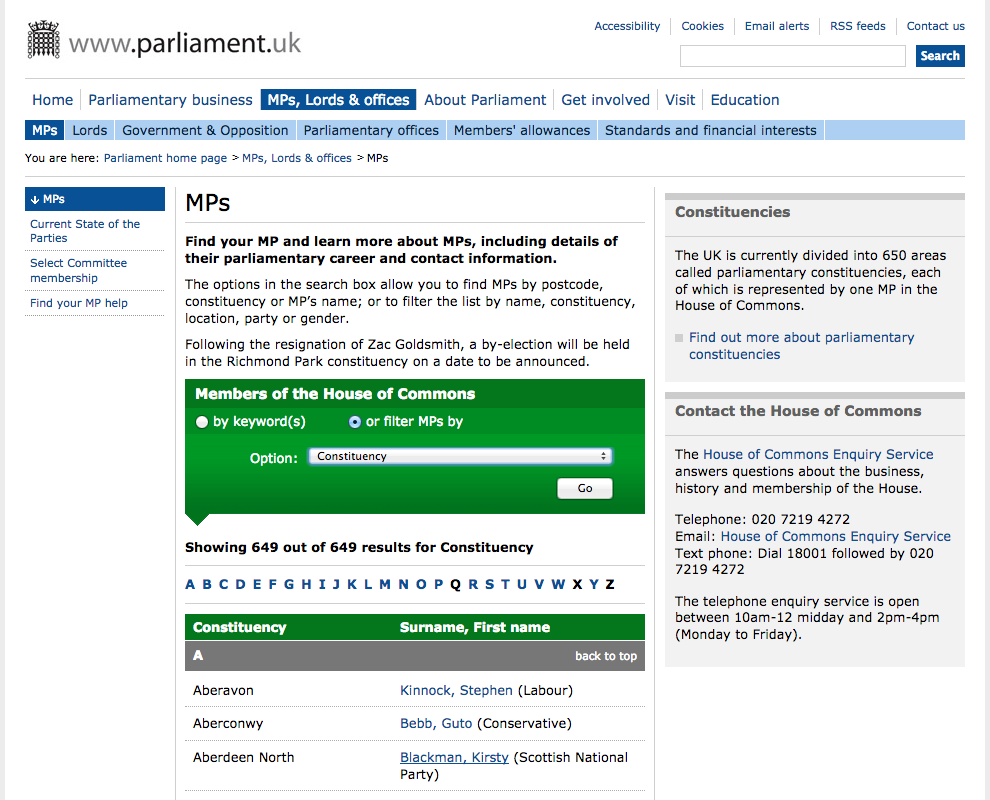
해당 페이지도 의원명, 정당, 지역정보를 보여주고 있다. 검색상자, 필터 선택옵션지를 제공하지만, 해당 정보를 다운로드 받거나 재사용한느 명백한 방식을 제시하고 있지는 않다.
아래에 해당 페이지에 대한 코드가 나와 있다:
(...)
<table>
<tbody>
(...)
<tr id="ctl00_ctl00_(...)_trItemRow" class="first">
<td>Aberavon</td>
<td id="ctl00_ctl00_(...)_tdNameCellRight">
<a id="ctl00_ctl00_(...)_hypName" href="http://www.parliament.uk/biographies/commons/stephen-kinnock/4359">Kinnock, Stephen</a>(Labour)
</td>
</tr>
(...)
</tbody>
</table>
(...)
이를 통해서 데이터는 화면표시 목적(테이블 내부 행기준으로 정렬됨)으로 구조화되었다는 것을 확인할 수 있다. 해당 정보 다른 요소는 명시적으로 라벨이 붙은 것도 아니라는 것을 알 수 있다.
예를 들어 의원성비 혹은 두 집단간 정치적 영향력을 관점에서
캐나다와 영국을 비교하자, 데이터셋으로 다운로드하고자 한다면 어떨까?
전체 테이블을 스프레드쉬트 혹은 수작업으로 해당 웹페이지에서 의원명과
정당을 복사-붙여넣기 신공으로 작업할 수는 있다.
하지만, 이런 접근법은 데이터가 많아지면 곧 비현실적 접근법이 된다.
예를 들어, 의회 시스템을 갖고 있는 모든 국가에 대해서 해당 정보를 수집하는 경우를 상정해보자.
다행스럽게도 적어도 일부분을 자동화할 수 있는 도구가 있다. 이런 기법을 웹스크래핑이라고 부른다.
“웹스크래핑은 웹사이트에서 정보를 추출하는데 동원되는 컴퓨터 소프트웨어 기술이다.” “Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites.” (출처: Wikipedia)
웹스크래핑은 웹 인덱싱 작업과 매우 밀접하게 연결되어 있는데, 웹인덱싱은 구글같은 검색엔진이 유저가 검색할 때 쿼리하는 데이터베이스를 제작하는 기술이다. 차이점은 웹인덱싱(“봇” 혹은 “크롤러”라고 불리는 도구를 활용)이 모든 웹사이트의 링크를 따라 재귀적으로 방문하여, 데이터를 색인하고, 작업결과를 데이터베이스에 저장하는 작업을 주기적으로 수행하여 항상 색인이 최신화되도록 하는 것을 목표로한다.
이와는 달리 웹스크래핑은 좀더 선택과 집중한 기술로, 일반적으로 한번에 한 웹사이트를 목표로 해서 구조화되지 않는 정보를 추출하여 이를 재사용이 가능한 구조화된 형태로 변환시키는 것을 주된 작업으로 삼는다.
이번 학습을 통해서, 상기 예제를 계속 다루는데 정보를 추출하는데 다른 기법을 사용한다. 하지만, 웹스크래핑에 착수하기에 앞서, HTML 문서에 정보가 구조화된 방식을 좀더 깊게 살펴보고 해당 정보를 추출하는 쿼리를 작성하는 방식도 살펴볼 것이다.
참고문헌
Key Points
사람은 정보를 범주화하는데 능하지만, 컴퓨터는 그다지 잘하지 못한다.
흔히, 웹사이트에 올려진 데이터는 적절히 구조화되지 못한 경우가 다반사라 추출하기가 그다지 녹록하지 않다.
웹스크래핑은 웹사이트에서 데이터 추출작업을 자동화하는 과정으로 정의된다.