밑바탕 토대
Overview
Teaching: 45 min
Exercises: 0 minQuestions
도서관과 관련된 프로그램을 성공적으로 생성하고 사용하는데 필요한 일반적인 기술과 좋은 관례는 어떤 것이 있을까요?
Objectives
소프트웨어와 데이터를 사용하는데 좋은 관례(best practice)를 식별한다.
파일을 저장하는데 좋은 관례(best practice)를 식별한다.
파일명을 짓는데 좋은 관례(best practice)를 식별한다.
밑바탕 토대
컴퓨팅 도구를 자유자재로 사용하기 전에, 시간 일부를 투여해서 라이브러리 카펜트리(library carpentry)에서 마주할 것에 도움이 되는 밑바탕 토대를 살펴본다. 본인 작업에 컴퓨팅 접근법을 도입할 때 알아두면 유용한 몇가지 원칙과 행동을 다루게 된다.
컴퓨터는 멍청하다.
자명한 사실로 정말 컴퓨터는 멍청하다. 영어로 The computer is stupid. 하지만, 컴퓨터는 유용하기도 하다. 반복 작업(repetitive task), 쭉 열거된 작업(enumerative task), 기억에 의존하는 작업이 주어졌을 때, 마지못해 억지로 작업을 수행하는 사람보다 컴퓨터는 훨씬 더 빨리, 더 정확하게 작업을 수행한다. 컴퓨터는 컴퓨터가 지시받는 바만 정확하게 수행한다. 오류가 발생하면 잘못은 바로 작업을 내린 당신이다. 즉, 당신 머리속에 버그가 있는 것이다. 대부분의 경우 컴퓨터가 의도한 바를 잘못 이해하는 경우가 있는데 이유는 컴퓨터는 원래 자신이 아는 한도내에서 동작하기 때문이다.
자동화 즉 컴퓨팅 접근법을 취하는 이유는 뭘까?
다른 말로 바꾸게 되면, “수작업으로 못 할 이유는 뭘까?”라는 질문과 같다. 문제에 대해서 수작업이 훨씬 더 쉽고, 빠르고, 가장 효율적인 접근법이 되는 경우도 무척이나 많다. 자동화(automation), 즉 컴퓨팅 접근법(computational approach)을 고려해야되는 조건 두가지는 다음과 같다:
- 본인이 작업 자동화 방법을 알고 있는 경우.
- 본인이 알기로 본인이 반복해서 계속해야 되는 작업인 경우.
주요 수업내용:
- 빌리고, 빌리고, 또 빌려라.. 전문직업 프로그래머부터 도서관에서 코딩하는 우리와 같은 일반인 모두에게 공통되는 프로그래밍의 중심;
- 배워야 되는 적합한 언어는 본인 작업 맥락에서 동작하는 것이다. 진정한 최고 언어는 없고 단지 서로 다른 장점과 단점을 갖는 언어만 있을 뿐이다. 하지만, 프로그래밍 언어 모두는 동일한 토대가 되는 원칙은 채택하고 있다;
- 전문개발 측면에서 프로그래밍의 역할을 고려하라. 컴퓨팅 기술은 효율성과 함께 효과성도 증진시킨다. 학습하고자 하는 기술에 집중하고 함께하는 직원들이 어떤 기술을 습득하는지도 숙지한다;
- 코드를 (조금이라도) 알게되면 코드를 사용하는 프로젝트를 평가하는데 도움이 된다. 프로그래밍이 외계인처럼 보일 수 있지만, 코드를 알게 되면 소프트웨어 개발 품질을 판단하고 소프트웨어 개발이 포함된 활동을 계획하는데 도움을 줄 수 있다;
- 다른 무언가를 할 수 있도록 시간을 벌 수 있도록 자동화하라! 시간을 들여서라도 한 곳에 모아라. 가장 단순한 프로그래밍 기술도 더 흥미진지한 작업을 수행하는데 상당한 시간을 절약해 줄 수 있다!(더 흥미로운 작업은 더 많은 프로그래밍 기술을 학습할지라도 …)
왜 자동화하는가?
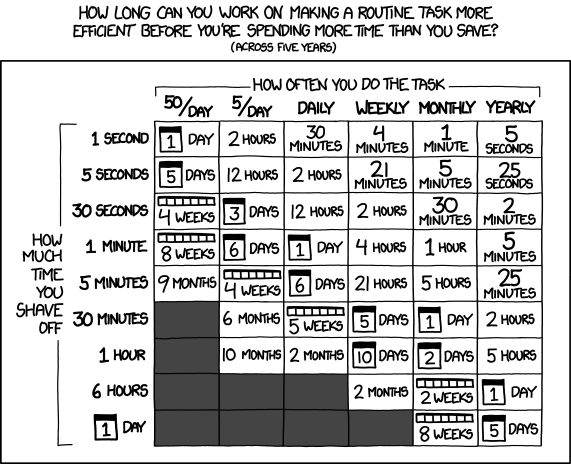
상기 표를 읽는 방법은 다음과 같다. 1
- 1주에 한번씩 5년 작업하한다면 260번 작업을 수행: 1년 52주 곱하기 5년 = 260
- 260 횟수 × 1 분 = 260분 = 4.3 시간
Randall Munroe가 저작한 ‘그럴만한 가치가 있나(Is it worth the time)?’, CC-BY-NC 2.5 라이선스 https://xkcd.com/1205/.
자동화의 두얼굴
- Explain xkcd - 1319: Automation
- “automating” translates to self-screwing (“screwing yourself over”, giving yourself a hard time)

- Explain xkcd - 974: The General Problem
- Put simply, the comic draws attention to the fact that humans are very adept at things that can be difficult to teach machines. We learn as children how to pass arbitrary things to someone who asks. However, to design a ‘system’ to do this, can be quite difficult - dealing with recognition, shape, size, temperature, etc. There is an engineering joke here that novices often attempt to solve general systems problems that seem trivial at first sight, but can end up taking years to solve. The superficial joke is that a human would have to think at all to do this, let alone 20 minutes.

키보드 단축키가 여러분의 친구입니다.
프로그래밍 과정을 통해 더 많은 컴퓨팅 기술을 얻게 되지만, 매우 단순한 키보드 단축키부터 차분히 시작한다. 여러분 모두 호불호를 명확한 단축키 사용법을 익혀서 노동력을 절약하기도 하지만 멍청한 컴퓨터를 가장 최선의 방식으로 활용하게도 하는 역할을 한다. 키보드 단축키 없이도 도서관 카펜트리 모든 학습을 수행할 수 있지만 단축키는 참 많이 활용될 것이 분명하다.
| 동작 | 윈도우 | 맥 | + 키보드 누름(Keystroke) |
|---|---|---|---|
| 저장(Save) | Ctrl | Command | + S |
| 복사(Copy) | Ctrl | Command | + C |
| 잘라내기(Cut) | Ctrl | Command | + X |
| 붙여넣기(Paste) | Ctrl | Command | + V |
| 응용프로그램 바꿈(Switch Applications) | Alt | Command | Tab |
일반 텍스트 파일형식도 여러분 친구입니다.
왜냐구요? 컴퓨터가 텍스트를 처리할 수 있기 때문입니다!
컴퓨터로 본인 작업을 처리하게 하려면,
일반 평문 텍스트의 경우 .txt, 콤마 구분자 .csv, 탭 구분자 .tsv 표형식 데이터의 경우처럼 플랫폼에 구애받지 않는 것을 사용하도록 습관을 들여라.
TSV와 CSV 파일 모두 스프레드쉬트 형식이다. 이러한 일반 평문 텍스트 형식이 상용형식(예를 들면 마이크로소프트 워트)보다 선호되는 이유는
대다수 소프트웨어 팩키지에서 열어 볼 수 있고, 향후 계속해서 열어 볼수도 있고 편집도 가능하기 때문이다.
대부분의 표준 오피스 제품에는 .txt, .csv, .tsv 파일형식으로 파일을 저장할 수 있는 선택옵션을 포함하고 있습니다.
이것이 의미하는 바는 친숙한 소프트웨어로 계속해서 작업할 수 있음을 의미한다.
.doc 혹은 .xls와 비교하여 기계판독 가능한 요소만 포함하고 있다는 부가적인 좋은 점도 있다.
자동화 즉, 컴퓨팅 목적으로 파일작업을 수행할 때, 멋짓 외양보다는 유의미한 데이터 전송에 집중하는 것이 더 중요하다.
굵은 글씨, 이탤릭, 색상을 주어 제목을 돋보이게 하거나 데이터 요소간에 시각적 연결을 만들 수 있지만, 이러한 표시지향 표식은 쉽게
기계판독이 되지 않아서 쿼리하거나 검색이 되지 않아서 대량의 정보로는 부적절하다.
한가지 경험 법칙은 F/Command+F으로 찾을 수 없으면 기계판독은 되지 않는 것으로 간주된다.
별표(*) 두개 혹은 해쉬(#) 3개를 사용해서 데이터 기능을 표현하는 단순한 표기법이 더 선호된다;
예를 들어, 의문부호 3개를 사용해서 추적할 무언가를 나타내는 경우가 있다. 왜 ???을 골랐나면 Ctrl+F/Command+F으로 쉽게 검색할 수 있기 때문이다.
외양을 꾸미는데(formatting) 기계판독이 가능한 평문 텍스트 표기법을 사용한다.
평문 텍스트이면서 기계 판독이 가능하면서도 단순한 외양 꾸미는데 사용될 수 있는 간단한 표기법이 몇개 존재한다.
대표적인 표기법이 마크다운(markdown)으로, 일종의 가벼운 마크업 언어(lightweight markup language)다.
마크업 언어는 메타데이터(metadata) 언어로 콘텐츠와 콘텐츠 외양을 꾸미는 것을 구분하는데 표기법(notation)을 사용한다.
마크다운 파일은 확장자로 .md를 사용하는데 기계판독이 가능하고 사람도 읽을 수 있어서 다양하게 활용된다.
예를 들어 GitHub은 마크다운으로 텍스트를 생성시킨다.
GitHub 마크다운 컨닝쪽지(cheat sheet)를 사용해서 기존 스키마를 따라서 사용할 수도 있고 변형해서 사용하는 것도 가능하다.
평문 텍스트 파일을 작성하고 불러 읽어 들이고 출력하는데 적합한 응용프로그램
윈도우 사용자의 경우 Notepad++ http://notepad-plus-plus.org/를 추천한다. 맥이나 유닉스/리눅스 사용자는 Komodo Edit, Text Wrangler, Kate, Atom 편집기가 도움이 될 수 있다. pandoc과 결합해서 마크다운 파일을 PDF, HTML, 워드 문서, LaTeX 혹은 다른 포맷파일로 내보내기 할 수도 있다. 다양한 방식으로 다른 목적에 맞도록 변경시킬 수 있으며, 기계판독이 가능하고 쉽게 검색가능한 문서를 생성하는 것은 정말로 좋다. Programming Historian tutorial을 참조하면 마크다운으로 저작하고 다양한 목적에 맞춰 문서를 변경시킬 수 있는 방법이 자세히 기술되어 있다.
파일명을 잘 생각해서 짓는 것은 본인 자신과 컴퓨터 모두에게 유익하다.
데이터로 작업할 때 파일을 일관되고 예측가능한 형태로 구성하면 삶이 편안해진다. 구조화된 정보가 없게 되면 삶의 질이 현격히 떨어진다. 도서관과 기록보관소(archive) 직업을 갖는 누구나 이런 사실을 잘 알고 있다. 하지만, 이점에 대해서 좀더 집고 넘어가자. 왜냐하면 데이터로 작업할 때 특히 중요하기 때문이다.
URL을 자세히 살펴보면 데이터를 일관되고 예측가능한 방식으로 구조화하는 것이 본인 작업에도 유용한지 생각해볼 수 있는 좋은 사례가 된다. 훌륭한 URL은 식별하고자 하는 웹페이지 콘텐트를 확실히 나타낸다. 의미론적 요소(semantic element)를 담아내거나 혹은 웹페이지 전반에 걸쳐 파악되는 단일 데이터 요소(data element)를 사용하는 방식을 취한다.
앞선 좋은 사례로 뉴스 웹사이트 혹은 블로그 서비스에서 사용되는 URL을 들 수 있다. 워드프레스 URL은 다음 포맷을 따르고 있다:
ROOT/YYYY/MM/DD/words-of-title-separated-by-hyphens- http://cradledincaricature.com/2015/07/24/code-control-and-making-the-argument-in-the-humanities/
가디언(The Guardian) 신문사와 같은 언론사도 유사한 스타일을 사용한다:
ROOT/SUB_ROOT/YYYY/MMM/DD/words-describing-content-separated-by-hyphens- http://www.theguardian.com/uk-news/2014/feb/20/rebekah-brooks-rupert-murdoch-phone-hacking-trial
데이터 저장소에 단일 데이터 요소로 URL을 구성하는 경우도 흔히 존재한다. 국립 호주 도서관 TROVE도 이런 포맷을 사용한다:
ROOT/record-type/REF- http://trove.nla.gov.au/work/6315568
Old Bailey Online은 다음 포맷을 사용한다:
ROOT/browse.jsp?ref=REF- http://www.oldbaileyonline.org/browse.jsp?ref=OA16780417
상기 예제를 통해서 터득한 사실은 의미론적 기술과 데이터 요소를 조합하게 되면 사람이나 기계 모두 판독이 가능한 자료구조를 일관되고 예측가능하게 만들어낼 수 있다는 점이다. 이런 유형의 패턴을 본인 파일로 이관시키면 운영체제와 도서관 카펜트리에서 다루게 되는 고급 도구를 활용해서 훑어보고(browser), 검색(search), 쿼리(query)가 한결 수월하게 된다.
실무에서 훌륭한 기록 저장소 구조는 다음과 같이 생겼다:
- 루트 기준 디렉토리, 아마도
work. - ‘events’, ‘data’, ‘ projects’와 같은 하위 디렉토리.
- 상기 디렉토리 내부에 각 ‘events’, ‘data’, ‘ projects’ 디렉토리. 날짜 요소를 포함하는 명명규칙을 도입하게 되면 하위 디렉토리(예를 들어 년, 월)없이 정보를 조직적으로 관리할 수 있게 된다.
상기 작업 모두는 나중에 다시 돌아와서 다시 작업할 때 본인이 과거 작업한 것을 잘 기억할 수 있도록 도움이 된다.
(이것을 real world preservation이라고 부른다.)
하지만, 우리가 당면한 목적을 생각하면 가장 중요한 비트는 아마도 파일명 짓는 규칙이 될 듯 싶다. 파일명을 통해 앞서 학습한 것을 확실하게 해서 파일에 담긴 콘텐츠를 식별하기 쉽게 한다. ‘Data.xslx’는 이런 목적에 부합하지 않는다. 데이터를 기술하는 제목은 이런 목적에 부합된다. 즉, 이해를 돕고자 파일명에 날짜 규칙을 추가하고, 파일명을 통해 기초 데이터와 관련된 파생 데이터를 연관시키고, 디렉토리 구조를 사용하는 일련의 작업은 이러한 연관성을 강화시키는 역할을 한다.
추가 읽을 거리
미국 도서관사서 Andromeda Yelton은 Code4Lib 운동에 깊숙이 관여하면서 “Coding for Librarians: Learning by Example.”로 불리는 American Library Association Library Technology 보고서에 많은 내용을 담아냈다. 본인 일과 다른 동료 일, 더 나아가 도서관 일에 차별점을 둘 수 있도록 도서관 전문가가 코드를 개발하고 공유하는 다양한 시나리오가 보고서 책자에 담겨있다.
Key Points
자료구조는 일관성과 함께 예측가능해야 된다.
데이터 디렉토리에 데이터 식별자 혹은 의미론적 요소(semantic element)를 적극 사용하는 것을 고려한다.
본인 작업에 적합하도록 자료 구조를 맞추고 조정한다.
파일과 디렉토리를 식별하도록 작명 규칙(naming conventions)을 적용시켜 데이터 요소간에 연관관계를 생성함으로써 장기적으로 자료 구조에 대한 이해와 가독성을 높인다.