
재현가능한 과학적 분석을 위한 R
분할-적용-병합 전략
학습 목표
- 자료분석에 분할-적용-병합 전략을 활용한다.
앞서, 함수를 사용해서 코드를 단순화하는 방법을 살펴봤다. gapminder 데이터셋을 인자로 받아, 인구(population)와 인당 GDP를 곱해 GPD를 계산하는 calcGDP 함수를 정의했다. 추가적인 인자를 정의해서, year 연도별, country 국가별 필터를 적용할 수도 있다:
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}데이터 작업을 할 때, 흔히 마주치는 작업이 집단별 그룹으로 묶어 계산하는 것이다. 위에서, 단순히 두 칼럼을 곱해서 GDP를 계산했다. 하지만, 대륙별로 평균 GDP를 계산하고자 한다면 어떨까?
calcGDP를 실행하고 나서, 각 대륙별로 평균을 산출한다:
withGDP <- calcGDP(gapminder)
mean(withGDP[withGDP$continent == "Africa", "gdp"])[1] 20904782844
mean(withGDP[withGDP$continent == "Americas", "gdp"])[1] 379262350210
mean(withGDP[withGDP$continent == "Asia", "gdp"])[1] 227233738153
하지만, 그다지 멋있지는 않다. 그렇다. 함수를 사용해서, 반복되는 상당량 작업을 줄일 수 있었다. 함수 사용은 멋있었다. 하지만, 여전히 반복이 있다. 여러분이 직접 반목하게 되면, 일단 여러분 시간을 지금 그리고 나중에 까먹게 되고, 잠재적으로 버그가 스며들 여지를 남기게 된다.
calcGDP처럼 유연성 있는 함수를 새로 작성할 수도 있지만, 제대로 동작하는 함수를 개발하기까지 상당량 노력과 테스트가 필요하다.
여기서 맞닥드린 추상화 문제를 “분할-적용-병합” 전략이라고 부른다:
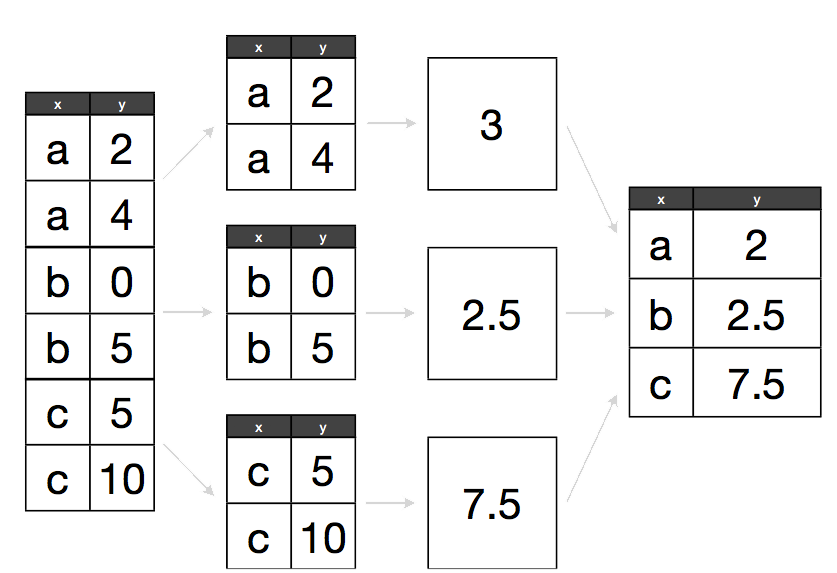
Split apply combine
데이터를 집단으로 분할(split)하고, 이번 경우에 대륙, 해당 집단에 연산작업을 적용(apply)하고 나서, 선택옵션으로 결과를 묶어 병합(combine)한다.
plyr 팩키지
R을 예전에 사용했다면, apply 함수 가족에 친숙할 수 있다. R 내장함수도 동작이 잘 되지만, “분할-적용-병합” 문제를 해결하는데 사용되는 또다른 방법을 소개한다. plyr 팩키지는 이런 유형의 문제를 해결하는데 훨씬 사용자 친화적인 함수를 집합으로 제공한다.
이전 도전과제에서 plyr 팩키지를 설치했다. 이제 plyr 불러와서 적재한다:
library(plyr)plyr 팩키지에는 리스트(lists), 데이터프레임(data.frames), 배열(arrays, 행렬, n-차원 벡터) 자료형 연산을 위한 함수가 있다. 함수 각각은 다음 작업을 수행한다:
- 분할(split)하는 연산
- 순서대로 각각 쪼갠 것에 함수를 적용(apply)한다.
- 데이터 객체로 출력 데이터로 다시 병합(combine)한다.
입력값으로 예상되는 자료구조와 출력값으로 반환되는 자료구조에 기반해서 함수명이 붙여졌다: [a]rray, [l]ist, [d]ata.frame. 첫번째 문자가 입력 자료구조, 두번째 문자가 출력 자료구조에 대응되고, 함수 나머지에 “ply”를 붙인다.
[a]rray, [l]ist, [d]ata.frame 를 입력과 출력에 조합하면 핵심 **ply 함수 9개가 산출된다. 분할과 적용 단계만 수행하고 병합단계를 거치지 않는 함수가 추가로 3개 있다. 입력 데이터 자료형에 NULL 출력값(_)으로 표현된다. (아래 테이블 참조)
여기서 “배열”에 대한 plyr이 다른 것과 다름에 주목한다. ply에 사용되는 배열은 벡터 혹은 행렬을 포함할 수 있다.
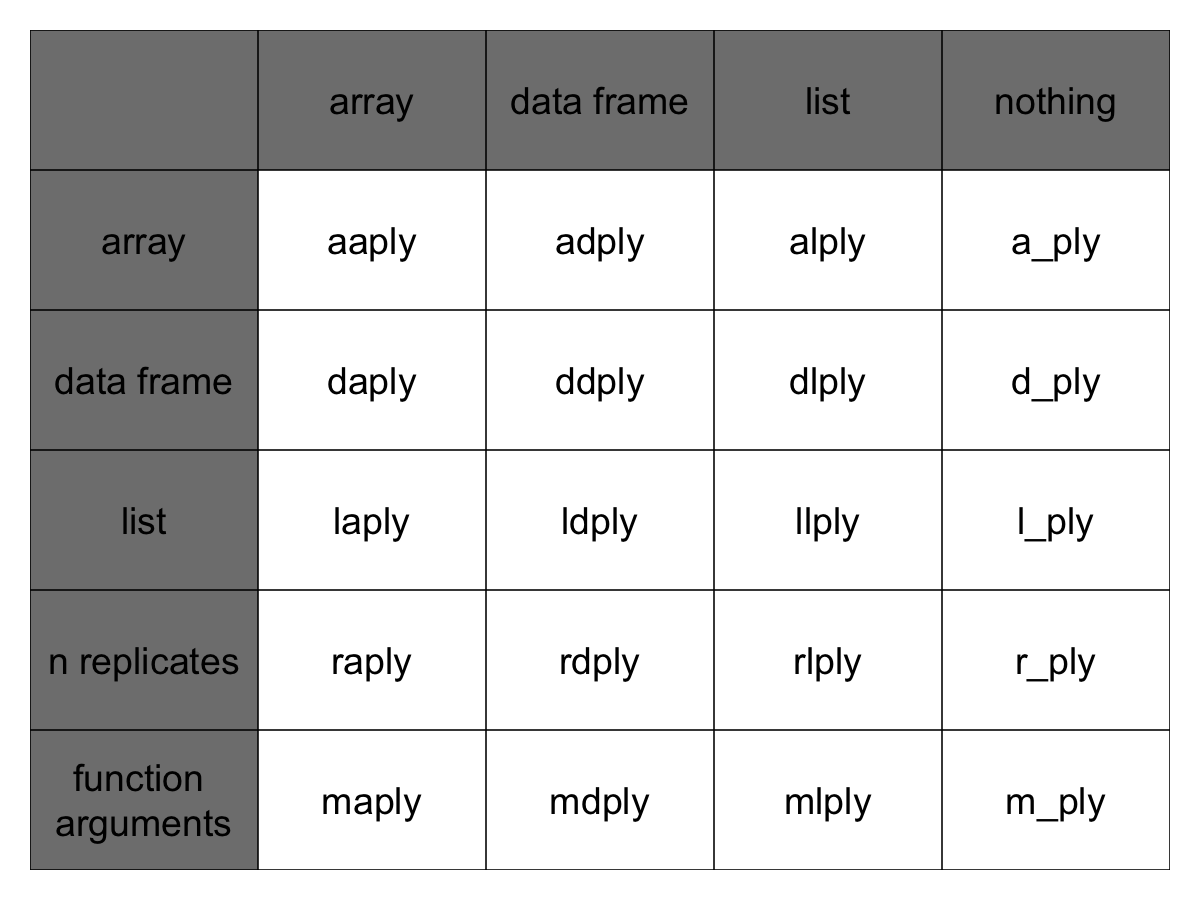
Full apply suite
xxply 함수(daply, ddply, llply, laply, …) 각각은 동일한 구조를 갖고, 4가지 주요 기능을 갖는다:
xxply(.data, .variables, .fun)- 함수명 첫글자는 입력 자료형, 함수 두번째 글자는 출력 자료형을 나타낸다.
- .data - 처리될 자료객체를 나타낸다.
- .variables - 분할(split)변수를 식별한다.
- .fun - 각 그룹 집단에 연산작업을 위해 호출되는 함수.
이제, 대륙별로 평균 GDP를 신속하게 계산할 수 있다:
ddply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
) continent V1
1 Africa 20904782844
2 Americas 379262350210
3 Asia 227233738153
4 Europe 269442085301
5 Oceania 188187105354
방금전에 일어난 사건을 복기해 보자:
ddply함수에data.frame데이터프레임을 집어넣고(함수명이 d로 시작), 또다른data.frame데이터프레임을 반환한다(함수명 두번째 문자 d).- 전달한 첫번째 인자는 연산작업을 실행하고자 하는 데이터프레임이다: 이번 경우에 gapminder 데이터. 먼저
calcGDP함수를 호출해서, gapminder 데이터프레임에gdp칼럼을 추가한다. - 두번째 인자가 분할 조건을 명시한다: 이번 경우에, “대륙(continent)” 칼럼이다. 부분집합(subsetting) 연산으로 이전에 수행했던 것처럼, 실제 칼럼 자체가 아니라, 칼럼명만 부여했음에 주목한다.
plyr팩키지에 자세한 구현이 되어 있어, 칼럼명만 전달하면 된다. - 세번째 인자는 그룹 집단 각각에 적용하고자 하는 함수다. 이번 경우에는, 짧은 함수를 자체 정의했다: 데이터 각 부분집합은 함수 첫번째 인자,
x에 저장되어 있다. 이것을 람다 함수라고 부른다: 어디서도 정의하지 않았기 때문에, 이름이 없는 무명함수다.ddply함수가 호출되는 범위(scope)에만 존재한다.
출력 자료구조를 달리하면 어떨까?
dlply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
)$Africa
[1] 20904782844
$Americas
[1] 379262350210
$Asia
[1] 227233738153
$Europe
[1] 269442085301
$Oceania
[1] 188187105354
attr(,"split_type")
[1] "data.frame"
attr(,"split_labels")
continent
1 Africa
2 Americas
3 Asia
4 Europe
5 Oceania
동일한 함수를 호출했지만, 두번째 문자만 l로 변경했다. 그래서, 출력결과가 리스트로 반환됐다.
다수 칼럼을 지정해서 그룹별로 group by 할 수 있다:
ddply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
) continent year V1
1 Africa 1952 5992294608
2 Africa 1957 7359188796
3 Africa 1962 8784876958
4 Africa 1967 11443994101
5 Africa 1972 15072241974
6 Africa 1977 18694898732
7 Africa 1982 22040401045
8 Africa 1987 24107264108
9 Africa 1992 26256977719
10 Africa 1997 30023173824
11 Africa 2002 35303511424
12 Africa 2007 45778570846
13 Americas 1952 117738997171
14 Americas 1957 140817061264
15 Americas 1962 169153069442
16 Americas 1967 217867530844
17 Americas 1972 268159178814
18 Americas 1977 324085389022
19 Americas 1982 363314008350
20 Americas 1987 439447790357
21 Americas 1992 489899820623
22 Americas 1997 582693307146
23 Americas 2002 661248623419
24 Americas 2007 776723426068
25 Asia 1952 34095762661
26 Asia 1957 47267432088
27 Asia 1962 60136869012
28 Asia 1967 84648519224
29 Asia 1972 124385747313
30 Asia 1977 159802590186
31 Asia 1982 194429049919
32 Asia 1987 241784763369
33 Asia 1992 307100497486
34 Asia 1997 387597655323
35 Asia 2002 458042336179
36 Asia 2007 627513635079
37 Europe 1952 84971341466
38 Europe 1957 109989505140
39 Europe 1962 138984693095
40 Europe 1967 173366641137
41 Europe 1972 218691462733
42 Europe 1977 255367522034
43 Europe 1982 279484077072
44 Europe 1987 316507473546
45 Europe 1992 342703247405
46 Europe 1997 383606933833
47 Europe 2002 436448815097
48 Europe 2007 493183311052
49 Oceania 1952 54157223944
50 Oceania 1957 66826828013
51 Oceania 1962 82336453245
52 Oceania 1967 105958863585
53 Oceania 1972 134112109227
54 Oceania 1977 154707711162
55 Oceania 1982 176177151380
56 Oceania 1987 209451563998
57 Oceania 1992 236319179826
58 Oceania 1997 289304255183
59 Oceania 2002 345236880176
60 Oceania 2007 403657044512
daply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
) year
continent 1952 1957 1962 1967
Africa 5992294608 7359188796 8784876958 11443994101
Americas 117738997171 140817061264 169153069442 217867530844
Asia 34095762661 47267432088 60136869012 84648519224
Europe 84971341466 109989505140 138984693095 173366641137
Oceania 54157223944 66826828013 82336453245 105958863585
year
continent 1972 1977 1982 1987
Africa 15072241974 18694898732 22040401045 24107264108
Americas 268159178814 324085389022 363314008350 439447790357
Asia 124385747313 159802590186 194429049919 241784763369
Europe 218691462733 255367522034 279484077072 316507473546
Oceania 134112109227 154707711162 176177151380 209451563998
year
continent 1992 1997 2002 2007
Africa 26256977719 30023173824 35303511424 45778570846
Americas 489899820623 582693307146 661248623419 776723426068
Asia 307100497486 387597655323 458042336179 627513635079
Europe 342703247405 383606933833 436448815097 493183311052
Oceania 236319179826 289304255183 345236880176 403657044512
for 루프 자리에 람다 함수를 사용할 수 있다(대체로 더 빠르다): for 루프 몸통부분을 람다 함수에 작성하면 된다:
d_ply(
.data=gapminder,
.variables = "continent",
.fun = function(x) {
meanGDPperCap <- mean(x$gdpPercap)
print(paste(
"The mean GDP per capita for", unique(x$continent),
"is", format(meanGDPperCap, big.mark=",")
))
}
)[1] "The mean GDP per capita for Africa is 2,193.755"
[1] "The mean GDP per capita for Americas is 7,136.11"
[1] "The mean GDP per capita for Asia is 7,902.15"
[1] "The mean GDP per capita for Europe is 14,469.48"
[1] "The mean GDP per capita for Oceania is 18,621.61"
도전과제 1
대륙별로 평균 기대수명을 계산하라. 어느 대륙이 가장 기대수명이 긴가? 어느 대륙이 가장 기대수명이 짧은가?
도전과제 2
대륙과 연도별로 평균 기대수명을 계산하시오. 2007년에 어느 것이 가장 짧고, 가장 긴가? 1952년과 2007년 사이에 가장 커다란 변화는 어느 것인가?
고급 도전과제
plyr 함수 중 하나를 사용해서 도전과제 2에서 나온 출력결과로부터, 1952년에서 2007년 사이 평균 기대수명 차이를 계산하시오.
(수업시간이 길을 잃어버린 듯 하다면) 대안 도전과제
실제로 실행하지 말고, 다음 중 어떤 코드가 대륙별 평균 기대수명을 계산하는가:
ddply(
.data = gapminder,
.variables = gapminder$continent,
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)ddply(
.data = gapminder,
.variables = "continent",
.fun = mean(dataGroup$lifeExp)
)ddply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)adply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)