앙상블(ensemble) 모형¶
서로 다른 특성을 갖는 이질적인 모형(heterogeneous model)을 분류문제(classification)에 대해서 투표(voting)를 통해 예측모형을 개발하거나 평균을 내서 구축한 모형이 단일 모형을 사용하는 경우보다 훨씬 더 좋은 예측성능을 내고 있다.
최적 단일 모형을 개발하는 대신에 의사결정나무(decision tree) 모형을 다양하게 조합하여 예측력을 높이는 방법을 살펴보자.
| 동질적인 모형 조합 | 이질적인 모형 조합 |
|---|---|
| 동일한 약한 모형 | 튜닝된 이질적인 모형 |
추정 모형(n_estimators 숫자) 많음 |
서로 다른 특성을 갖는 3~5개 정도 모형 |
| 배깅과 부스팅 | 투표(Voting), 평균(Averaging), 스태킹(Stacking) |
기본 예측모형¶
분류(classification)나 회귀(regression) 모형의 경우 데이터의 전처리 작업이 완료되었다고 가정하고 나면 훈련/시험 데이터셋으로 구분하고 이를 다양한 예측모형을 적합시켜 기본 예측모형을 개발한다.
데이터 가져오기¶
캐글 Mushroom Classification, Safe to eat or deadly poison? 웹사이트에서 버섯 분류 모형을 개발해보자. 이를 위해서 데이터 다운로드 받아 압축을 풀고 "data/mushrooms.csv" 저장한다. 그리고, 가장 별점을 많이 받은 Comparing Various ML models(ROC curve comparison) 코드를 참조해 기계학습 예측모형에 필요한 전처리 작업 준비를 한다.
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
data = pd.read_csv("data/mushrooms.csv")
data.head(6)
데이터 전처리¶
버섯종별로 식용 버섯과 독버섯으로 나눠져 있는데 모두 문자열(string)로 되어 있어 이를 일괄적으로 숫자로 변환시킨다.
from sklearn.preprocessing import LabelEncoder
labelencoder=LabelEncoder()
for col in data.columns:
data[col] = labelencoder.fit_transform(data[col])
data.head()
훈련/시험 데이터 분리¶
다음으로 데이터프레임을 훈련 데이터와 시험데이터로 구분한다.
그리고, X 데이터프레임을 정규화시켜 특정 변수가 척도(scale) 때문에 예측에 영향을 과도하게 미치는 것을 방지시킨다.
X = data.iloc[:,1:23] # all rows, all the features and no labels
y = data.iloc[:, 0] # all rows, label only
X.head()
y.head()
# Scale the data to be between -1 and 1
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=777)
단일 예측모형¶
분류문제(classification)에 대해서 가장 많이 알려진 의사결정나무, 로지스틱 회귀모형, 나이브 베이즈, K-이웃 분류모형, SVM을 각각 적합시켜본다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
# 예측모형 초기화
clf_knn = KNeighborsClassifier(5)
clf_dt = DecisionTreeClassifier()
clf_lr = LogisticRegression()
clf_svm = SVC()
clf_nb = GaussianNB()
# 예측모형 적합
clf_knn.fit(X_train, y_train)
clf_dt.fit(X_train, y_train)
clf_lr.fit(X_train, y_train)
clf_svm.fit(X_train, y_train)
clf_nb.fit(X_train, y_train)
# 예측값
pred_knn = clf_knn.predict(X_test)
pred_dt = clf_dt.predict(X_test)
pred_lr = clf_lr.predict(X_test)
pred_svm = clf_svm.predict(X_test)
pred_nb = clf_nb.predict(X_test)
# 성능
from sklearn.metrics import f1_score
score_knn = f1_score(y_test, pred_knn)
score_dt = f1_score(y_test, pred_knn)
score_lr = f1_score(y_test, pred_knn)
score_svm = f1_score(y_test, pred_knn)
score_nb = f1_score(y_test, pred_knn)
print(f'F1-Score - KNN: {score_knn:.3f}\
\nF1-Score - DT : {score_dt:.3f}\
\nF1-Score - LR : {score_lr:.3f}\
\nF1-Score - SVM : {score_svm:.3f}\
\nF1-Score - NB : {score_nb:.3f}')
앙상블 모형 - 투표와 평균¶
서로 다른 특성을 갖는 예측모형을 투표와 평균을 내는 방법을 살펴보자.
구글 앱 데이터¶
구글 앱 평점이 담긴 데이터를 캐글에서 다운로드 받는다. 그리고, Machine Learning to predict app ratings 코드를 참조하여 데이터를 정제한다.
목적은 구글 평점을 예측하는 회귀모형을 개발하는 것이다.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
df = pd.read_csv('data/googleplaystore.csv')
# 결측값 제거
df.dropna(inplace = True)
# Categories --> 숫자
CategoryString = df["Category"]
categoryVal = df["Category"].unique()
categoryValCount = len(categoryVal)
category_dict = {}
for i in range(0,categoryValCount):
category_dict[categoryVal[i]] = i
df["Category_c"] = df["Category"].map(category_dict).astype(int)
# Size --> 숫자
def change_size(size):
if 'M' in size:
x = size[:-1]
x = float(x)*1000000
return(x)
elif 'k' == size[-1:]:
x = size[:-1]
x = float(x)*1000
return(x)
else:
return None
df["Size"] = df["Size"].map(change_size)
#filling Size which had NA
df.Size.fillna(method = 'ffill', inplace = True)
#Cleaning no of installs classification
df['Installs'] = [int(i[:-1].replace(',','')) for i in df['Installs']]
#Converting Type classification into binary
def type_cat(types):
if types == 'Free':
return 0
else:
return 1
df['Type'] = df['Type'].map(type_cat)
#Cleaning of content rating classification
RatingL = df['Content Rating'].unique()
RatingDict = {}
for i in range(len(RatingL)):
RatingDict[RatingL[i]] = i
df['Content Rating'] = df['Content Rating'].map(RatingDict).astype(int)
#dropping of unrelated and unnecessary items
df.drop(labels = ['Last Updated','Current Ver','Android Ver','App'], axis = 1, inplace = True)
#Cleaning of genres
GenresL = df.Genres.unique()
GenresDict = {}
for i in range(len(GenresL)):
GenresDict[GenresL[i]] = i
df['Genres_c'] = df['Genres'].map(GenresDict).astype(int)
#Cleaning prices
def price_clean(price):
if price == '0':
return 0
else:
price = price[1:]
price = float(price)
return price
df['Price'] = df['Price'].map(price_clean).astype(float)
# convert reviews to numeric
df['Reviews'] = df['Reviews'].astype(int)
# Categories --> 가변수
app_df = pd.get_dummies(df, columns=['Category'])
# 훈련/시험 데이터셋
X = app_df.drop(labels = ['Rating','Genres','Category_c','Genres_c'], axis = 1)
y = app_df.Rating
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=777)
X_train.head()
첫번째 앙상블 모형¶
앞선 분류기 대신 회귀모형(regression) 예측모형을 각각 정리하고 이를 estimators라는 튜플 리스트로 모형라벨과 모형객체를 담아 VotingRegressor() 에 넣어 훈련시키고 성능을 살펴본다. RMSE 값을 기억했다가 나중에 더 성능 좋은 모형과 비교한다.
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.ensemble import VotingRegressor, VotingClassifier
from sklearn.metrics import mean_squared_error
reg_dt = DecisionTreeRegressor()
reg_lr = LinearRegression(normalize=True)
reg_svm = SVR()
estimators = [('dt', reg_dt), ('lr', reg_lr), ('svm', reg_svm)]
# 평점 예측 모형
reg_rating = VotingRegressor(estimators)
reg_rating.fit(X_train, y_train)
reg_pred = reg_rating.predict(X_test)
# 예측모형 성능
reg_rmse = np.sqrt(mean_squared_error(y_test, reg_pred))
print(f'구글 앱 평점 예측 RMSE: {reg_rmse:.3f}')
약한 모형 (Weak Model)¶
약한 모형(weak model) 은 성능이 임의로 추측하는 모형보다 성능이 좋으나 매우 가볍고 훈련과 모형평가 시간이 아주 짧은 특성을 갖는 것으로 정의되는데, 가장 널리 알려진 Weak Learner가 의사결정나무(decision tree)다.
판사 콩도르세 정리 (Condorcet's Jury Theorem)
임의로 추측한 약한 모형을 계속해서 추가해서 투표 혹은 평균을 내게 되면 정확도가 100%에 수렴한다는 정리로 모형은 독립적이며, 약한 모형 각각은 임의로 추측한 것보다 좋은 성능을 내며 약한 모형 각각은 유사한 성능을 갖는 것을 가정함.
참고: 콩도르세(1743-94: 프랑스 수학자·철학자)
의사결정나무(DecisionTreeRegressor)를 기반이 되는 약한 모형으로 설정하고 20개 부츠트랩 추정모형을 제작하여 배깅모형으로 예측한 결과 RMSE가 다소 감소한 것을 확인할 수 있다.
from sklearn.ensemble import BaggingRegressor
# 약한 모형
reg_dt = DecisionTreeRegressor(max_depth=3, min_samples_split=10, min_samples_leaf=5)
# 배깅 회귀모형
reg_bag = BaggingRegressor(
base_estimator = reg_dt,
n_estimators=20,
max_features=X_train.shape[1],
max_samples=0.7,
bootstrap=True,
random_state=777,
oob_score=True)
reg_bag.fit(X_train, y_train)
# 예측
bag_pred = reg_bag.predict(X_test)
# 예측모형 성능 비교
reg_bag_rmse = np.sqrt(mean_squared_error(y_test, bag_pred))
print(f'구글 앱 평점 예측 RMSE(Ensemble - Averaging): {reg_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Bagging) : {reg_bag_rmse:.3f}')
from sklearn.ensemble import AdaBoostRegressor
# 회귀모형
reg_lm = LinearRegression(normalize=True)
# 회귀 AdaBoost 알고리즘
reg_ada = AdaBoostRegressor(base_estimator=reg_lm,
n_estimators=100,
learning_rate=0.01,
random_state=777)
reg_ada.fit(X_train, y_train)
# 성능
ada_pred = reg_ada.predict(X_test)
# 예측모형 성능 비교
reg_ada_rmse = np.sqrt(mean_squared_error(y_test, ada_pred))
print(f'구글 앱 평점 예측 RMSE(Ensemble - Averaging): {reg_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Bagging) : {reg_bag_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - AdaBoost) : {reg_ada_rmse:.3f}')
GBM (Gradient Boosting Machine)¶
Gradient Boosting 계열 알고리즘은 진화에 진화를 거듭하고 있고 XGBoosting, LightGBM, CatBoost 가 구현된 최신 알고리즘이다.
- Extreme Gradient Boosting -
XGBoost - Light Gradient Boosting Machine -
LightGBM - Categorical Boosting -
CatBoost
XGBoost는 분산 컴퓨팅에 촛점을 맞춰 개발된 알고리즘이며, 2017년 마이크로소프트가 출시한 LightGBM은 속도와 효율성에 초점을 맞춰 빅데이터(메모리와 속도) 기계학습에 도움이 된다. CatBoost는 Yandex에서 2017년 4월 출시하여 이름에서도 알 수 있듯이 범주형 피쳐를 처리하여 예측성능을 높인다.
from sklearn.ensemble import GradientBoostingRegressor
reg_gbm = GradientBoostingRegressor(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
# min_samples_split=10,
# min_samples_leaf=10,
# max_features=X_train.shape[1]
)
reg_gbm.fit(X_train, y_train)
# 성능
gbm_pred = reg_gbm.predict(X_test)
# 예측모형 성능 비교
reg_gbm_rmse = np.sqrt(mean_squared_error(y_test, gbm_pred))
print(f'구글 앱 평점 예측 RMSE(Ensemble - Averaging): {reg_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Bagging) : {reg_bag_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - AdaBoost) : {reg_ada_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - GBM) : {reg_gbm_rmse:.3f}')
!pip install lightgbm 매직 명령어로 설치할 수 있으나, Visual Studio가 필요하여 VC runtime https://go.microsoft.com/fwlink/?LinkId=746572을 다운로드 받아 설치한다.
# LightGBM
import lightgbm as lgb
reg_lgb = lgb.LGBMRegressor(
n_estimators=100,
learning_rate=0.01,
max_depth=-1,
seed=500
)
reg_lgb.fit(X_train, y_train)
# 성능
lgb_pred = reg_lgb.predict(X_test)
# 예측모형 성능 비교
reg_lgb_rmse = np.sqrt(mean_squared_error(y_test, lgb_pred))
print(f'구글 앱 평점 예측 RMSE(Ensemble - Averaging): {reg_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Bagging) : {reg_bag_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - AdaBoost) : {reg_ada_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - GBM) : {reg_gbm_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Light GBM): {reg_lgb_rmse:.3f}')
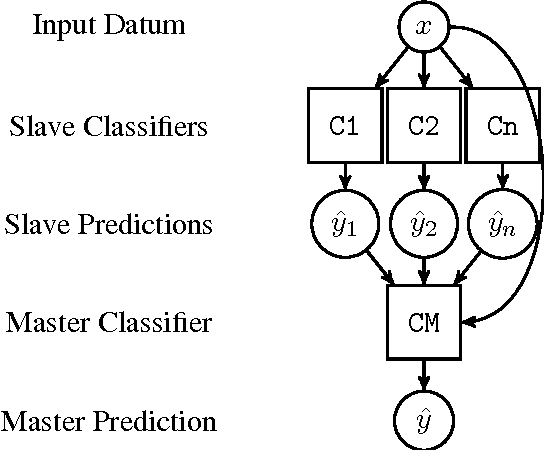
from mlxtend.regressor import StackingRegressor
# 예측모형 아키텍처
## 첫번째 계층 회귀모형
reg_dt = DecisionTreeRegressor()
reg_lr = LinearRegression(normalize=True)
reg_svm = SVR()
## 두번째 계층 회귀모형
reg_meta = LinearRegression(normalize=True)
# 스태킹 예측모형
reg_stack = StackingRegressor(
regressors=[reg_dt, reg_lr, reg_svm],
meta_regressor=reg_meta,
use_features_in_secondary=True)
reg_stack.fit(X_train, y_train)
# 성능
stack_pred = reg_stack.predict(X_test)
# 예측모형 성능 비교
reg_stack_rmse = np.sqrt(mean_squared_error(y_test, stack_pred))
print(f'구글 앱 평점 예측 RMSE(Ensemble - Averaging): {reg_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Bagging) : {reg_bag_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - AdaBoost) : {reg_ada_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - GBM) : {reg_gbm_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Light GBM): {reg_lgb_rmse:.3f}\
\n구글 앱 평점 예측 RMSE(Ensemble - Stack): {reg_stack_rmse:.3f}')