1 워드 임베딩(Word Embedding)으로 여정1
1.1 데이터셋
우리로 치자면 소비자 보호원 격인 Consumer Financial Protection Bureau, “Consumer Complaint Database” 웹사이트에 등록된 고객 불만접수가 데이터베이스로 제공되고 있다. .csv파일로 잘 정제가 되어있어 이를 다운로드 받아 살펴보자. 압축을 풀면 1GB정도로 다소 데이터크기가 크다.
library(tidyverse)
library(tidytext)
## 데이터셋: 소비자 불만
complaints <- read_csv("data/complaints.csv")
glimpse(complaints)Rows: 1,670,229
Columns: 18
$ `Date received` <date> 2019-09-24, 2019-09-19, 2019-10-25,...
$ Product <chr> "Debt collection", "Credit reporting...
$ `Sub-product` <chr> "I do not know", "Credit reporting",...
$ Issue <chr> "Attempts to collect debt not owed",...
$ `Sub-issue` <chr> "Debt is not yours", "Information be...
$ `Consumer complaint narrative` <chr> "transworld systems inc. \nis trying...
$ `Company public response` <chr> NA, "Company has responded to the co...
$ Company <chr> "TRANSWORLD SYSTEMS INC", "Experian ...
$ State <chr> "FL", "PA", "CA", "NC", "FL", "CA", ...
$ `ZIP code` <chr> "335XX", "15206", "937XX", "275XX", ...
$ Tags <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, ...
$ `Consumer consent provided?` <chr> "Consent provided", "Consent not pro...
$ `Submitted via` <chr> "Web", "Web", "Web", "Web", "Web", "...
$ `Date sent to company` <date> 2019-09-24, 2019-09-20, 2019-10-25,...
$ `Company response to consumer` <chr> "Closed with explanation", "Closed w...
$ `Timely response?` <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "...
$ `Consumer disputed?` <chr> "N/A", "N/A", "N/A", "N/A", "N/A", "...
$ `Complaint ID` <dbl> 3384392, 3379500, 3417821, 3433198, ...데이터가 크다보니 10% 표본만을 대상으로 작업을 속도감있게 진행하고 중요하다고 생각되는 변수만 우선적으로 추출하여 후속작업을 진행한다.
set.seed(777)
complaints_dat <- complaints %>%
janitor::clean_names() %>%
select(complaint_id, consumer_complaint_narrative, product, company, date_received) %>%
sample_frac(0.1) %>%
drop_na()
complaints_dat# A tibble: 56,238 x 5
complaint_id consumer_complaint_nar~ product company date_received
<dbl> <chr> <chr> <chr> <date>
1 2963530 "I submitted to XXXX X~ Debt collection ENCORE CA~ 2018-07-15
2 2798574 "XX/XX/2018 Good Morni~ Credit reporti~ Experian ~ 2018-01-31
3 2978622 "In mid XXXX I receive~ Debt collection JH Portfo~ 2018-07-31
4 3242435 "I accidentally made a~ Money transfer~ Square In~ 2019-05-14
5 1935767 "XXXX XXXX XXXX XXXX X~ Mortgage Ocwen Fin~ 2016-05-21
6 2701621 "Equifax data breach" Credit reporti~ EQUIFAX, ~ 2017-10-14
7 3597225 "The problem is still ~ Mortgage Ocwen Fin~ 2020-04-08
8 2717071 "XXXX XXXX XXXX XXXX X~ Debt collection ENOVA INT~ 2017-10-31
9 2955102 "In XX/XX/XXXX, I co-s~ Credit reporti~ Experian ~ 2018-07-09
10 2589622 "I have paid membershi~ Credit reporti~ TRANSUNIO~ 2017-07-30
# ... with 56,228 more rows1.2 텍스트도 데이터다!
텍스트는 과거 통계학에서 다루는 영역은 아니었으나, 데이터 과학으로 영역을 확대하여 텍스트도 당연히 데이터로 다뤄지게 되었다. 고객불만 텍스트가 상당히 긴 경우가 있으니 str_trunc() 함수로 100자까지로 한정시켜 보자.
complaints_dat %>%
sample_n(5) %>%
mutate(complain_text = str_trunc(consumer_complaint_narrative, 100, side = "left")) %>%
pull(complain_text)[1] "...ervicer. Filing complaints is the only way to get them to fix their errors. They should be fined."
[2] "...ou when I received my statements. My only thought is that my monthly statement did not get to me."
[3] "... impact my current refinance attempt likely increasing the interest rate and lots of wasted time."
[4] "...nced Recovery Corporation has filed information on my credit report for a debt that I do not owe."
[5] "...tomotive XXXX XXXX Inquiry from XX/XX/XXXXAutomotive XXXX XXXX Inquiry from XX/XX/XXXX Automotive"1.3 텍스트 → 데이터프레임
고객 불만에 대한 텍스트를 데이터프레임으로 변환시킨다. 이를 위해서 토큰화를 하고 영어의 경우 불용어(stopwords)를 제거하고 wordStem() 함수를 사용해서 어근(stem)만 추출하고 이를 Document-Feature Matrix(DFM)을 만들어서 후속 분석작업을 수행한다.
library(SnowballC)
library(quanteda)
library(stopwords)
complaints_df <- complaints_dat %>%
unnest_tokens(word, consumer_complaint_narrative) %>%
anti_join(get_stopwords()) %>%
mutate(stem = wordStem(word)) %>%
count(complaint_id, stem) %>%
bind_tf_idf(stem, complaint_id, n) %>%
cast_dfm(complaint_id, stem, tf_idf)
complaints_dfDocument-feature matrix of: 56,238 documents, 34,960 features (99.8% sparse).
features
docs 1.5 14 21 28000.00 29000.00 300.00
1290303 NA 0.03657928 0.01294926 0.01532234 0.01873811 0.01987131 0.0118709
1290520 0 0 0 0 0 0 0
1290617 0 0 0 0 0 0 0.1062728
1290686 0 0 0 0 0 0 0
1290765 0 0 0 0 0 0 0
1290851 0 0 0 0 0 0 0
features
docs 32000.00 37000.00 85000.00
1290303 0.01828964 0.02063642 0.02140153
1290520 0 0 0
1290617 0 0 0
1290686 0 0 0
1290765 0 0 0
1290851 0 0 0
[ reached max_ndoc ... 56,232 more documents, reached max_nfeat ... 34,950 more features ]2 워드 임베딩2
인접한 단어를 통해 상당히 많은 정보를 얻을 수 있게 된다. 사실 한국어는 다소 차이가 있을 수 있지만, 영어의 경우는 John Rupert Firth의 문장을 인용할 수 있고, 이를 50년도 지나 구현한 것이 워드 임베딩 모형이라고 볼 수 있다. 한국어도 유사한 의미를 갖는 단어는 문서에서 근처에 존재할 것이라는 가정은 나름 합리적으로 받아들일 수 있다.
You shall know a word by the company it keeps.
- John Rupert Firth
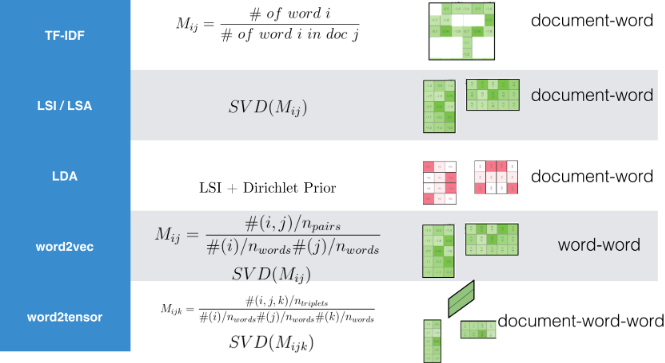
무거운 딥러닝 Word2Vec 대신 로컬 컴퓨터로 간단히 구현할 수 있는 알고리즘이 존재한다. 다소 차이는 있을지 모르지만 현업에서 사용하는데는 크게 무리가 없을 듯 싶다.
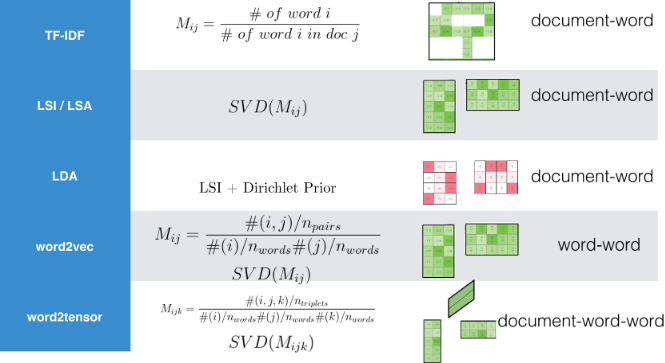
3 Pre-trained 워드 임베딩
사전 훈련된 워드 임베딩(Pre-trained Word-Embedding) 모형은 학습시킬 충분한 데이터가 없는 경우 유용하게 사용될 수 있다.
textdata 팩키지를 통해서 텍스트 관련 데이터를 라이선스 걱정(?)없이 동의과정을 거쳐 수월하게 작업을 진행할 수 있다. textdata 팩키지를 통해 얻을 수 있는 Pre-trained 모형을 살펴보자.
library(rvest)
read_html("https://github.com/EmilHvitfeldt/textdata") %>%
html_nodes(css = "#readme > div.Box-body.px-5.pb-5 > article > table") %>%
html_table() %>%
.[[1]] %>%
knitr::kable()| Dataset | Function |
|---|---|
| v1.0 sentence polarity dataset | dataset_sentence_polarity() |
| AFINN-111 sentiment lexicon | lexicon_afinn() |
| Hu and Liu’s opinion lexicon | lexicon_bing() |
| NRC word-emotion association lexicon | lexicon_nrc() |
| NRC Emotion Intensity Lexicon | lexicon_nrc_eil() |
| The NRC Valence, Arousal, and Dominance Lexicon | lexicon_nrc_vad() |
| Loughran and McDonald’s opinion lexicon for financial documents | lexicon_loughran() |
| AG’s News | dataset_ag_news() |
| DBpedia ontology | dataset_dbpedia() |
| Trec-6 and Trec-50 | dataset_trec() |
| IMDb Large Movie Review Dataset | dataset_imdb() |
| Stanford NLP GloVe pre-trained word vectors | embedding_glove6b() |
| embedding_glove27b() | |
| embedding_glove42b() | |
| embedding_glove840b() |
embedding_glove6b() 함수를 사용해서 단어를 100차원으로 축소해서 살펴보자.
# A tibble: 400,000 x 101
token d1 d2 d3 d4 d5 d6 d7 d8 d9
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 "the" -0.0382 -0.245 0.728 -0.400 0.0832 0.0440 -0.391 0.334 -0.575
2 "," -0.108 0.111 0.598 -0.544 0.674 0.107 0.0389 0.355 0.0635
3 "." -0.340 0.209 0.463 -0.648 -0.384 0.0380 0.171 0.160 0.466
4 "of" -0.153 -0.243 0.898 0.170 0.535 0.488 -0.588 -0.180 -1.36
5 "to" -0.190 0.0500 0.191 -0.0492 -0.0897 0.210 -0.550 0.0984 -0.201
6 "and" -0.0720 0.231 0.0237 -0.506 0.339 0.196 -0.329 0.184 -0.181
7 "in" 0.0857 -0.222 0.166 0.134 0.382 0.354 0.0129 0.225 -0.438
8 "a" -0.271 0.0440 -0.0203 -0.174 0.644 0.712 0.355 0.471 -0.296
9 "\"" -0.305 -0.236 0.176 -0.729 -0.283 -0.256 0.266 0.0253 -0.0748
10 "'s" 0.589 -0.202 0.735 -0.683 -0.197 -0.180 -0.392 0.342 -0.606
# ... with 399,990 more rows, and 91 more variables: d10 <dbl>, d11 <dbl>,
# d12 <dbl>, d13 <dbl>, d14 <dbl>, d15 <dbl>, d16 <dbl>, d17 <dbl>,
# d18 <dbl>, d19 <dbl>, d20 <dbl>, d21 <dbl>, d22 <dbl>, d23 <dbl>,
# d24 <dbl>, d25 <dbl>, d26 <dbl>, d27 <dbl>, d28 <dbl>, d29 <dbl>,
# d30 <dbl>, d31 <dbl>, d32 <dbl>, d33 <dbl>, d34 <dbl>, d35 <dbl>,
# d36 <dbl>, d37 <dbl>, d38 <dbl>, d39 <dbl>, d40 <dbl>, d41 <dbl>,
# d42 <dbl>, d43 <dbl>, d44 <dbl>, d45 <dbl>, d46 <dbl>, d47 <dbl>,
# d48 <dbl>, d49 <dbl>, d50 <dbl>, d51 <dbl>, d52 <dbl>, d53 <dbl>,
# d54 <dbl>, d55 <dbl>, d56 <dbl>, d57 <dbl>, d58 <dbl>, d59 <dbl>,
# d60 <dbl>, d61 <dbl>, d62 <dbl>, d63 <dbl>, d64 <dbl>, d65 <dbl>,
# d66 <dbl>, d67 <dbl>, d68 <dbl>, d69 <dbl>, d70 <dbl>, d71 <dbl>,
# d72 <dbl>, d73 <dbl>, d74 <dbl>, d75 <dbl>, d76 <dbl>, d77 <dbl>,
# d78 <dbl>, d79 <dbl>, d80 <dbl>, d81 <dbl>, d82 <dbl>, d83 <dbl>,
# d84 <dbl>, d85 <dbl>, d86 <dbl>, d87 <dbl>, d88 <dbl>, d89 <dbl>,
# d90 <dbl>, d91 <dbl>, d92 <dbl>, d93 <dbl>, d94 <dbl>, d95 <dbl>,
# d96 <dbl>, d97 <dbl>, d98 <dbl>, d99 <dbl>, d100 <dbl>단어-차원(100) 행렬을 깔끔한 데이터프레임형태로 정리한다.
tidy_glove <- glove6b %>%
pivot_longer(contains("d"),
names_to = "dimension") %>%
rename(item1 = token)
tidy_glove# A tibble: 40,000,000 x 3
item1 dimension value
<chr> <chr> <dbl>
1 the d1 -0.0382
2 the d2 -0.245
3 the d3 0.728
4 the d4 -0.400
5 the d5 0.0832
6 the d6 0.0440
7 the d7 -0.391
8 the d8 0.334
9 the d9 -0.575
10 the d10 0.0875
# ... with 39,999,990 more rowsnearest_neighbors() 함수를 사용해서 특정 단어와 연관된 단어를 찾아낼 수 있다.
library(widyr)
nearest_neighbors <- function(df, token) {
df %>%
widely(~ . %*% (.[token, ]),
sort = TRUE,
maximum_size = NULL)(item1, dimension, value) %>%
select(-item2)
}
tidy_glove %>%
nearest_neighbors("king")# A tibble: 400,000 x 2
item1 value
<chr> <dbl>
1 king 37.4
2 emperor 28.5
3 prince 27.7
4 queen 27.6
5 son 26.1
6 ii 25.1
7 throne 25.1
8 father 24.6
9 lord 23.9
10 kingdom 23.9
# ... with 399,990 more rows데이터 과학자 이광춘 저작
kwangchun.lee.7@gmail.com