
학습 목표
- ‘long’과 ’wide’ 데이터 형식에 대한 개념을 이해하고
tidyr팩키지를 사용해서 두 형식 사이를 변환할 수 있다.
과학연구원들은 흔히 ‘wide’ 형식에서 ‘long’ 형식으로 혹은 역으로 데이터를 솜씨있게 조작해야 한다. ‘long’ 형식은 다음과 같이 정의된다:
- 각 칼럼이 변수.
- 각 행이 관측점
‘long’ 형식에서, 일반적으로 관측된 변수에 대해서 칼럼이 하나만 있고, 다른 칼럼은 ID 변수다.
‘wide’ 형식에서, 각 행은 흔히 관측점(site/subject/patien)이며, 동일한 자료형을 담고 있는 다수 관측변수를 갖게 된다. 시간이 경과함에 따라 반복되는 관측점이거나, 다수 변수의 관측점(혹은 둘이 혼합된 사례)일 수 있다. 데이터입력이 더 단순하거나 일부 다른 응용사례에서 ‘wide’ 형식을 선호할 수 있다. 하지만, R 함수 다수는 ’long’형식을 가정하고 설계되었다. 이번 학습을 통해서 원래 데이터 형식에 관계없이 데이터를 효율적으로 변환하는 방식을 학습한다.
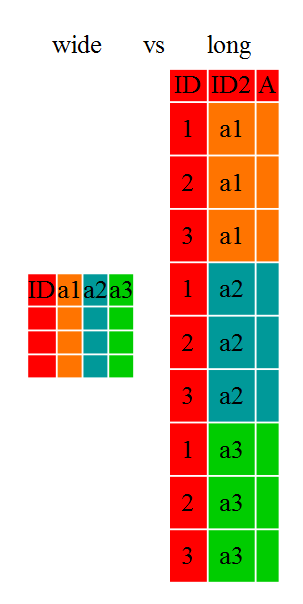
데이터 형식은 주로 가독성에 영향을 준다. 사람에게, ‘wide’ 형식이 좀더 직관적인데, 이유는 형상으로 인해 화면에 더많은 데이터를 볼 수 있기 때문이다. 하지만, 컴퓨터에게 ‘long’ 형식이 더 가독성이 높고, 데이터베이스 형식에 훨씬 더 가깝다. 데이터프레임에 ID 변수는 데이터베이스 필드(Field)와 유사하고, 관측변수는 데이터베이스 값(Value)와 유사하다.
시작하기
(아마도 이전 학습에서 dplyr팩키지는 설치했을 것이다) 먼저 설치하지 않았다면, 팩키지를 설치한다:
#install.packages("tidyr")
#install.packages("dplyr")팩키지를 불러와서 적재한다.
library("tidyr")
library("dplyr")먼저, gapminder 데이터프레임 자료구조를 살펴보자:
str(gapminder)'data.frame': 1704 obs. of 6 variables:
$ country : chr "Afghanistan" "Afghanistan" "Afghanistan" "Afghanistan" ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: chr "Asia" "Asia" "Asia" "Asia" ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...
도전과제 1
gapminder는 순수하게 ‘long’ 형식인가, ‘wide’ 형식인가, 혹은 두가지 특징을 갖는 중간형식인가?
gapminder 데이터셋처럼, 관측된 데이터에 대한 다양한 자료형이 있다. 대부분 순도 100% ‘long’ 혹은 순도 100% ‘wide’ 자료형식 사이 어딘가에 위치하게 된다. gapminder 데이터셋에는 “ID” 변수가 3개(continent, country, year), “관측변수”가 3개(pop,lifeExp,gdpPercap) 있다. 저자는 일반적으로 대부분의 경우에 중간단계 형식 데이터를 선호한다. 칼럼 1곳에 모든 관측점이 3가지 서로 다른 단위를 갖지 않음에도 불구하고 그렇다. 데이터프레임을 좀더 늘리는 연산은 거의 없다(예를 들어, ID변수 4개, 관측변수 1개).
흔히 벡터기반인 다수 R 함수를 사용할 때, 흔히 다른 단위를 갖는 값에 수학적 연산작업을 수행하지는 않느다. 예를 들어, 순수 ‘long’ 형식을 사용할 때, 인구, 기대수명, GDP의 모든 값에 대한 평균은 의미가 없는데, 이유는 상호 호환되지 않는 3가지 단위를 갖는 평균값을 계산하여 반환하기 때문이다. 해법은 먼저 집단으로 그룹지어서 데이터를 솜씨있게 다루거나 (dplyr 학습교재 참조), 데이터프레임 구조를 변경한다. 주의: R에서 일부 도식화 함수는 ‘wide’ 형식 데이터에 더 잘 작동한다.
gather()함수로 wide에서 long 형식으로 전환
지금까지, 깔끔한 형식을 갖는 원본 gapminder 데이터셋으로 작업을 했다. 하지만, ‘실제’ 데이터(즉, 자체 연구 데이터)는 절대로 잘 구성되어 있지 못하다. gapminder 데이터셋에 대한 wide 형식 버젼을 갖고 시작해본다.
str(gap_wide)'data.frame': 142 obs. of 38 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : int 31287142 10866106 7026113 1630347 12251209 7021078 15929988 4048013 8835739 614382 ...
$ pop_2007 : int 33333216 12420476 8078314 1639131 14326203 8390505 17696293 4369038 10238807 710960 ...

깔끔한 중간 데이터 형식을 얻는 첫단추는 먼저 ‘wide’ 형식에서 ‘long’ 형식으로 변환하는 것이다. tidyr 팩키지 gather() 함수는 관측 변수를 모아서(gather) 단일 변수로 변환한다.
gap_long <- gap_wide %>% gather(obstype_year,obs_values,starts_with('pop'),starts_with('lifeExp'),starts_with('gdpPercap'))
str(gap_long)'data.frame': 5112 obs. of 4 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ obstype_year: chr "pop_1952" "pop_1952" "pop_1952" "pop_1952" ...
$ obs_values : num 9279525 4232095 1738315 442308 4469979 ...
위에서 파이프 구문을 사용했는데, 이전 수업에서 dplyr로 작업한 것과 유사하다. 사실, dplyr과 tidyr은 상호 호환돼서, 파이프 구문으로 dplyr과 tidyr 팩키지 함수를 섞어 사용한다.
gather() 함수 내부에, 먼저 신규 ID 변수(obstype_year)에 대한 명칭, 병합된 관측변수(obs_value)에 대한 명칭, 그리고 나서 이전 관측변수에 대한 명칭을 신규 칼럼명으로 부여한다. 모든 관측변수를 타이핑했지만, select() 함수처럼(dplyr 수업 참조), starts_with() 함수에 인자로 넣어, 원하는 문자열로 시작되는 모든 변수를 선택할 수도 있다. gather() 모을 필요없는 변수(예를 들어, ID 변수)를 식별하는데, - 기호를 사용하는 대체가능한 구문도 지원한다.
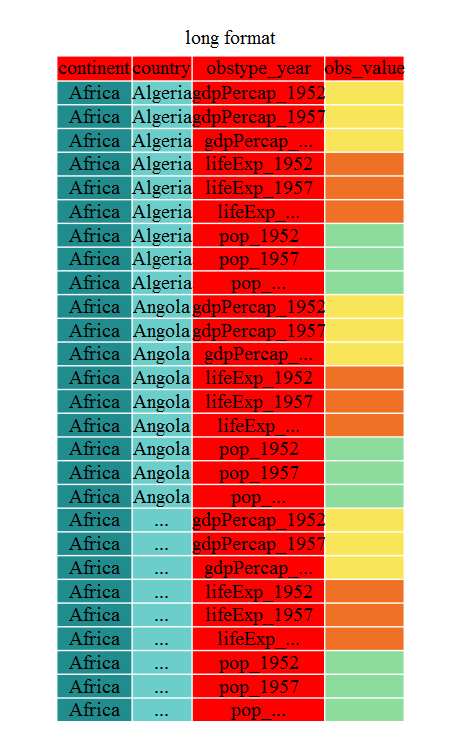
gap_long <- gap_wide %>% gather(obstype_year,obs_values,-continent,-country)
str(gap_long)'data.frame': 5112 obs. of 4 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ obstype_year: chr "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" ...
$ obs_values : num 2449 3521 1063 851 543 ...
이런 특수한 데이터프레임에는 별거 없어 보일 수도 있다. 하지만, ID 변수 하나, 규칙없는 변수명 관측변수 40개를 갖는 경우가 있을 수 있다. 이런 유연성은 시간을 상당히 절약해 준다!
이제 obstype_year은 정보가 두조각으로 나뉜다: 관측 유형(pop,lifeExp, gdpPercap)과 연도(year). separate() 함수를 사용해서 문자열을 다수 변수로 쪼갠다.
gap_long <- gap_long %>% separate(obstype_year,into=c('obs_type','year'),sep="_")
gap_long$year <- as.integer(gap_long$year)도전 과제 2
gap_long을 사용해서, 각 대륙별로 평균 기대수명, 인구, 1인당 GDP를 계산한다. 힌트: dplyr 수업에서 학습한 group_by() 와 summarize() 함수를 사용한다.
spread() 함수로 ‘long’ 형식에서 중간 혹은 ‘wide’ 형식으로
이제 작업을 이중점검 하도록, gather() 역함수(적절히 작명된 spread())를 사용해서 관측변수를 다시 되돌린다. 그리고 나면 gap_long을 원래 중간 형식 혹은 ‘wide’ 형식으로 퍼뜨린다. 중간 형식에서 시작해보자.
gap_normal <- gap_long %>% spread(obs_type,obs_values)
dim(gap_normal)[1] 1704 6
dim(gapminder)[1] 1704 6
names(gap_normal)[1] "continent" "country" "year" "gdpPercap" "lifeExp" "pop"
names(gapminder)[1] "country" "year" "pop" "continent" "lifeExp" "gdpPercap"
이제, 최초 데이터프레임 gapminder와 동일한 차원을 갖는 중간 데이터프레임 gap_normal이 있다. 하지만, 변수 순서가 다르다. 순서를 수정하기 전에, all.equal() 함수를 사용해서 동일한지 확인한다.
gap_normal <- gap_normal[,names(gapminder)]
all.equal(gap_normal,gapminder)[1] "Component \"country\": 1704 string mismatches"
[2] "Component \"pop\": Mean relative difference: 1.634504"
[3] "Component \"continent\": 1212 string mismatches"
[4] "Component \"lifeExp\": Mean relative difference: 0.203822"
[5] "Component \"gdpPercap\": Mean relative difference: 1.162302"
head(gap_normal) country year pop continent lifeExp gdpPercap
1 Algeria 1952 9279525 Africa 43.077 2449.008
2 Algeria 1957 10270856 Africa 45.685 3013.976
3 Algeria 1962 11000948 Africa 48.303 2550.817
4 Algeria 1967 12760499 Africa 51.407 3246.992
5 Algeria 1972 14760787 Africa 54.518 4182.664
6 Algeria 1977 17152804 Africa 58.014 4910.417
head(gapminder) country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
4 Afghanistan 1967 11537966 Asia 34.020 836.1971
5 Afghanistan 1972 13079460 Asia 36.088 739.9811
6 Afghanistan 1977 14880372 Asia 38.438 786.1134
거의 다 왔다. 최초 데이터프레임이 country, continent, year 순으로 정렬되었다.
gap_normal <- gap_normal %>% arrange(country,continent,year)
all.equal(gap_normal,gapminder)[1] TRUE
훌륭하다! ‘long’ 형식에서 다시 중간 형식으로 돌아갔지만, 코드에 어떤 오류도 스며들지 않았다.
이제, ‘long’ 형식을 ‘wide’ 형식으로 변환하자. ‘wide’ 형식에서, country 국가와 contienet 대륙을 ID 변수로 두고, 관츠점을 3가지 측정값(pop,lifeExp,gdpPercap)과 시간(year)으로 쭉 뿌렸다. 먼저, 모든 신규 변수(측정값 * 시간)에 대한 적절한 라벨을 생성할 필요가 있다. 또한, ID변수를 합쳐서 gap_wide를 정의하는 과정을 단순화할 필요가 있다.
gap_temp <- gap_long %>% unite(var_ID,continent,country,sep="_")
str(gap_temp)'data.frame': 5112 obs. of 4 variables:
$ var_ID : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ obs_type : chr "gdpPercap" "gdpPercap" "gdpPercap" "gdpPercap" ...
$ year : int 1952 1952 1952 1952 1952 1952 1952 1952 1952 1952 ...
$ obs_values: num 2449 3521 1063 851 543 ...
gap_temp <- gap_long %>%
unite(ID_var,continent,country,sep="_") %>%
unite(var_names,obs_type,year,sep="_")
str(gap_temp)'data.frame': 5112 obs. of 3 variables:
$ ID_var : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ var_names : chr "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" ...
$ obs_values: num 2449 3521 1063 851 543 ...
unite()를 사용해서, continent,country를 묶는 ID변수가 하나 생겼고, 변수명을 정의했다. 이제 파이프를 통해서 spread() 뿌린 준비를 마쳤다.
gap_wide_new <- gap_long %>%
unite(ID_var,continent,country,sep="_") %>%
unite(var_names,obs_type,year,sep="_") %>%
spread(var_names,obs_values)
str(gap_wide_new)'data.frame': 142 obs. of 37 variables:
$ ID_var : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num 33333216 12420476 8078314 1639131 14326203 ...
도전과제 3
한 걸음 더 나아가, 국가, 연도, 측정값 3개를 쭉 뿌려 터무니 없는 gap_ludicrously_wide 형식 데이터를 생성한다. 힌트: 신규 데이터프레임은 단지 행이 5개만 있다.
이제, 엄청 ‘wide’ 형식 데이터프레임이 생겼다. 하지만, ID_var 변수는 더 유용할 수 있다. separate() 함수로 변수 2개로 구분하자.
gap_wide_betterID <- separate(gap_wide_new,ID_var,c("continent","country"),sep="_")
gap_wide_betterID <- gap_long %>%
unite(ID_var,continent,country,sep="_") %>%
unite(var_names,obs_type,year,sep="_") %>%
spread(var_names,obs_values) %>%
separate(ID_var,c("continent","country"),sep="_")
str(gap_wide_betterID)'data.frame': 142 obs. of 38 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num 33333216 12420476 8078314 1639131 14326203 ...
all.equal(gap_wide,gap_wide_betterID)[1] TRUE
다시 되돌아 왔다!
도전과제 1에 대한 해답
최초 gapminder 데이터프레임은 중간 형식이다. 순도 100% ‘long’ 이 아닌 이유는 관측변수(pop,lifeExp,gdpPercap)가 다수 있기 때문이다.
도전과제 2에 대한 해답
gap_long %>% group_by(continent,obs_type) %>%
summarize(means=mean(obs_values))Source: local data frame [15 x 3]
Groups: continent [?]
continent obs_type means
(chr) (chr) (dbl)
1 Africa gdpPercap 2.193755e+03
2 Africa lifeExp 4.886533e+01
3 Africa pop 9.916003e+06
4 Americas gdpPercap 7.136110e+03
5 Americas lifeExp 6.465874e+01
6 Americas pop 2.450479e+07
7 Asia gdpPercap 7.902150e+03
8 Asia lifeExp 6.006490e+01
9 Asia pop 7.703872e+07
10 Europe gdpPercap 1.446948e+04
11 Europe lifeExp 7.190369e+01
12 Europe pop 1.716976e+07
13 Oceania gdpPercap 1.862161e+04
14 Oceania lifeExp 7.432621e+01
15 Oceania pop 8.874672e+06
도전과제 3에 대한 해답
gap_ludicrously_wide <- gap_long %>%
unite(var_names,obs_type,year,country,sep="_") %>%
spread(var_names,obs_values)