
데이터 과학
FP 자료구조
학습 목표
- 함수형 프로그래밍을 위한 기본 자료구조를 이해한다.
- 벡터와 리스트 생성, 인덱싱, 강제변환에 대해 살펴본다.
- 벡터화 연산을 벡터와 리스트 자료형에 적용하고 차이점을 이해한다.
- 리스트 칼럼(list-column) 자료형에 대해 이해한다.
- R 자료형을 레고블록을 통해 이해한다.
1. 벡터 1 2
벡터와 리스트는 R의 기본 자료구조라 데이터 분석에 자주 사용되는 기본 자료구조에 친숙해지면 여러모로 장점이 많다. 가장 많이 사용되는 자료구조는 논리형(logical), 정수형(integer), 부동소수점형(double), 문자형(character)가 있다. 원자벡터는 동일한 자료형을 한곳에 모아 높은 것으로 각 원자는 자료형과 저장모드가 동일하다고 볼 수 있다. 물론 스칼라(scalar)는 길이가 1을 갖는 원자다. 원자벡터를 생성하는 기본 연산자는 c()가 되지만, 삶을 편하게 하는 여러가지 축약방법이 존재하는데 1:4, letters가 여기에 포함된다.
- R에서 흔히 사용되는 자료형
- 논리형(logical)
- 정수형(integer)
- 부동소수점형(double)
- 문자형(character)
(v_log <- c(TRUE, FALSE, FALSE, TRUE))#> [1] TRUE FALSE FALSE TRUE
(v_int <- 1:4)#> [1] 1 2 3 4
(v_doub <- 1:4 * 1.2)#> [1] 1.2 2.4 3.6 4.8
(v_char <- letters[1:4])#> [1] "a" "b" "c" "d"
1.1. 벡터 색인(Indexing, 인텍싱)
벡터에서 특정 원소를 참조하거나 뽑아내는 것을 인덱싱(indexing)이라고 한다. 원소를 참조하거나 뽑아낼 때 사용되는 기본문법은 꺾쇠 괄호([)를 사용하는 것으로, 벡터명[색인방법] 형태가 된다. 인덱싱 방법은 다음과 같이 세가지 방법이 있다.
- 논리 벡터 사용:
TRUE는 뽑아내고,FALSE는 색인에서 제거한다. - 정수 벡터 사용
- 양수 정수 벡터: 벡터 색인 숫자에 해당되는 벡터만 추출, 벡터 색인은 1부터 시작.
- 음수 정수 벡터: 벡터 색인 숫자에 해당되는 벡터만 제거.
- 문자벡터 : 문자벡터 명칭에 해당되는 원소만 추출.
v_char[c(FALSE, FALSE, TRUE, TRUE)]#> [1] "c" "d"
v_char[v_log]#> [1] "a" "d"
v_doub[2:3]#> [1] 2.4 3.6
v_char[-4]#> [1] "a" "b" "c"
1.2. 자료형 강제변환(coersion)
자료형 강제변환은 R이 갖는 가장 큰 장점 중의 하나다. 특히, 정수형과 부동소수점형 자료변환에 대해서 큰 스트레스가 없는데 R에서 강제변환기능을 통해 이를 자체적으로 해결해 준다. 또한 비율을 구할 때 논리형 벡터가 자동으로 정수형으로 변환되어 1과 0을 이용하여 쉽게 구할 수 있다.
자료형 강제변환은 벡터 내부에 이질적인 원소들이 갖춰졌을 때 자동으로 동일한 원소들이 되도록 변환되는 위계가 다음과 같이 존재한다.
- 논리형(logical)
- 정수형(integer)
- 부동소수점형(double)
- 문자형(character)
v_log#> [1] TRUE FALSE FALSE TRUE
as.integer(v_log)#> [1] 1 0 0 1
v_int#> [1] 1 2 3 4
as.numeric(v_int)#> [1] 1 2 3 4
v_doub#> [1] 1.2 2.4 3.6 4.8
as.character(v_doub)#> [1] "1.2" "2.4" "3.6" "4.8"
as.character(as.numeric(as.integer(v_log)))#> [1] "1" "0" "0" "1"
자료형 강제변환 위계에 대한 사례로 부동소수점과 문자형이 동일한 벡터에 입력되면, 동일한 자료형을 갖춰야 되는 벡터 입장에서 자료변환 위계구조에 따라 모두 문자형으로 변환이 된다.
v_doub_copy <- v_doub
str(v_doub_copy)#> num [1:4] 1.2 2.4 3.6 4.8
v_doub_copy[3] <- "uhoh"
str(v_doub_copy)#> chr [1:4] "1.2" "2.4" "uhoh" "4.8"
2. 리스트(list)
앞선 벡터 정의가 상당히 경직된다고 느낄 때가 있다. 즉, 벡터 길이가 동일하지 않거나 각 벡터가 동일한 자료구조를 갖지 않는 경우가 있다. 이런 경우 리스트가 필요하다. 리스트는 실제로 벡터 그 자체인데, 원자벡터는 아니다.
- 서로 다른 자료형 벡터를 담을 수 있고, 심지어 함수도 담을 수 있다.
- 데이터프레임과 달리 각 벡터 길이가 동일할 필요는 없다.
- 리스트 내부 벡터명을 갖을 수도 있고, 갖지 않을 수도 있다.
list() 명령어를 리스트 자료형을 생성한다.
(x <- list(1:3, c("four", "five")))#> [[1]]
#> [1] 1 2 3
#>
#> [[2]]
#> [1] "four" "five"
(y <- list(logical = TRUE, integer = 4L, double = 4 * 1.2, character = "character"))#> $logical
#> [1] TRUE
#>
#> $integer
#> [1] 4
#>
#> $double
#> [1] 4.8
#>
#> $character
#> [1] "character"
(z <- list(letters[26:22], transcendental = c(pi, exp(1)), f = function(x) x^2))#> [[1]]
#> [1] "z" "y" "x" "w" "v"
#>
#> $transcendental
#> [1] 3.141593 2.718282
#>
#> $f
#> function (x)
#> x^2
2.1. 리스트(list) 인덱싱
리스트 내부 색인 인덱싱하는 방법은 다음과 같은 세가지 방법이 있다.

[꺾쇠 괄호를 하나 사용: 언제나 리스트를 반환한다.[[이중 꺾쇠 괄호 사용: 리스트가 제거 되어 원 벡터 내부 자료형이 반환된다. 벡터와 마찬가지로 색인 정수형 숫자, 혹은 벡터명을 사용가능.$데이터프레임 변수명 추출 방식과 동일:[[처럼 사용할 수 있으나 벡터명칭을 꼭 사용해야만 된다.
# 리스트 인덱싱
# 1. 리스트 추출
x[c(FALSE, TRUE)]#> [[1]]
#> [1] "four" "five"
y[2:3]#> $integer
#> [1] 4
#>
#> $double
#> [1] 4.8
z["transcendental"]#> $transcendental
#> [1] 3.141593 2.718282
# 2. 리스트 원소 추출
x[[2]]#> [1] "four" "five"
y[["double"]]#> [1] 4.8
# 3. `$` 연산자 사용
z$transcendental#> [1] 3.141593 2.718282
3. 벡터화 연산 3
루프를 대신하여 벡터화 연산(Vectorized Operations)을 수행하게 되면 구문이 간결해지고 속도 향상도 R에서 기대할 수 있다.
- 벡터화 연산을 사용하면 코드가 간결해져서 코드를 작성하는 개발자의 인지부하가 상대적으로 루프를 사용할 경우보다 줄어든다.
- 벡터화 연산은 벡터에만 사용할 수 있어, 리스트에 동일한 개념을 적용시키려면
purrr팩키지를 사용해야 된다.
## 자료가 벡터
### 루프 사용
n <- 5
res <- rep(NA_integer_, n)
for (i in seq_len(n)) {
res[i] <- i ^ 2
}
res#> [1] 1 4 9 16 25
### 벡터연산 사용
n <- 5
seq_len(n) ^ 2#> [1] 1 4 9 16 25
## 자료가 리스트
(v_doub <- 1:4 * 1.2)#> [1] 1.2 2.4 3.6 4.8
exp(v_doub)#> [1] 3.320117 11.023176 36.598234 121.510418
(l_doub <- as.list(v_doub))#> [[1]]
#> [1] 1.2
#>
#> [[2]]
#> [1] 2.4
#>
#> [[3]]
#> [1] 3.6
#>
#> [[4]]
#> [1] 4.8
exp(l_doub)#> Error in exp(l_doub): 수학함수에 숫자가 아닌 인자가 전달되었습니다
library(purrr)
map(l_doub, exp)#> [[1]]
#> [1] 3.320117
#>
#> [[2]]
#> [1] 11.02318
#>
#> [[3]]
#> [1] 36.59823
#>
#> [[4]]
#> [1] 121.5104
4. 리스트 칼럼 4
4.1 레고를 통해 본 R 자료 구조 5
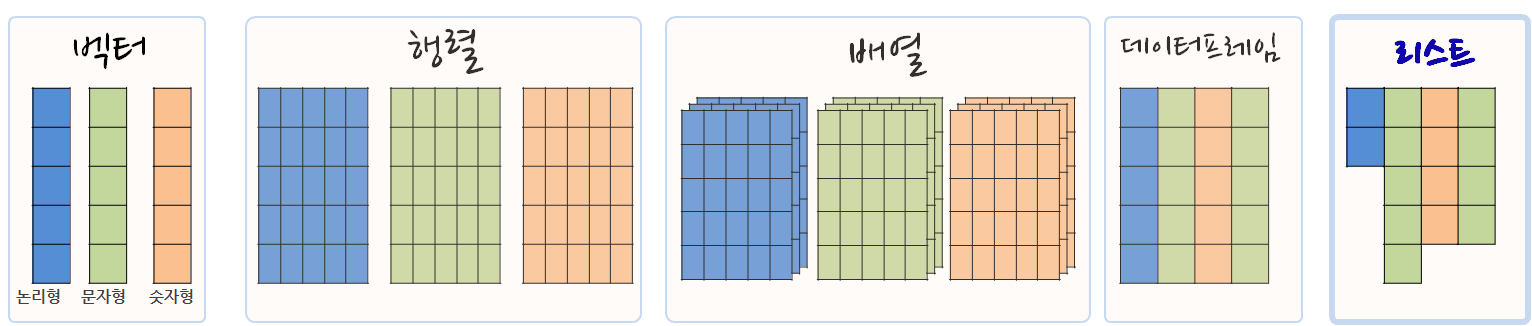
레고를 통해 살펴본 R 자료구조는 계산가능한 원자 자료형(논리형, 숫자형, 요인형)으로 크게 볼 수 있다. R에서 정수형과 부동소수점은 그다지 크게 구분을 하지 않는다. 동일 길이를 갖는 벡터를 쭉 붙여넣으면 자료구조형이 데이터프레임으로 되고, 길이가 갖지 않는 벡터를 한 곳에 모아넣은 자료구조가 리스트다.
데이터프레임이 굳이 모두 원자벡터만을 갖출 필요는 없다. 리스트를 데이터프레임 내부에 갖는 것도 데이터프레임인데 굳이 구별하자면 티블(tibble)이고, 이런 자료구조를 리스트-칼럼(list-column)이라고 부른다.

리스트-칼럼 자료구조가 빈번히 마주하는 경우가 흔한데… 대표적으로 다음 사례를 들 수 있다.
- 정규표현식을 통한 텍스트 문자열 처리
- 웹 API로 추출된 JSON, XML 데이터
- 분할-적용-병합(Split-Apply-Combine) 전략
데이터프레임이 티블(tibble) 형태로 되어 있으면 다음 작업을 나름 수월하게 추진할 수 있다.
- 들여다보기(Inspect): 데이터프레임에 무엇이 들었는지 확인.
- 인덱싱(Indexing): 명칭 혹은 위치를 확인해서 필요한 원소를 추출.
- 연산(Compute): 리스트-칼럼에 연산 작업을 수행해서 또다른 벡터나 리스트-칼럼을 생성.
- 간략화(Simplify): 리스트-칼럼을 익숙한 데이터프레임으로 변환.