관계형 데이터베이스¶
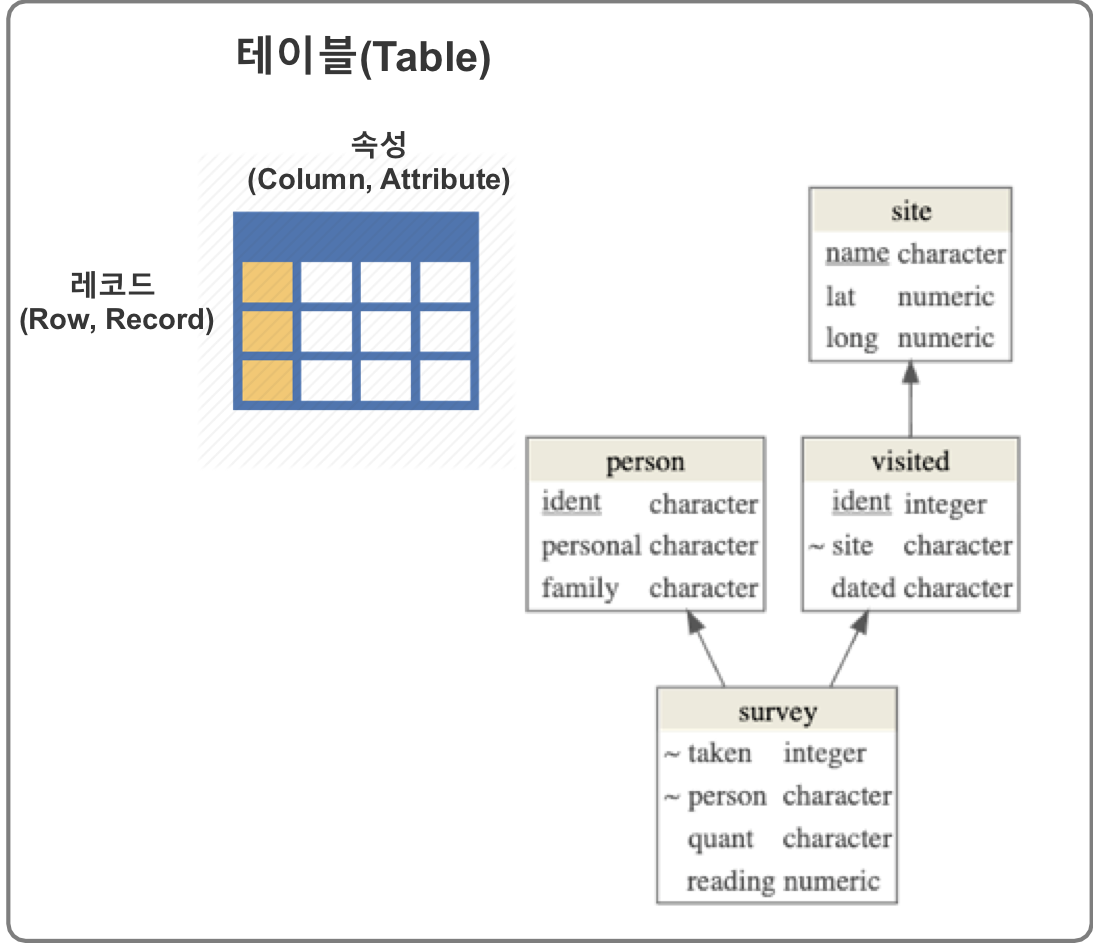
인간이 생각하는 개념 또는 정보의 세계에서는 의미있는 정보의 단위를 엔티티(entity) 를 관계형 데이터베이스는 테이블(table)로 표현한다. 각 행은 레코드라고 불리며 엔티티의 인스턴스(instance)가 되며, 각 칼럼은 속성(attribute)에 대한 정보가 담겨진다. 테이블은 유일무이한 키(unique key)로 연결되어 있고, SQL(Structured Query Language)를 이용하여 데이터베이스와 상호작용하게 된다.
Sqlite¶
관계형 데이터베이스에 데이터를 관리하게 되면 후속 데이터 분석과정에서 발생할 수 있는 다양한 문제를 미연에 방지할 수 있고, 무엇보다 대용량의 데이터를 필요할 때마다 접속해서 가져온다는 측면에서 편리하다. 관계형 데이터베이스에는 마이크로소프트 MS SQL, 오라클, PostreSQL, MySQL, Sqlite 등이 있는데 Sqlite는 로컬 컴퓨터에 파일 형태로 존재해서 사용이 단순하다는 측면에서 편리하다. SQLite에 대한 자세한 사항은 웹사이트를 참조한다.
데이터베이스와 SQL¶
데이터베이스에 데이터가 테이블 형태로 서로 유기적으로 잘 연결되어 정리되어 있는 상태에서 SQL 쿼리를 사용해서 원하는 데이터를 가져오거나 변경을 가할 수 있다. 이는 크게 두가지 단계로 나눠진다.
- 데이터베이스에 연결
- 쿼리를 데이터베이스에 전달
파이썬 판다스¶
pd.read_csv() 메쏘드를 사용하게 되면 SQL 문을 직접 실어 보내서 판다스 데이터프레임으로 변환작업하는 것이 가능하다.
이를 위해서 먼저 SQLAlchemy를 데이터베이스와 연결시키는 핵심엔진으로 사용한다.
만약, SQLAlchemy 모듈이 설치되지 않은 경우, !pip install sqlalchemy 명령어를 사용해서 설치한다.

소프트웨어 카펜트리 - survey.db¶
R과 SQL - 소프트웨어 카펜트리 수업에서 제작한 survey.db SQLite 데이터베이스를 파이썬 데이터분석 작업흐름에 추출하여 기본적인 통계분석작업을 수행해 본다.
import pandas as pd
from sqlalchemy import create_engine
# SQL 엔진 연결
sql_engine = create_engine("sqlite:///data/survey.db")
# SQL 엔진을 통해 테이블 가져오기
person = pd.read_sql("Person", sql_engine)
print(person)
SQL 쿼리 작업¶
앞서 sql_engine을 통해 데이터베이스 연결작업이 완료되면, 다음 단계로 pd.read_sql() 메쏘드 내부에 SQL 쿼리를 작성해서 원하는 결과를 데이터프레임으로 가져오는 작업을 수행한다.
query = '''
SELECT *
FROM Survey
WHERE person='lake'
OR person='roe';
'''
# SQL 엔진을 통해 테이블 가져오기
lake_roe = pd.read_sql(query, sql_engine)
print(lake_roe)
테이블 병합¶
Site 테이블과 Visited 테이블을 결합시켜 새로운 판다스 데이터프레임을 생성시킬 수 있다.
query_join = '''
SELECT Site.lat, Site.long, Visited.dated, Survey.quant, Survey.reading
FROM Site join Visited
JOIN Survey
ON Site.name=Visited.site
AND Visited.ident=Survey.taken
AND Visited.dated is not null;
'''
# SQL 엔진을 통해 테이블 가져오기
survey_df = pd.read_sql(query_join, sql_engine)
print(survey_df)
시각화¶
판다스 데이터프레임으로 만들어지면 다음 단계로 시각화도 가능하다. ! pip install seaborn 명령어를 실행하여 다양한 시각화 라이브러리 중 seaborn을 사용해서 시각화에 도전해 본다.
%matplotlib inline
import seaborn as sns
survey_df['reading'] = pd.to_numeric(survey_df['reading'])
sns.lmplot("lat", "long", data=survey_df, fit_reg=False, col='quant')
