감성분석 빅픽쳐¶
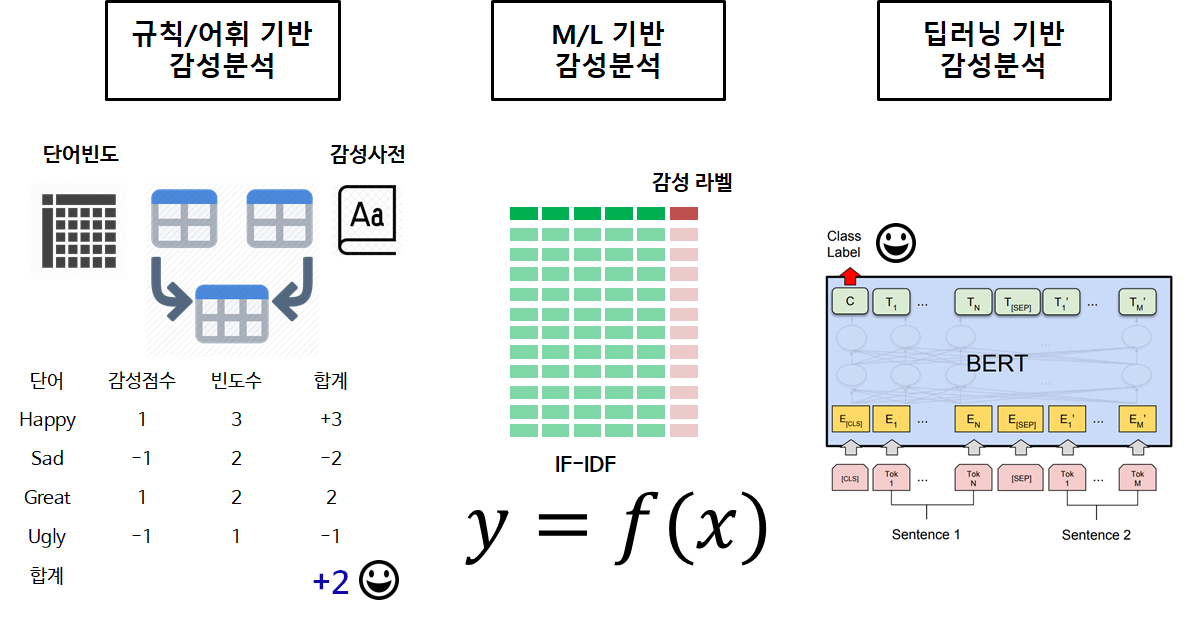
감성분석(sentiment analysis) 은 특정 주제에 대하여 저자의 견해를 이해하는 과정으로 정의된다. 감성분석은 또한 텍스트에서 담긴 감성에 대한 사항을 이해하고 예측하는 방법론을 통칭하는데 크게 다음과 같은 두가지 방법론 세부적으로 나누면 세가지 방법론으로 나눌 수도 있다.
따라서 감성분석은 세가지 구성요소로 이뤄진다. 즉, 누가(저자) 어떤 주제(Subject)에 대한 견해(Opinion)와 감정(Emotion)을 텍스트에 담았는지 이해하고 예측하는 것이다.
- 저자(Author)
- 주제(Subject)
- 견해(Opinion)/감정(Emotion)
감성분석이 중요해지는 이유는 고객이나 유권자가 무슨 주제에 대해서 어떤 감정을 가지고 어떻게 텍스트를 통해서 정보를 주고 받는지 기계를 동원해서 이해해야 하는데 텍스트를 통한 데이터가 방대하다.
- SNS
- 콜센터
- 제품/서비스 분석
- 브랜드 평판 관리
- ...
또한, 텍스트 데이터가 다양한 형태로 존재하기 때문에 어떤 수준에서 분석할지도 고민할 필요가 있다.
- 책/저널/카탈로그
- 문서 (Document)
- 문단 (Paragraph)
- 문장 (Sentence)
- 측면 (Aspect)
규칙/어휘 기반 감성분석¶
규칙/어휘(lexicon) 기반 감성분석은 어휘(lexicon)에 기반하고 있기 때문에 전처리가 특히 중요하다.
- 상당부분 텍스트 데이터를 인터넷을 통해 입수하기 때문에 HTML 태그와 같은 마크다운 문법과 연관된 태그는 모두 제거한다.
- Non-Ascii 문자 액센트가 붙어있어 있는 단어를 어휘 사전에서 매칭이 가능한 형태로 변환시킨다; $\^{o}$ → $o$
- 축약된 단어 풀기; don't → do not, I'd → I would 혹은 I could
- 특수문자 제거
- 어근 추출(stemming) 혹은 표제어 추출(lemmatization)
- 불용어 제거(stopwords)
상기 전처리 작업이 완료된 후에야 파이썬에서 많이 사용되는 어휘사전(lexicon)을 활용하여 감성분석을 수행할 수 있다.
- Bing Liu’s lexicon
- MPQA subjectivity lexicon
- Pattern lexicon
- TextBlob lexicon
- AFINN lexicon
- SentiWordNet lexicon
- VADER lexicon
Bing Lui 어휘사전¶
Bing Lui 어휘사전은 6,800개 단어로 구성되어 있는데 positive-words.txt는 2,000 단어/구문, negative-words.txt에는 4,800 단어/구문이 포함되어 있다. Opinion Mining, Sentiment Analysis, and Opinion Spam Detection 웹사이트에 자세한 내용을 확인할 수 있다.
TextBlob 어휘사전¶
TextBlob, "Tutorial: Quickstart"을 참조하여 TextBlob 클래스를 활용하여 감성분석을 수행할 수 있다. TextBlob 어휘사전은 GitHub에서 확인할 수 있다.
from textblob import TextBlob
wiki = TextBlob("Python is a high-level, general-purpose programming language.")
testimonial = TextBlob("Textblob is amazingly simple to use. What great fun!")
# 감성 출력
print('Sentiment of wiki: ', wiki.sentiment)
print('Sentiment of wiki: ', testimonial.sentiment)
import pandas as pd
df = pd.read_csv("data/twitter_sentiment_train.csv", encoding = "ISO-8859-1")
df.columns = ["item_id", "sentiment", "text"]
df.head()
판다스 데이터프레임에 저장된 text를 쭉 뽑아서 TextBlob 어휘사전을 활용하여 각각의 감성을 추출해보자. 너무 많아서 5개만 추려서 실제 Sentiment와 감성점수(Predicted Sentiment polarity)를 비교해보자.
for index, row in df.loc[0:4, :].iterrows():
text = row['text']
print(f'Text {index} : {text.strip()}')
print('Sentiment:', row['sentiment'])
print('Predicted Sentiment polarity:', TextBlob(text).sentiment.polarity)
print('-'*60)
AFINN 어휘사전¶
AFINN 어휘사전은 감성분석에 가장 단순하면서도 많이 사용되는 어휘사전이다. AFINN 어휘사전은 AFINN-11 버전을 Github에 올려놓고 afinn 라이브러리를 제작하여 공개했다.
# !pip install afinn
from afinn import Afinn
afn = Afinn(emoticons=True)
for index, row in df.loc[0:4, :].iterrows():
text = row['text']
print(f'Text {index} : {text.strip()}')
print('Sentiment:', row['sentiment'])
print('Predicted Sentiment polarity:', afn.score(text)
)
print('-'*60)
VADER 어휘사전¶
VADER(Valence Aware Dictionary and sEntiment Reasoner)에 대한 자세한 사항은 Hutto, C.J., and Gilbert, E.E. (2014),"VADER:
A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text" fproceedings of the Eighth International Conference on Weblogs and Social Media (ICWSM-14).에서 확인할 수 있다. VADER Github에 공개되어 있으며 nltk. sentiment.vader 모듈에 구현되어 있어 이를 불러 사용해도 좋다.
# ! pip install vaderSentiment
# import nltk
# nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyser = SentimentIntensityAnalyzer()
def vader_polarity(text):
""" Transform the output to a binary 0/1 result """
score = analyser.polarity_scores(text)
return 1 if score['pos'] > score['neg'] else 0
for index, row in df.loc[0:4, :].iterrows():
text = row['text']
print(f'Text {index} : {text.strip()}')
print('Sentiment:', row['sentiment'])
print('Predicted Sentiment polarity:', analyser.polarity_scores(text))
print('Predicted Sentiment polarity Class:', vader_polarity(text))
print('-'*60)
SentiWordNet 어휘사전¶
WordNet은 영어에 대한 가장 인기있는 말뭉치 중 하나다. WordNet은 자연어처리와 의미론 분석(semantic analysis)에 많이 활용되고, SentiWordNet 어휘사전은 감성분석에 자주 사용된다. SentiWordNet 웹사이트를 통해 자세한 사항을 접할 수 있으며 역시 nltk 라이브러리를 활용해서 활용이 가능하다.
# import nltk
# nltk.download('wordnet')
# nltk.download('sentiwordnet')
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet as wn
from nltk.corpus import sentiwordnet as swn
from nltk import sent_tokenize, word_tokenize, pos_tag
lemmatizer = WordNetLemmatizer()
def penn_to_wn(tag):
"""
Convert between the PennTreebank tags to simple Wordnet tags
"""
if tag.startswith('J'):
return wn.ADJ
elif tag.startswith('N'):
return wn.NOUN
elif tag.startswith('R'):
return wn.ADV
elif tag.startswith('V'):
return wn.VERB
return None
def clean_text(text):
text = text.replace("<br />", " ")
# text = text.decode("utf-8")
return text
def swn_polarity(text):
"""
Return a sentiment polarity: 0 = negative, 1 = positive
"""
sentiment = 0.0
tokens_count = 0
text = clean_text(text)
raw_sentences = sent_tokenize(text)
for raw_sentence in raw_sentences:
tagged_sentence = pos_tag(word_tokenize(raw_sentence))
for word, tag in tagged_sentence:
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN, wn.ADJ, wn.ADV):
continue
lemma = lemmatizer.lemmatize(word, pos=wn_tag)
if not lemma:
continue
synsets = wn.synsets(lemma, pos=wn_tag)
if not synsets:
continue
# Take the first sense, the most common
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentiment += swn_synset.pos_score() - swn_synset.neg_score()
tokens_count += 1
# judgment call ? Default to positive or negative
if not tokens_count:
return 0
# sum greater than 0 => positive sentiment
if sentiment >= 0:
return 1
# negative sentiment
return 0
for index, row in df.loc[0:4, :].iterrows():
text = row['text']
print(f'Text {index} : {text.strip()}')
print('Sentiment:', row['sentiment'])
print('Predicted Sentiment polarity:', swn_polarity(text))
print('-'*60)