데이터과학 방법론 산업적용 현재와 미래
국가통계방법론 심포지엄: 국가통계의 현재와 미래
삼정 KPMG
이광춘
2020-09-24
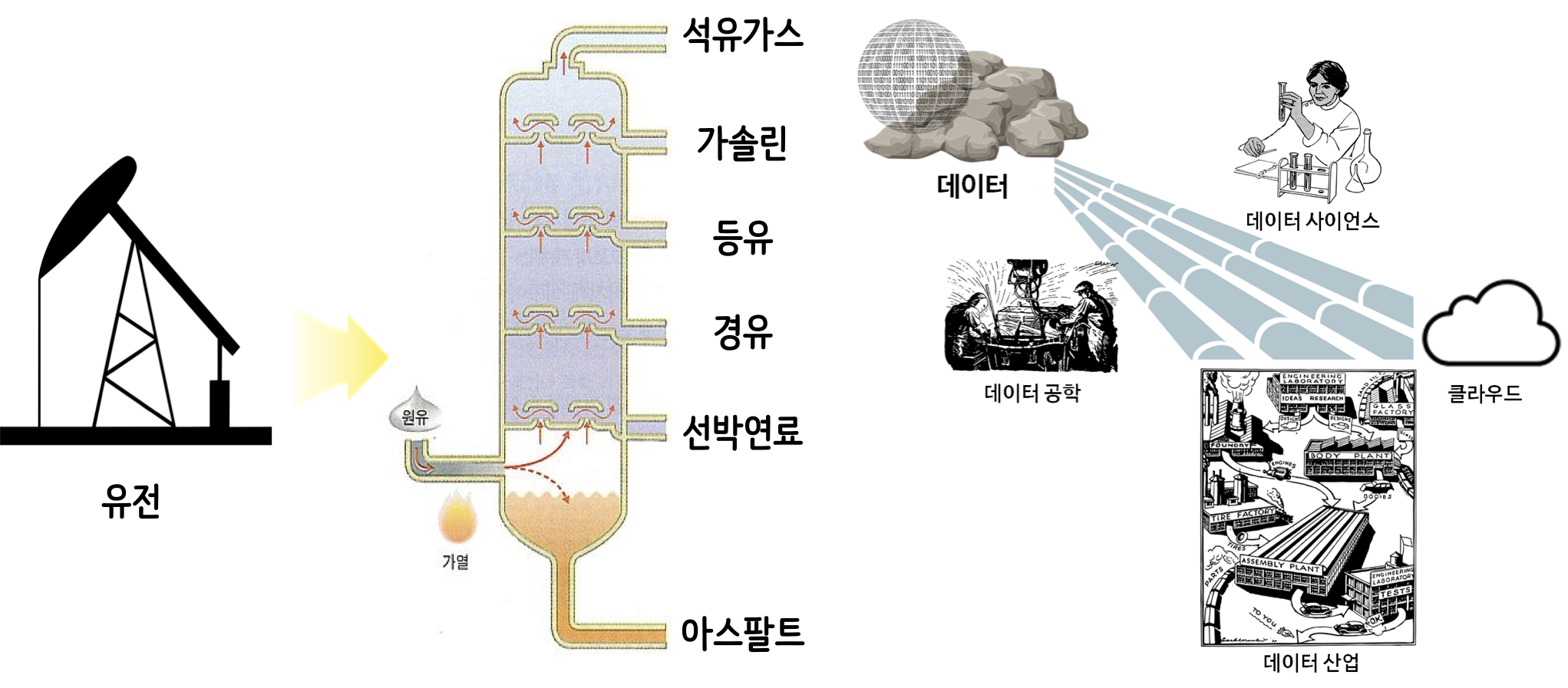
데이터 자원

파이프라인
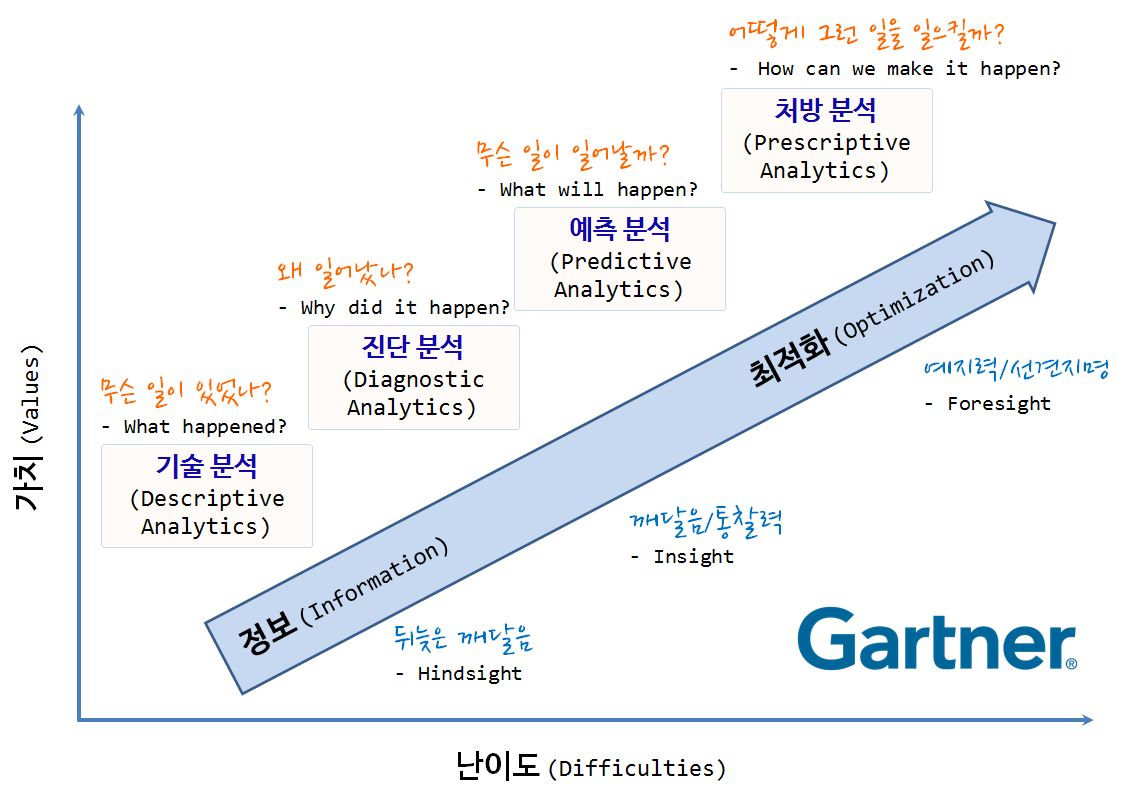
가치
- 기술 분석(Descriptive Analytics): 무슨 일이 있었나? (What happened?)
- 진단 분석(Diagnostic Analytics): 왜 일어났나? (Why did it happen?)
- 예측 분석(Predictive Analytics): 무슨 일이 일어날까? (What will happen?)
- 처방 분석(Prescriptive Analytics): 어떻게 그런 일을 일으킬까? (How can we make it happen?)
비용
자동화

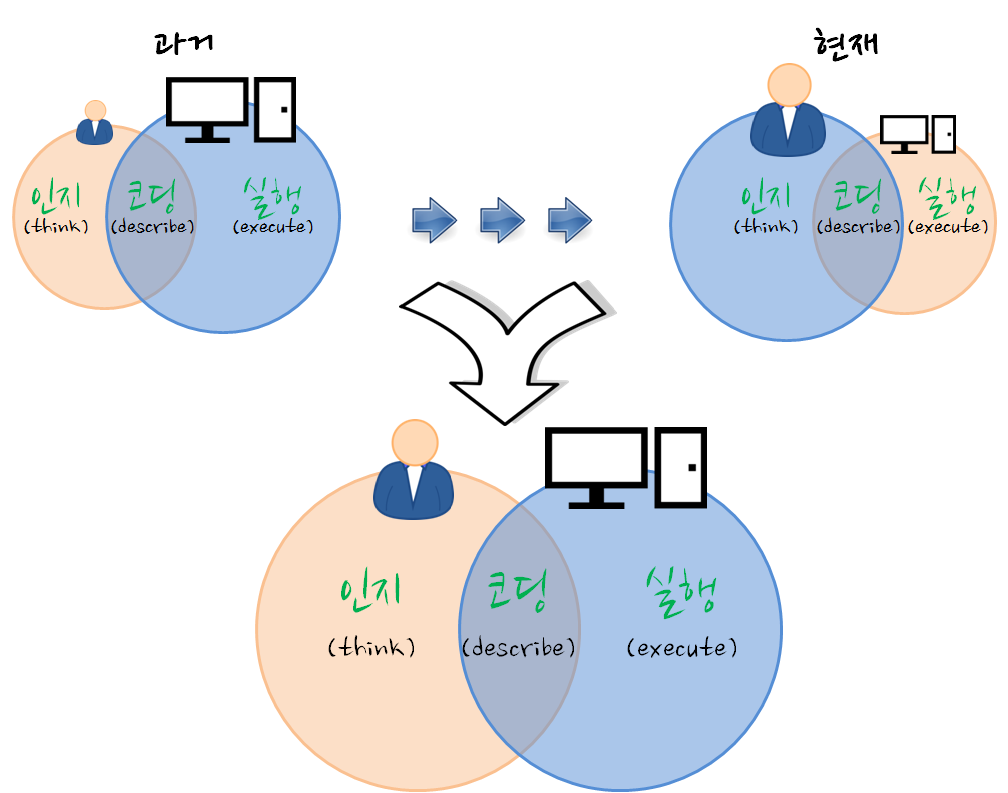
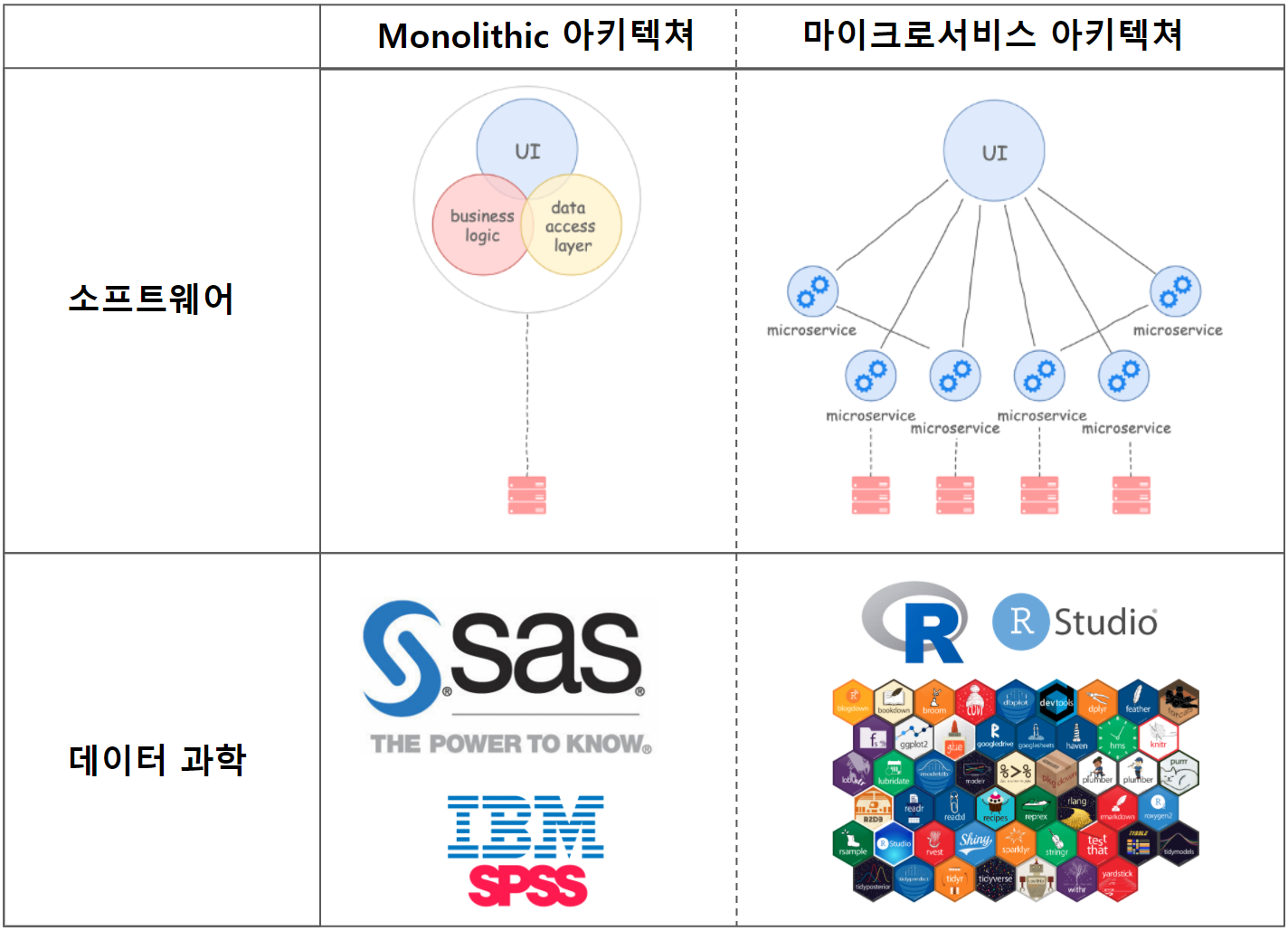
MSA
데이터 사이언스 운영체제
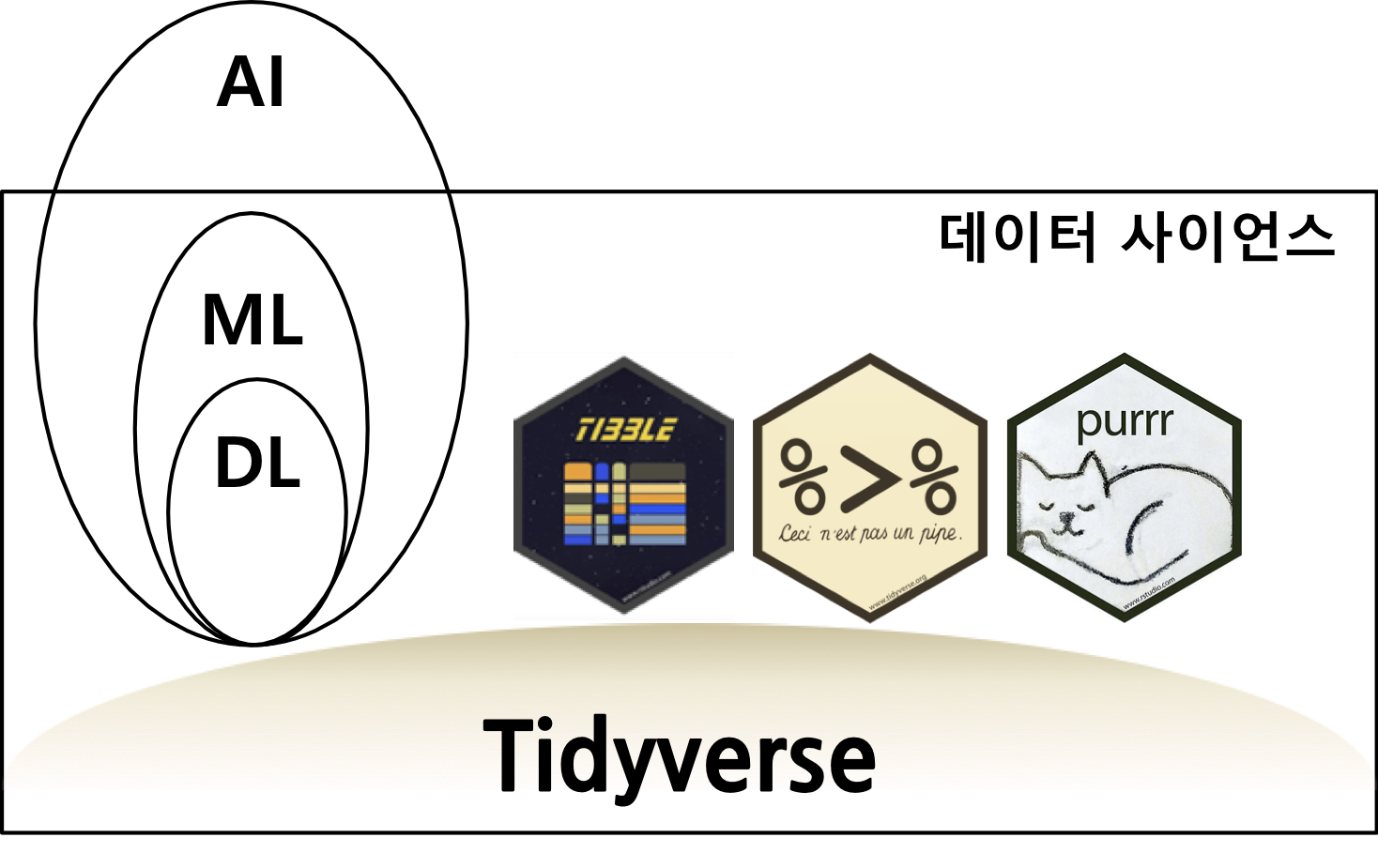
이광춘 ( 삼정 KPMG 상무), “데이터 사이언스 운영체제 - tidyverse”, 한국통계학회 소식지 2019년 10월호
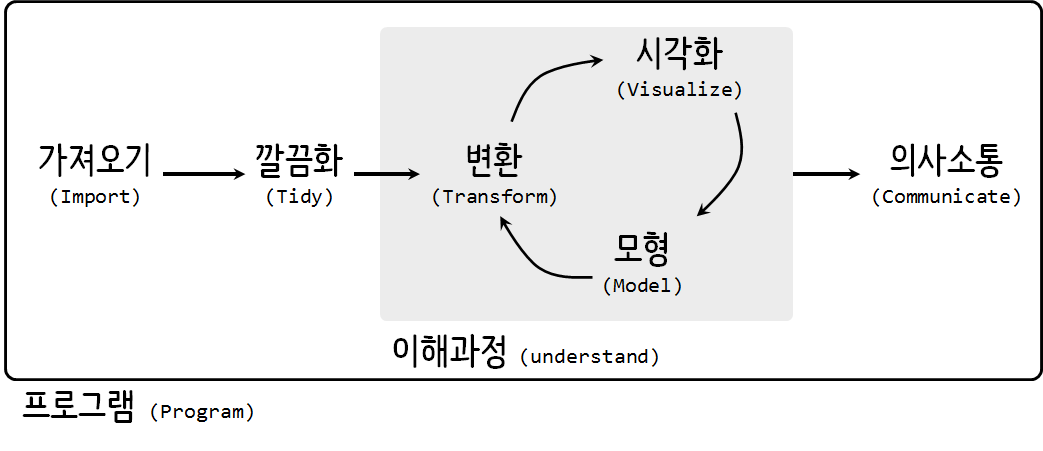
작업 흐름
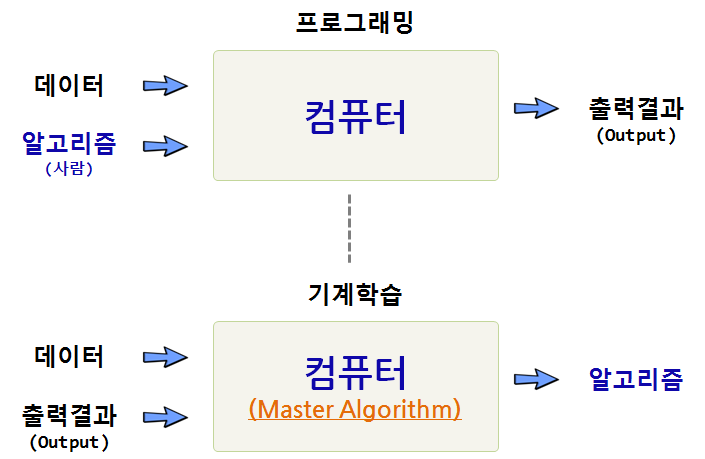
기계학습 알고리즘
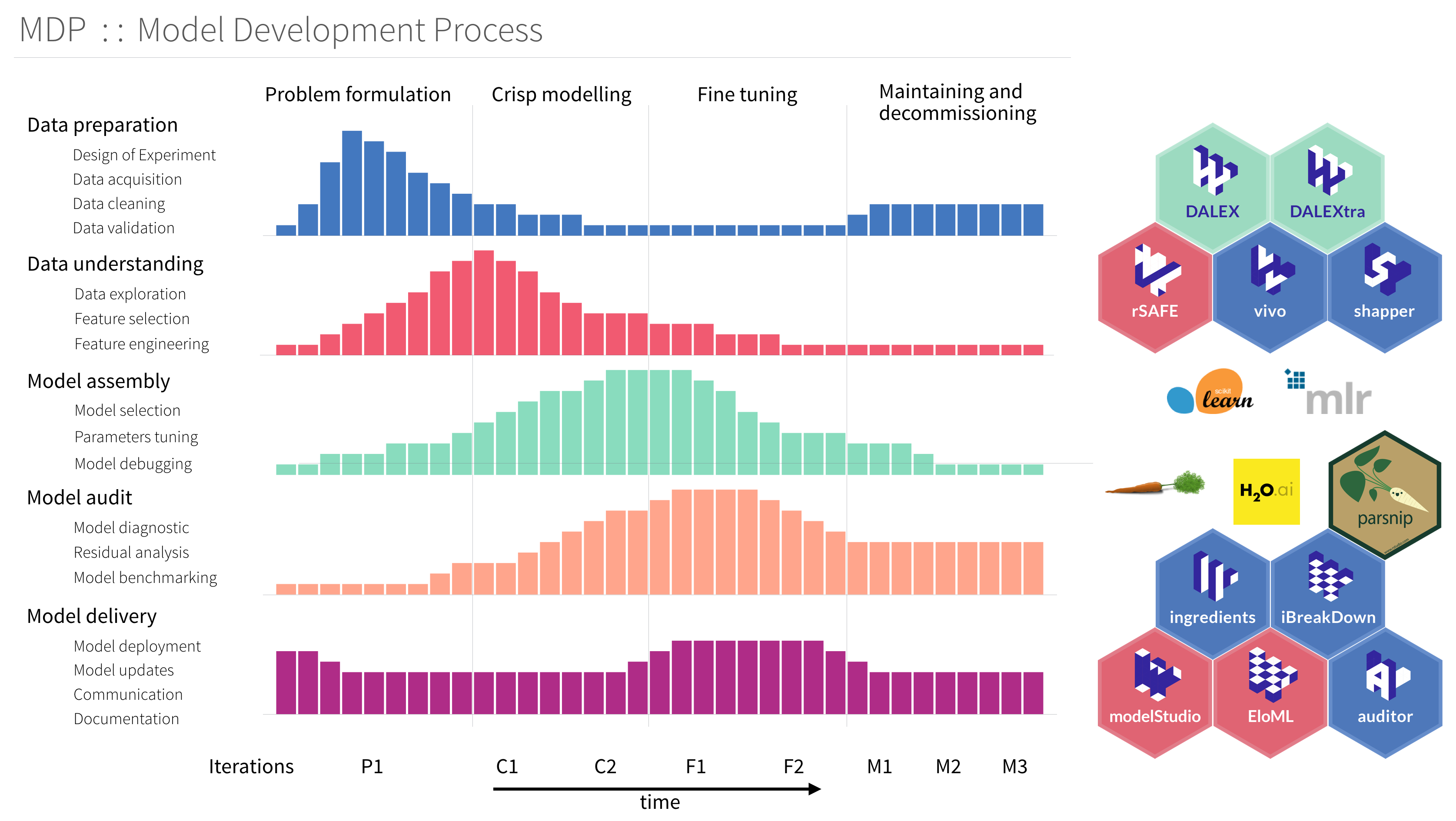
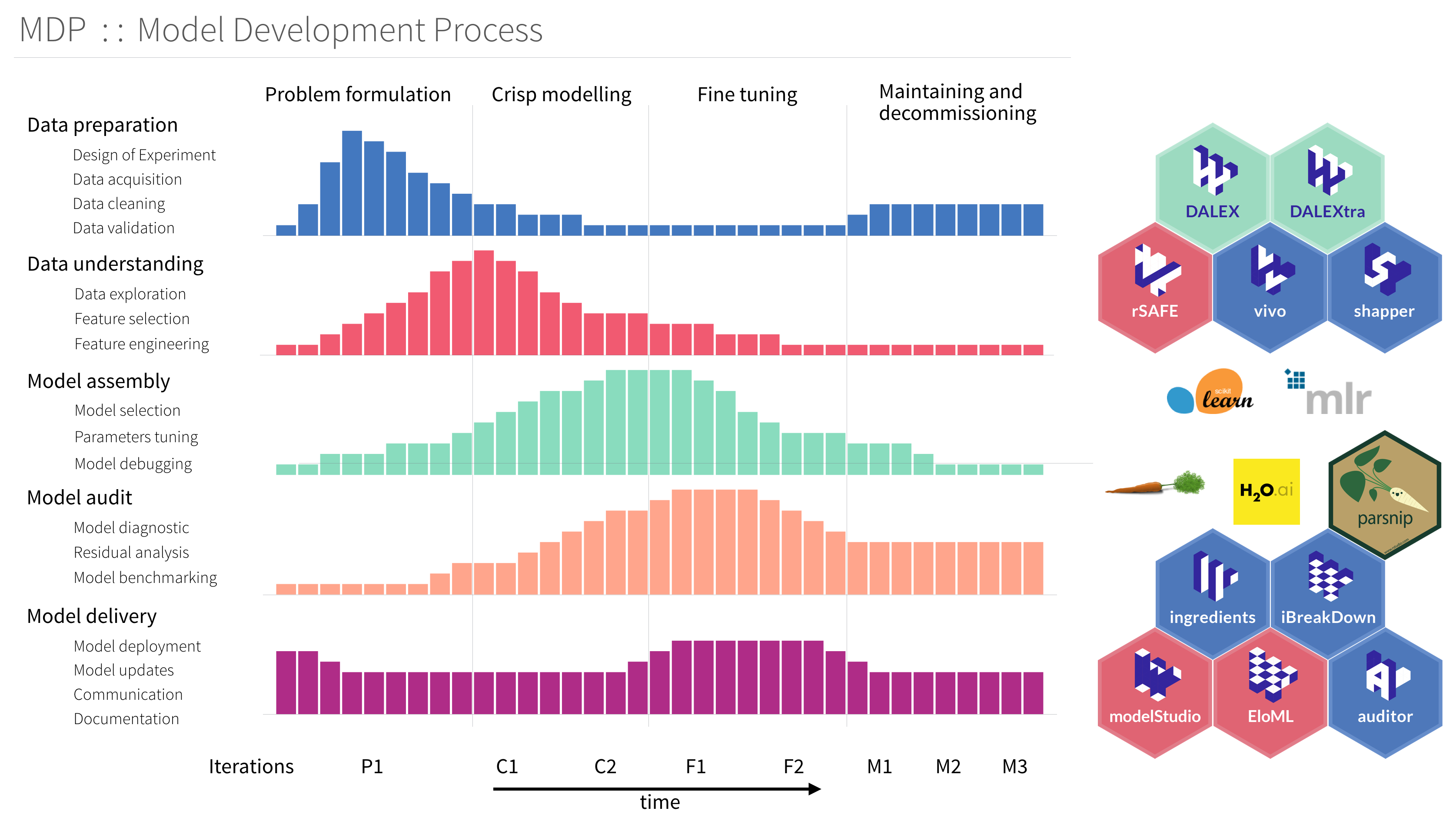
CRISP-DM → MDP
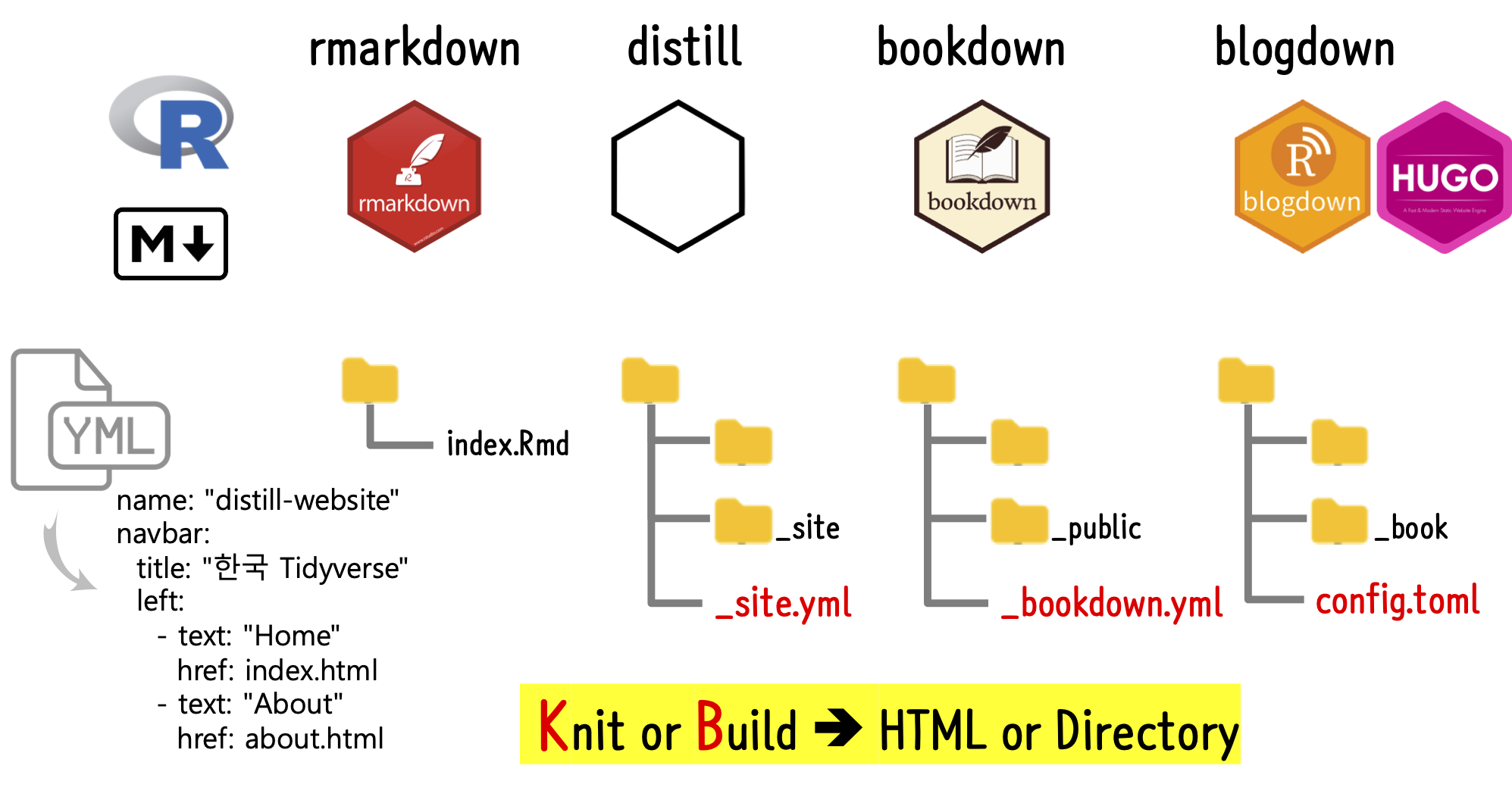
글쓰기 문법: Rmd
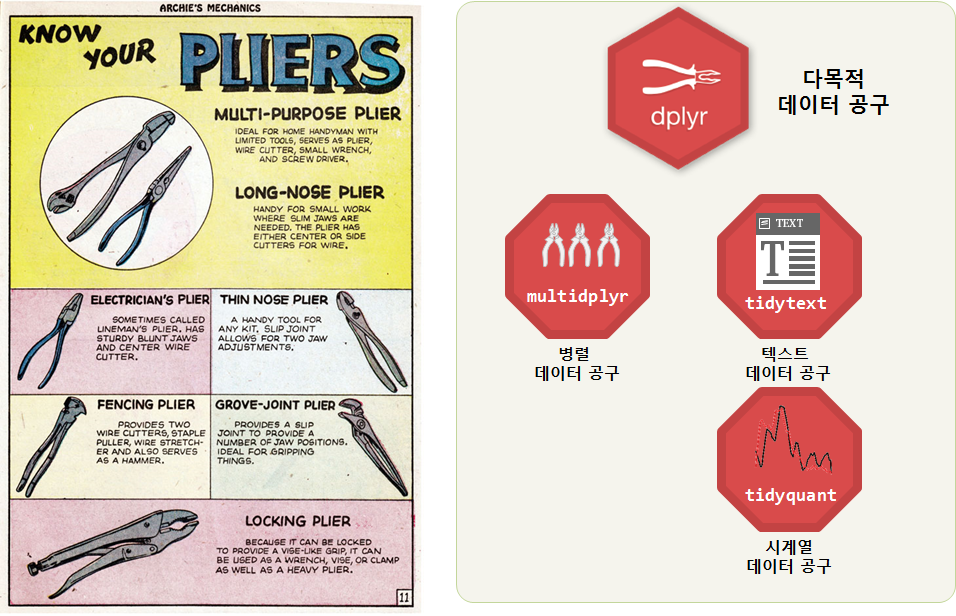
데이터 문법: dplyr
그래프 문법: ggplot2

테이블 문법: gt
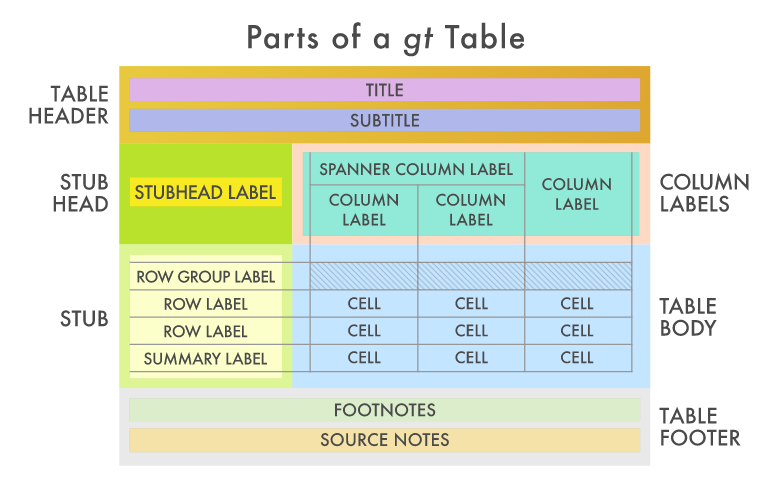
출처: https://statkclee.github.io/data-science/ds-table-gt-kable.html
텍스트 문법: tidytext
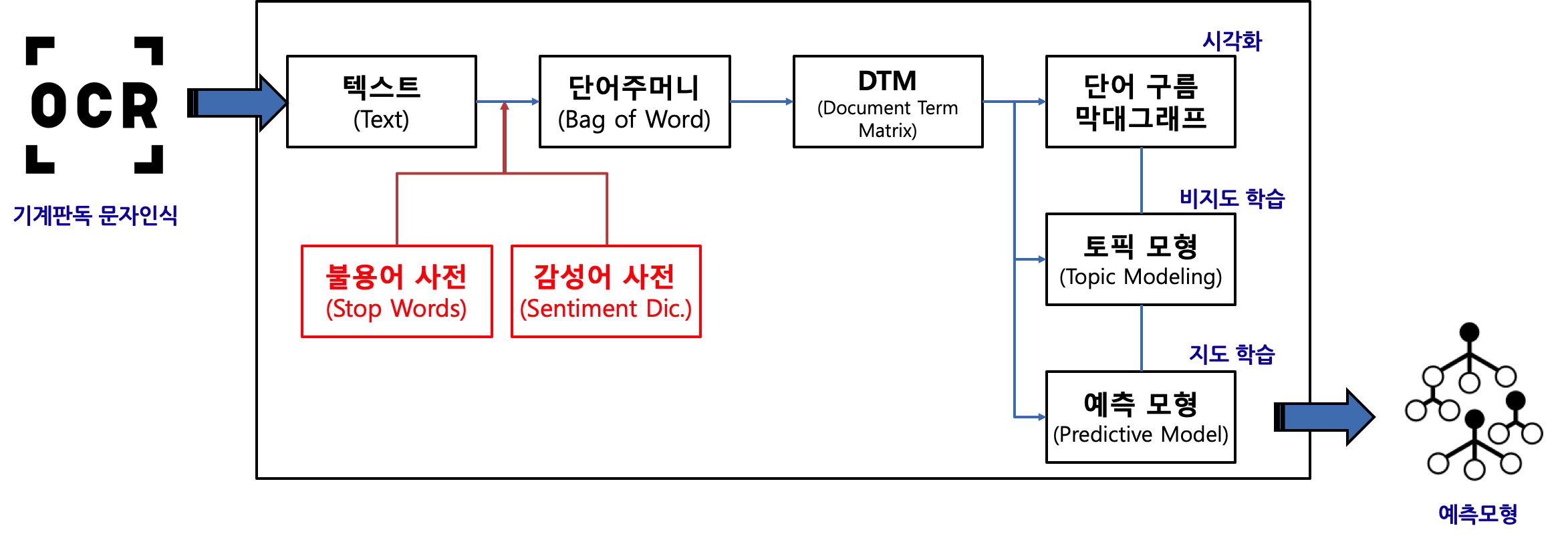
출처: https://statkclee.github.io/text/nlp-twitter-tidytext.html
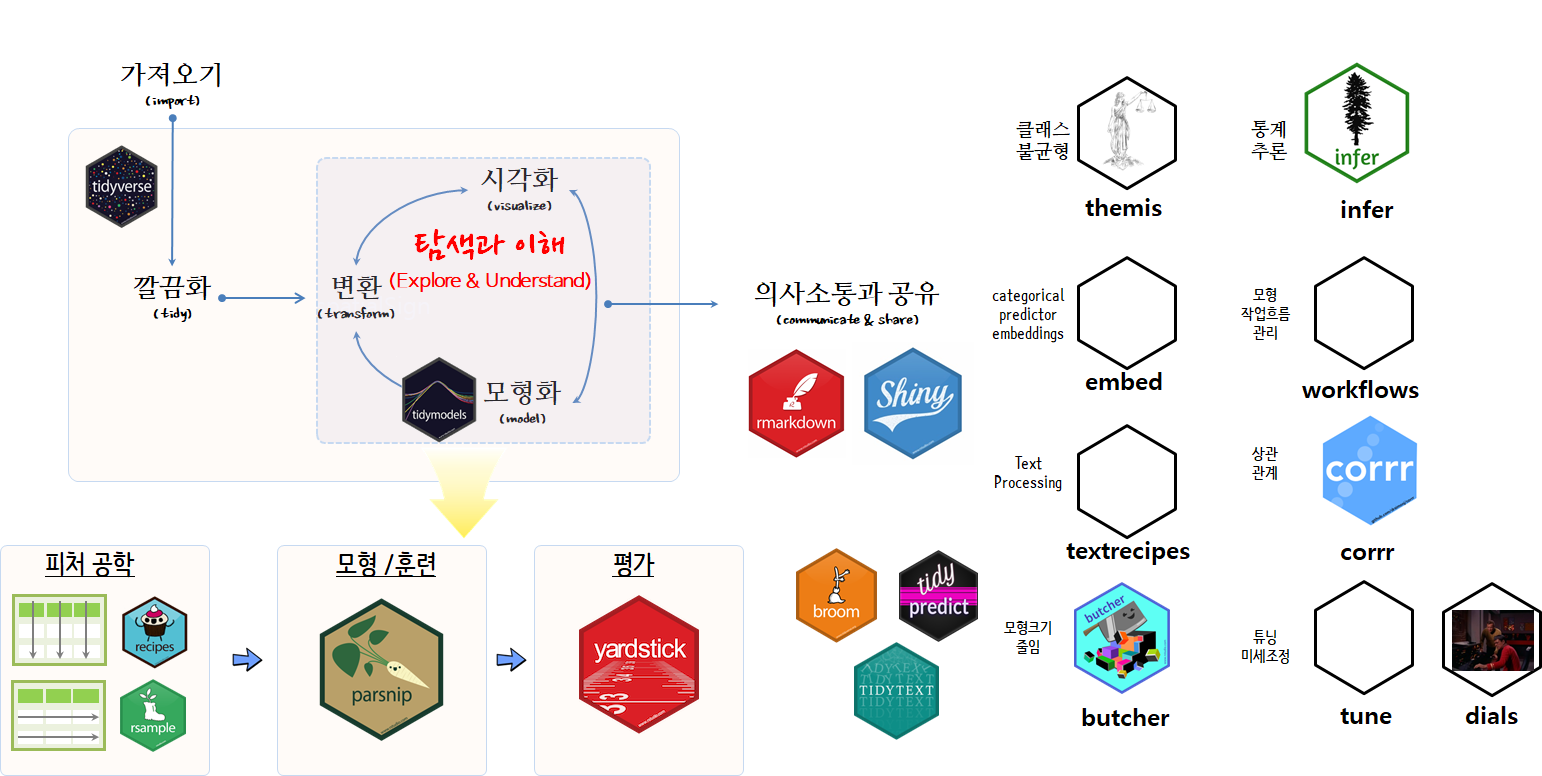
모형 문법: tidymodels
펭귄 데이터셋
탐색적 데이터 분석

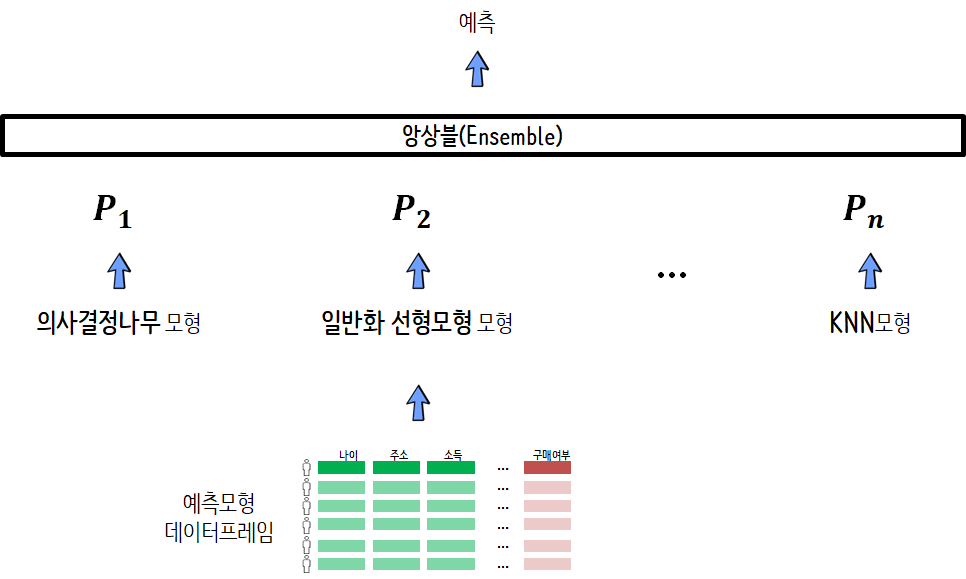
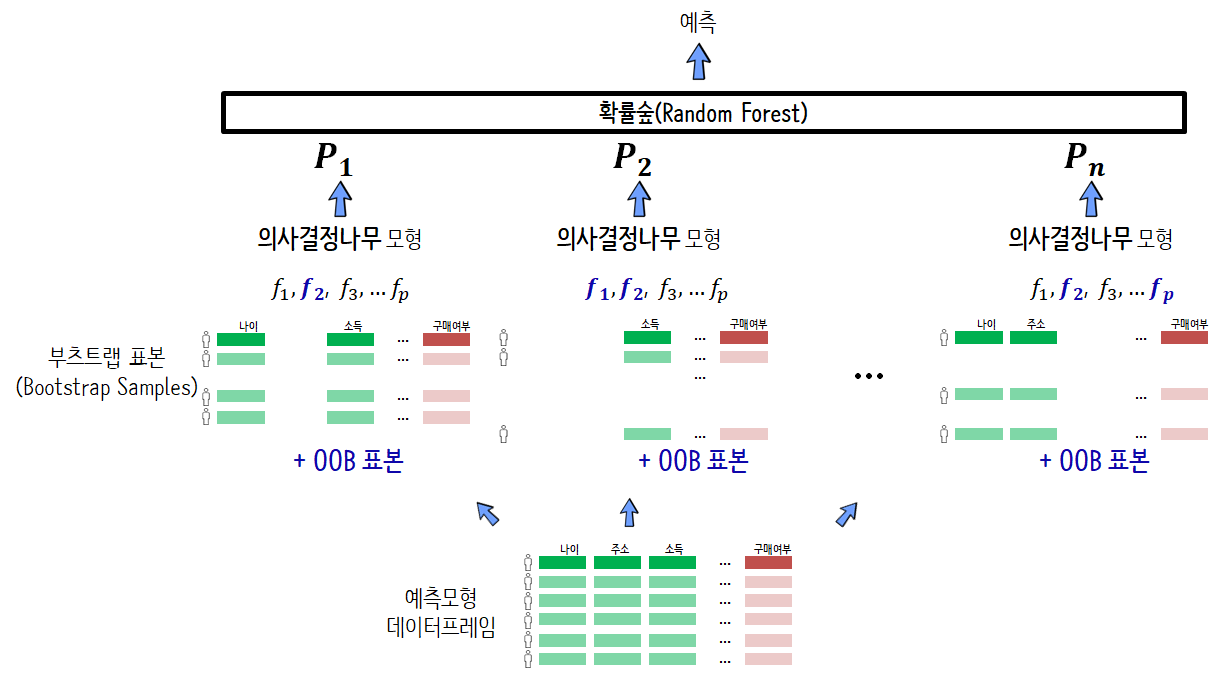
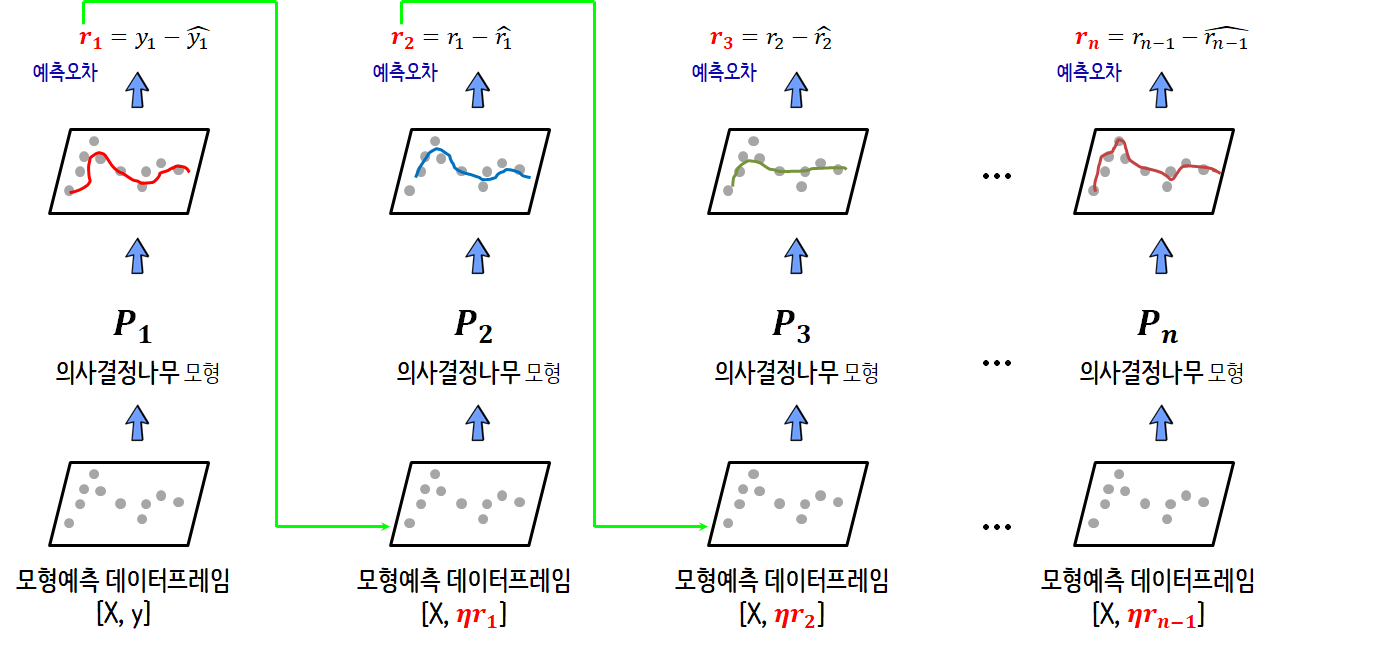
모형 아키텍쳐
| 앙상블 | Random Forest | XGBoost |
|---|---|---|
 |
 |
 |
모형 최적화: Hyper Parameter Tuning

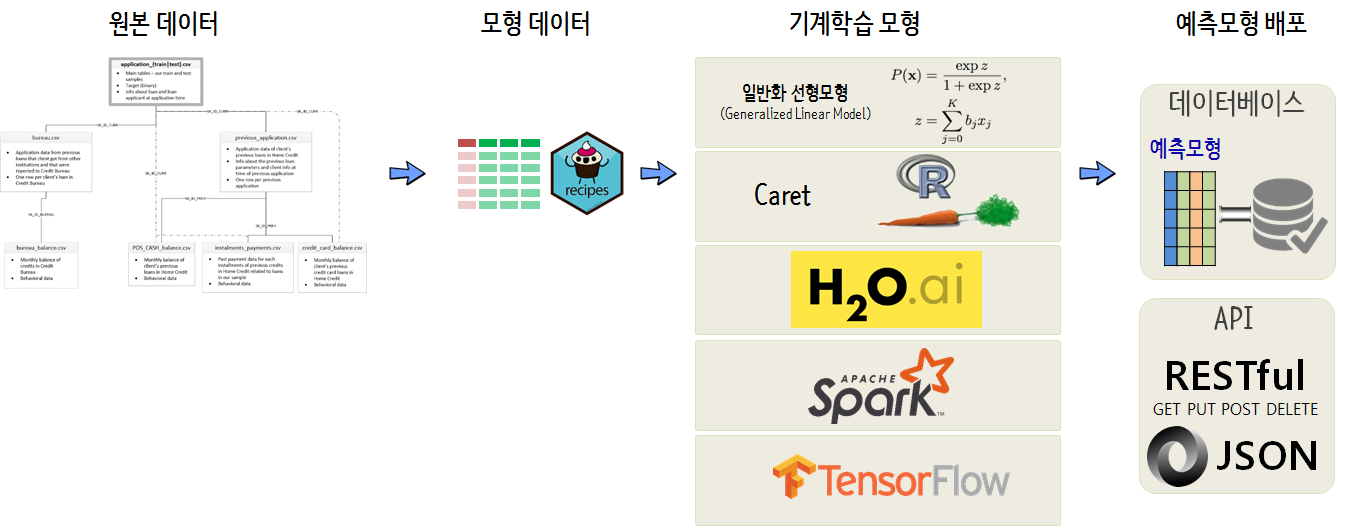
모형 배포: RESTful API
설명가능한 예측모형: Explainable AI
tidyposterior 모형 평가
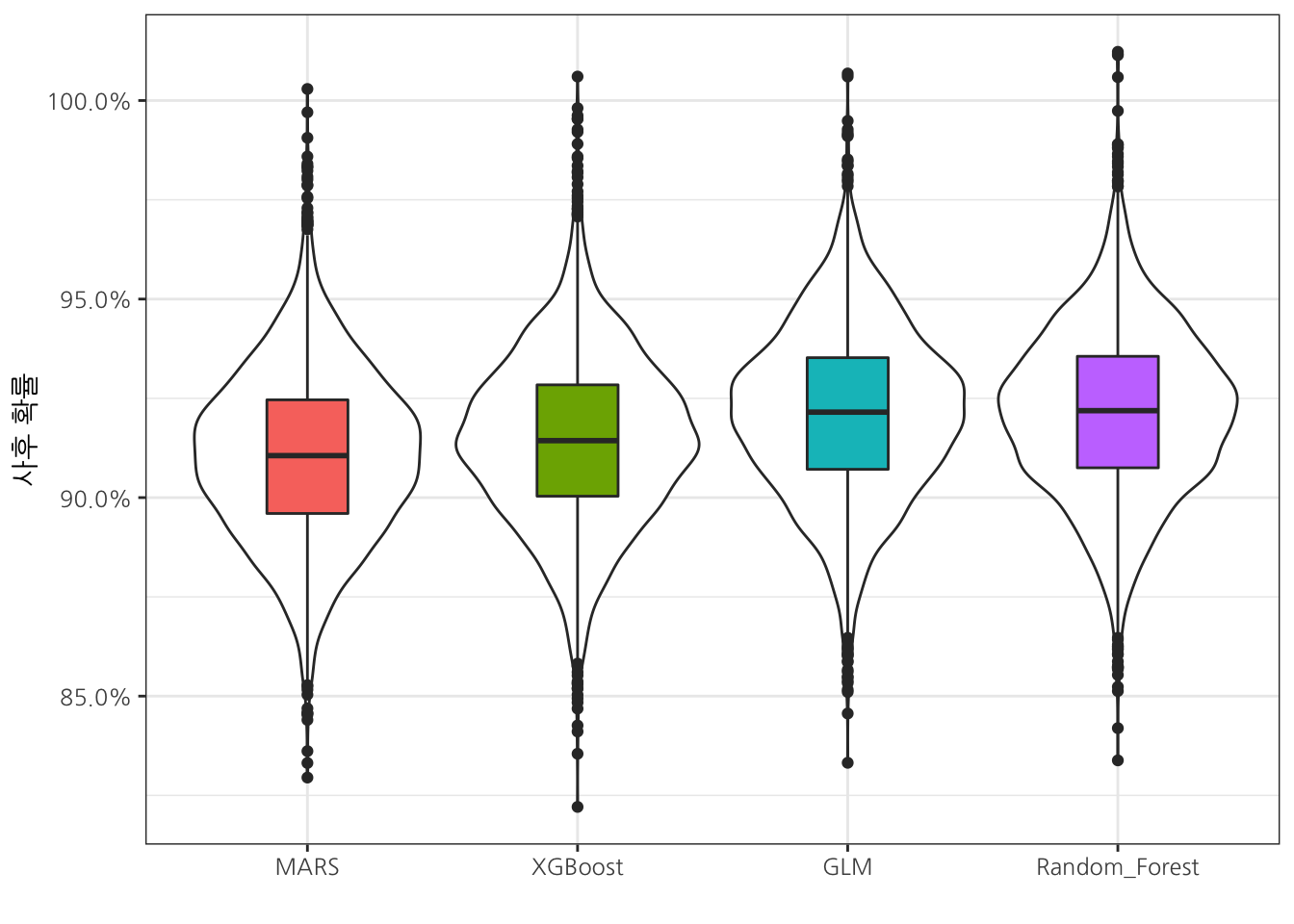
예측모형 모의평가: Shiny