BoW(Bag of Words)¶
트위터 감성을 분류하는데 트위터 텍스트를 사전에 정제할 필요가 있다.
이를 위해서 spacy 라이브러리를 활용하는데 clean_text() 사용자 정의 함수를 만들어서 표제어 추출(lemmatization) 작업을 수행해서 이를 BoW(Bag of Words)에 넣어 트위터 감성 분류하는데 사용할 예측모형을 개발한다.
트위터 데이터 가져오기¶
먼저 트위터 텍스트 데이터를 가져온다.
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
df = pd.read_csv("data/twitter_sentiment_train.csv", encoding = "ISO-8859-1")
smpl_df = df.sample(1000, random_state = 77777)
smpl_df.columns = ["item_id", "sentiment", "text"]
smpl_df.shape
텍스트 정제¶
텍스트를 정제하는 기법은 여러가지가 있지만, 아래 clean_text() 사용자 정의 함수를 만들어서 표제어 추출(lemmatization) 작업을 수행한다.
import spacy
print(f"spaCy Version: {spacy.__version__}")
nlp = spacy.load('en')
spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
# 데이터 전처리 함수
def clean_text(text):
doc = nlp(text, disable=['ner', 'parser'])
lemmas = [token.lemma_ for token in doc]
a_lemmas = [lemma for lemma in lemmas
if lemma.isalpha() and lemma not in spacy_stopwords]
return ' '.join(a_lemmas)
smpl_df['lemma_text'] = smpl_df['text'].apply(clean_text)
print(smpl_df['lemma_text'].head())
BoW 모형¶
BoW 모형을 sklearn 라이브러리 CountVectorizer 클래스를 사용해서 구현한다.
CountVectorizer 클래스¶
CountVectorizer 클래스를 활용하여 앞서 표제어 추출한 칼럼('lemma_text')을 BoW 객체로 변환시킨다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer='word')
twitter_bow = vectorizer.fit_transform(smpl_df['lemma_text'])
print(twitter_bow.shape)
BoW 변환이 제대로 되었는지를 확인하기 위해서 BoW를 데이터프레임으로 변환시킨다.
그리고 나서 get_feature_names() 메쏘드를 호출해서 변환시킨 판다스 데이터프레임 칼럼명으로 넣어 확인한다.
twitter_bow_df = pd.DataFrame(twitter_bow.toarray())
twitter_bow_df.columns = vectorizer.get_feature_names()
print(twitter_bow_df.head())
나이브 베이즈 예측모형¶
표제어 추출을 통해서 나름 전처리가 완료된 트위터 텍스트를 BoW 모형으로 Feature를 추출해 낼 수 있는 준비가 완료되었기에 다음 단계로 나이브 베이즈 예측모형에 넣어 예측모형의 성능을 비교해 본다.
먼저 훈련/시험 데이터로 나누고 앞서 정제한 표제어 추출 칼럼('lemma_text')을 CountVectorizer 클래스를 통해서 BoW 객체로 만들고 이를 나이브 베이즈로 예측정확도를 높여본다.
# 나이브 베이즈 모형
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
# 훈련/시험 데이터 분리
feature_df = smpl_df[['lemma_text']]
target = smpl_df['sentiment']
X_train, X_test, y_train, y_test = train_test_split(feature_df, target, test_size=0.3)
# BoW Feature
vect = CountVectorizer(analyzer='word')
X_train_bow = vect.fit_transform(X_train['lemma_text'])
X_test_bow = vect.transform(X_test['lemma_text'])
# 예측모형 적합
clf = MultinomialNB()
# Fit the classifier
clf.fit(X_train_bow, y_train)
# Measure the accuracy
accuracy = clf.score(X_test_bow, y_test)
print(f"시험 데이터셋으로 검정한 감성 분류 예측모형 정확도: {accuracy:.3f}")
텍스트 통계 지표 + BoW¶
트위터 감성 예측 - 텍스트 통계지표 모형에 BoW를 결합시켜 예측모형의 정확도를 높여본다.
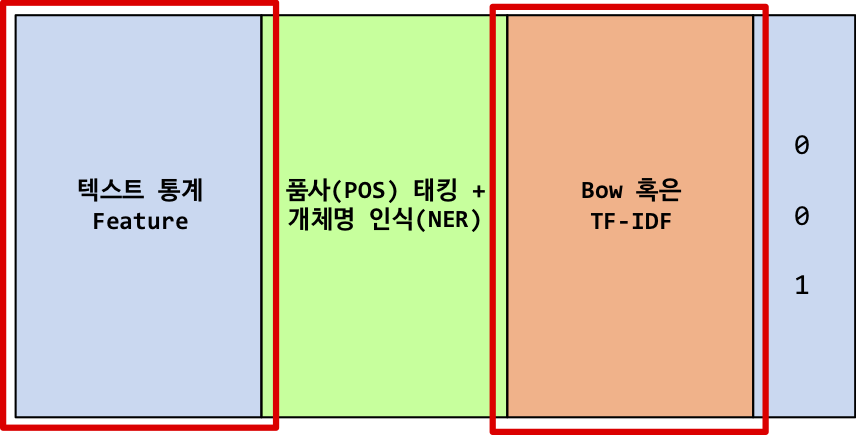
텍스트 통계 지표¶
텍스트 통계 지표를 트위터 감성 예측 - 텍스트 통계지표에서 가져온다.
####################################################################
# 텍스트 통계지표
####################################################################
# 1. 문자갯수
# df['char_cnt'] = df['text'].apply(len)
# 2. 단어갯수
def count_words(text):
'''
문장을 입력받아 단어갯수를 반환한다.
'''
words = text.split()
return len(words)
# 3. 해쉬태그(#) 갯수
def count_hashtag(text):
'''
문장을 입력받아 해쉬태그(#)를 센다
'''
words = text.split()
hashtags = [word for word in words if word.startswith('#')]
return len(hashtags)
# 4. 언급(@) 갯수
def count_mention(text):
'''
문장을 입력받아 언급횟수(@)를 센다
'''
words = text.split()
mentions = [word for word in words if word.startswith('@')]
return len(mentions)
feature_df = smpl_df[['lemma_text']]
feature_df['char_cnt'] = feature_df['lemma_text'].apply(len)
feature_df['hashtag_cnt'] = feature_df['lemma_text'].apply(count_hashtag)
feature_df['word_cnt'] = feature_df['lemma_text'].apply(count_words)
feature_df['mention_cnt'] = feature_df['lemma_text'].apply(count_mention)
feature_df.head()
BoW 모형¶
BoW 모형을 다시 나이브베이즈 예측모형과 결합시켜 예측력을 높여본다. 이를 위해서 몇가지 사전 작업을 다음과 같이 진행한다.
CountVectorizer()생성자를 사용해서 BoW 객체를 생성한다.cv.fit_transform()은 훈련데이터에 적용하고,cv.transform()은 시험데이터에 적용시킨다.- BoW 객체를 X_train_bow.toarray()와 같이
.toarray()메쏘드를 통해서 배열로 변환시킨 후에 데이터프레임으로 변환시킨다..reset_index(drop=True, inplace=True)메쏘드를 통해서 두 데이터프레임 행결합을 준비한다.
pd.concat()메쏘드를 통해서 두 데이터프레임을 결합시킨다.
# 훈련/시험 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(feature_df, target, test_size=0.3)
# BoW 생성자
# cv = CountVectorizer(min_df=0.01, max_df=0.99)
cv = CountVectorizer(analyzer='word')
X_train_bow = cv.fit_transform(X_train['lemma_text'])
X_test_bow = cv.transform(X_test['lemma_text'])
# 훈련 데이터: 통계 데이터프레임 + BoW 데이터프레임 -----
X_train_vect_df = pd.DataFrame(X_train_bow.toarray(), columns=cv.get_feature_names()).add_prefix('Count_')
## 인덱스 정리
X_train.reset_index(drop=True, inplace=True)
X_train_vect_df.reset_index(drop=True, inplace=True)
## 통계 + BoW 결합
X_train_concat_df = pd.concat([X_train.drop(['lemma_text'], axis=1), X_train_vect_df], axis=1, sort=False)
X_train_concat_df = X_train_concat_df.fillna(0)
# 시험 데이터: 통계 데이터프레임 + BoW 데이터프레임 -----
X_test_vect_df = pd.DataFrame(X_test_bow.toarray(), columns=cv.get_feature_names()).add_prefix('Count_')
## 인덱스 정리
X_test.reset_index(drop=True, inplace=True)
X_test_vect_df.reset_index(drop=True, inplace=True)
## 통계 + BoW 결합
X_test_concat_df = pd.concat([X_test.drop(['lemma_text'], axis=1), X_test_vect_df], axis=1, sort=False)
X_test_concat_df = X_test_concat_df.fillna(0)
print(X_train_vect_df.shape, X_test_concat_df.shape)
X_train_concat_df.head()
기존 통계지표가 담긴 데이터프레임(X_train, X_test)과 BoW 모형이 결합된 데이터프레임을 결합시킨 후에 예측모형에 적합시킨다.
# 예측모형 적합
clf = MultinomialNB()
# 분류모형 적합
clf.fit(X_train_concat_df, y_train)
# 모형 정확도
accuracy = clf.score(X_test_concat_df, y_test)
print(f"시험 데이터셋으로 검정한 감성 분류 예측모형 정확도: {accuracy:.3f}")