
데이터 과학
PDF 문서
PDF 문서
PDF 문서에서 원하는 데이터를 추출하는 방법은 다양한다. 먼저 PDF 파일에서 추출할 수 있는 데이터에 대해서 알아보자. PDF 파일에서 추출할 수 있는 데이터는 크게 4가지 방식으로 나눌 수 있다.
- PDF 파일에서 텍스트
- PDF 이미지에서 텍스트 추출
- 테이블 표 추출
- 이미지 추출 1
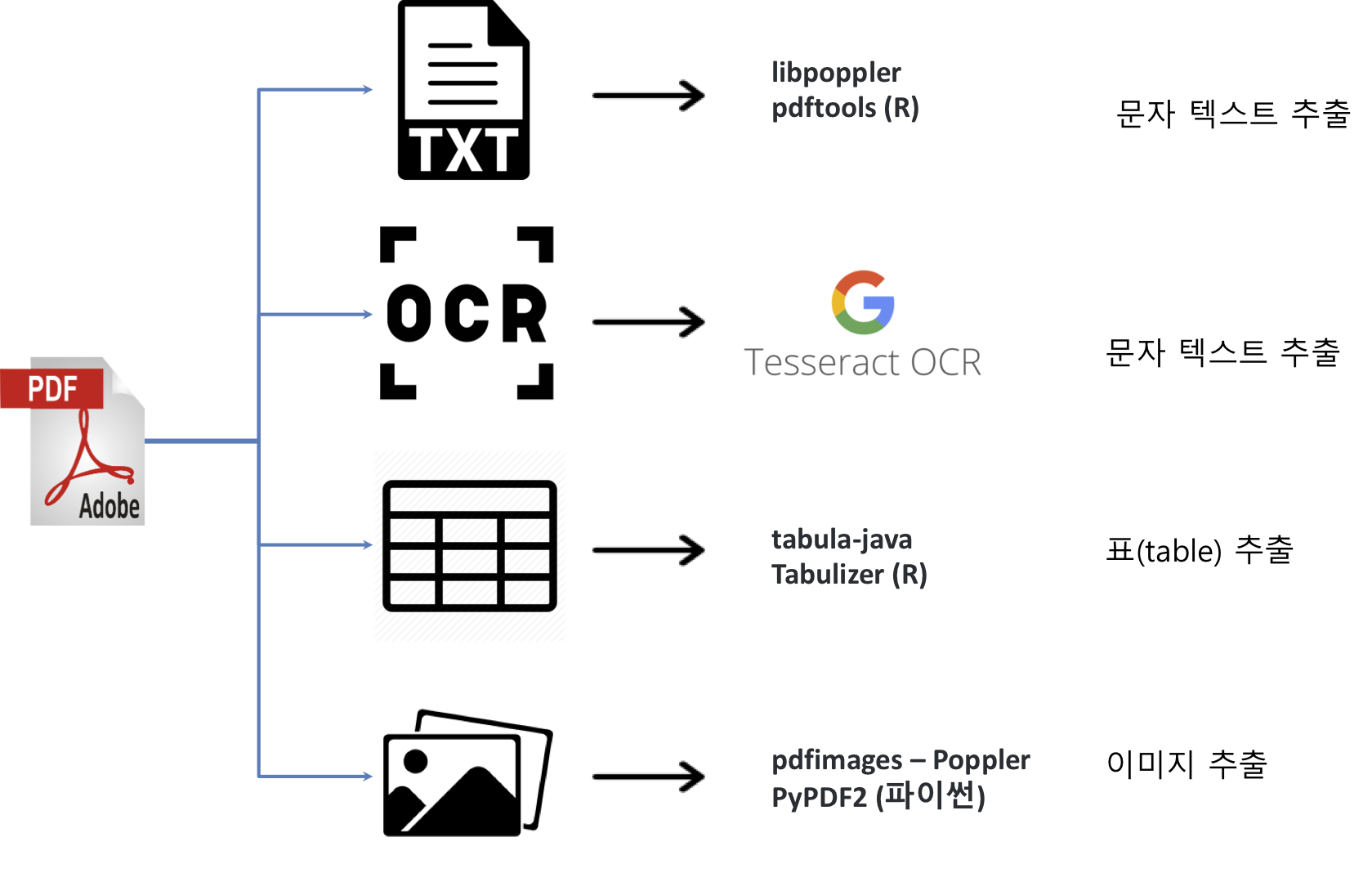
R 팩키지 pdftools를 활용하여 상당부분 작업을 할 수 있지만, 표를 추출할 경우 자바 기반의 tabulizer 팩키지, 이미지를 추출할 경우 리눅스 poppler 구성원인 pdfimages 도구를 쉘에서 실행시켜 구현한다.
PDF 일부 영역
PDF 파일이 텍스트, 이미지, 표 등으로 구분되어 있을 경우 이를 파이썬 Open CV 등 도구를 사용해서 이미지 PDF에서 특정 객체를 인식하여 추출한 후 이를 OCR 엔진에 넣어 표에 담긴 정보를 추출한다.