
궁극의 주인이 될 알고리즘(Master Algorithm)
학습 목표
- 마스터 알고리즘의 등장배경과 더불어 기존 기계학습 알고리즘의 한계를 살펴본다.
- 기계학습 5가지 중요 알고리즘을 이해한다.
- 마스터 알고리즘이 갖춰야 요소를 미리 알아본다.
1. 궁극의 주인이 될 알고리즘 (Master Algorithm) 1
| Ted 강연 (The Quest for the Master Algorithm, Pedro Domingos) | 마이크로소프트 연구소 (The Master Algorithm) |
|---|---|
지금 성공적으로 평가받는 기업들은 영화추천, 제품추천, 구인/구직 추천, 음악 추천등 한가지 혹은 몇가지 추천 혹은 예측 작업을 잘하는 알고리즘이다. 앞으로 사람들은 더욱 많은 알고리즘으로 둘러 싸일 것이고, 종류도 많고 수도 제법되는 추천 알고리즘은 서로 협업하고, 경쟁하며 모형/알고리즘이 지배하는 세상이 도래할 것이다.
기계학습 알고리즘을 아마존 도서추천, 넥플릭스 영화추천, 스마트폰을 통해서 생성되는 다양하고 엄청난 양의 데이터를 통해 사람의 패턴을 학습하여 예측의 정도를 높여나가고 있다. 자율주행을 가능케하는 자동차를 프로그래밍하는 방법은 모른다. 하지만, 사람들이 주행하면서 뿜어내는 엄청난 데이터를 수집하여 이를 학습시켜 자율주행이 가능한 자동차가 탄생되었고, 그 신뢰성을 높여가고 있다. 요즘 태어나는 아이들은 결혼정보회사가 매우 중요한 역할을 수행하고 있으며, 결혼에 이르는 성공율을 높이기 위해 결혼 당사자의 프로필뿐만 아니라 결혼성사과정에서 나오는 다양하고 엄청난 데이터를 학습시키고 있다.
컴퓨터가 이제는 과학자의 역할도 대신하고 있다. 컴퓨터가 가설을 만들고 실험을 통해 데이터를 모아 가설을 검정한다. 그리고 나서 가설검정결과를 바탕으로 또다른 가설을 생성하고 실험을 하고 데이터를 모아 다시 가설을 검정하는 과정을 쉬지 않고 무한히 반복한다.
중요한 것은 컴퓨터가 데이터를 통해 학습한다는 점이다. 이를 통해 그동안 수천년동안 사람들이 만들어낸 것보다 훨씬 더 많은 지식을 단시일내에 생성하고 나서 기하급수적으로 지식을 증가시킬 것이다. 왜냐하면 전통적인 기계학습 알고리즘은 특정 문제에 대해 특정 알고리즘을 생성시킨다. 예를 들어 바둑, 체스, 고스톱같은 보드게임 문제를 해결할 때 특정한 게임 알고리즘을 생성시켜 문제를 해결했다.
하지만, 최근의 기계학습 알고리즘은 범용 알고리즘으로 입력으로 주어진 데이터에 따라 동작하는 방식이 달라진다. 예를 들어 바둑이나 체스 같은 데이터를 넣어주면 게임을 잘하는 방법을 학습하게 되고, 의료진단 데이터를 넣어주면 질병예측 알고리즘으로 역할을 달리한다.
궁극의 알고리즘은 스스로 알고리즘을 만들어 낼 수 있는 알고리즘이다.
- 정보세대(Information Generation): 누군간 프로그램을 작성, 단계별로 사람이 프로그램을 작성하게 되어 느리고, 비싸고 비용이 많이 소요됨.
- 기계학습세대(Machine Learning Generation): 기계가 데이터에서 알고리즘을 추출해서 프로그램이 작성됨, 즉 Automation of Automation.
1.1. 기계학습 알고리즘과 프로그래밍 비교
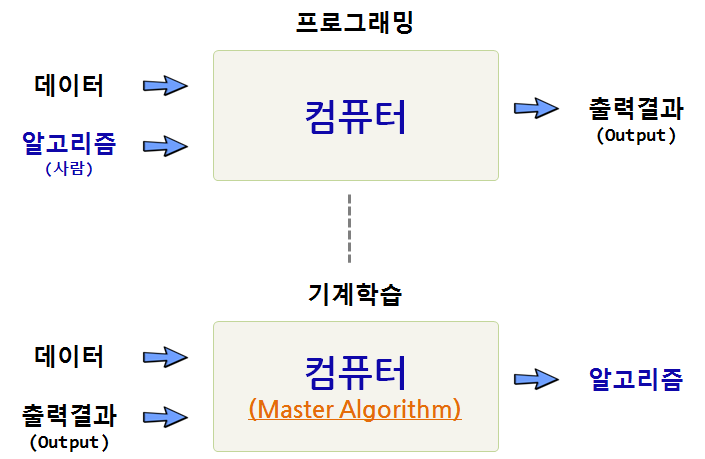
동일한 문제를 놓고 기계학습 알고리즘을 적용하는 방법과 기존 프로그래밍 기법을 활용한 방법은 다음과 같은 차이가 난다. 기존 프로그래밍 방법은 데이터와 알고리즘을 넣어 컴퓨터가 계산을 수행하고 나서 출력결과를 만들어 내는 과정으로 원하는 결과에 도달할 때까지 과정을 무한반복한다.
이에 반해 기계학습 알고리즘 접근법은 데이터와 출력결과를 넣게 되면 컴퓨터가 알고리즘을 만들어낸다. 알고리즘의 성능은 데이터의 양과 질에 달려있고, 얼마나 많은 학습을 반복하냐에 달려있다.
1.2. 프로그램을 개발하는 컴퓨터 2
자율주행 자동차를 프로그래밍하는 방법은 아직 아무도 모른다. 다만, 기계학습 알고리즘을 잘 사용해서 컴퓨터가 만들어내는 알고리즘을 자동차에 장착시키면 신뢰성 높은 자율주행 자동차를 만들 수 있다는 것은 여러 검증 과정을 거쳐 확인이 되었다.
이를 달리 해석하면 엄격하고 효과적인 프로그램을 작성하는 것보다 불투명하고 예측가능하지 않는 네트워크를 활용하는 이유가 있가. 가장 큰 이유는 세세한 부분까지 전체적으로 제어되는 알고리즘은 확장성이 떨어지는데 있다. 이를 극복하는 알고리즘은 다음과 같은 특징을 갖는다.
- 참/거짓 부울 로직보다 확률을 활용
- 알고리즘의 세세한 부분에까지 제어하고 명세하는 것이 갖는 손실을 인정하고 받아들인다.
- 알고리즘은 되먹임 과정(feedback process)을 통해 변경되고 더 정교화되는 과정을 반복한다.

2. 기계학습 다섯 종족
기계학습에 많이 활용되는 알고리즘은 크게 5개로 분류되는데 각 알고리즘은 결국 해결하고자 하는 문제를 정의하는 표현 부분, 알고지즘으로 평가하는 부분, 그리고 최적화하는 부분으로 나눠진다.
| 종족 | 문제 | 해법 | 기원 |
|---|---|---|---|
| 기호주의자(Symbolists) | 지식구성(Knowledge Composition) | 역연역법(Inverse deduction) | 논리, 철학 |
| 연결주의자(Connectionists) | 신뢰 할당(Credit Assignment) | 역전파(Backpropagation) | 신경과학(Nuuroscience) |
| 진화론자(Evolutionaries) | 구조발견(Structure Discovery) | 유전자 프로그래밍(Genetic Programming) | 진화 생명과학(Evolutionary Biology) |
| 베이지안(Bayesians) | 불확실성(Uncertainty) | 확률추론(Probabilistic Inference) | 통계학 |
| 유추론자(Analogizers) | 유사성(Similarity) | 커널 기계(Kernel Machine) | 심리학 |
2.1. 기호주의자
- 주요 인물
- Tom Mitchell
- Steve Muggleton
- Ross Quinlan
2.1.1. 역추론이란?
- 간단한 계산 사례
덧셈
2
+ 5
----
= ?뺄셈
2
+ ?
----
= 7
- 논리학
연역법(Deduction)
소크라테스는 사람이다.
+ 사람은 모두 죽는다.
--------------------------
= ?귀납법(Induction)
소크라테스는 사람이다.
+ ?
--------------------------
= 소크라테스는 죽는다.
2.1.2. 성공사례
- 로봇 과학자 이브(eve) 3: 말라리아 치료제 개발, 맨체스터 대학 Ross King 박사.

2.2. 연결주의자
- 주요 인물
- Yann LeCun
- Geoff Hinton
- Yoshua Bengio
2.2.1. 신경망이란?
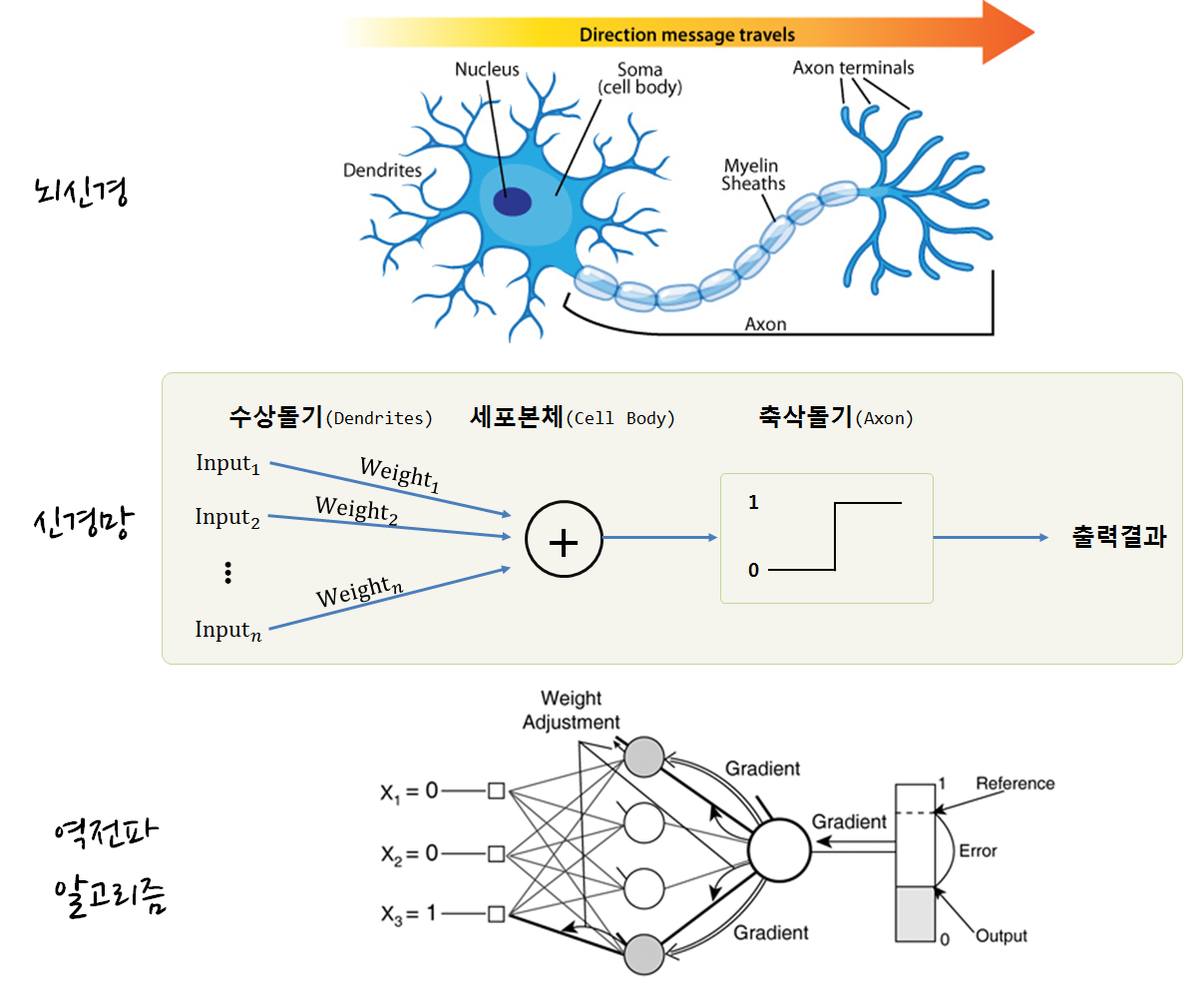
시간적 기여도 할당문제(temporal credit assignment problem)는 일련의 행동들이 모두 끝난 후에야 궤환신호를 얻을 수 있는 상황에서 그때까지 수행된 일련의 행동들 중 어떤 행동에 기여도(credit)를 주고 또 어떤 행동에 벌점(blame) 을 줄 것인지 결정하는 것을 말한다.
2.2.2. 성공사례
2.3. 진화론자
- 주요 인물
- John Koza
- John Holland
- Hod Lipson
2.3.1. 유전 알고리즘(Genetic Algorithms)
유전 알고리즘(Genetic Algorithm)은 자연세계의 진화과정에 기초한 계산 모델로서 존 홀랜드(John Holland)에 의해서 1975년에 개발된 전역 최적화 기법으로, 최적화 문제를 해결하는 기법의 하나이다. 생물의 진화를 모방한 진화 연산의 대표적인 기법으로, 실제 진화의 과정에서 많은 부분을 차용하였으며 변이(돌연변이, mutation), 교배 연산(crossover) 등을 활용한다.
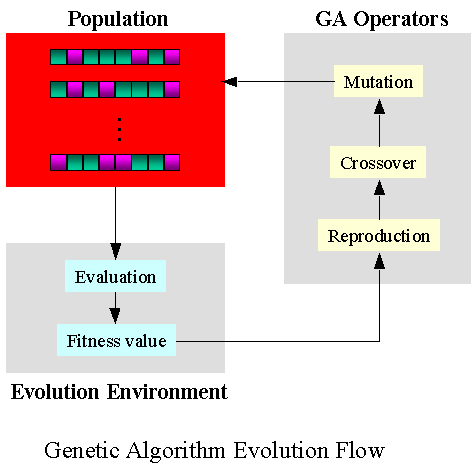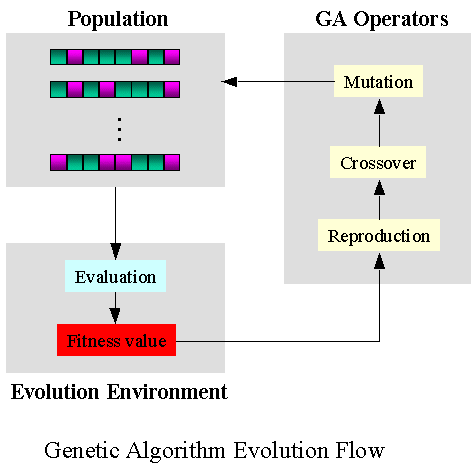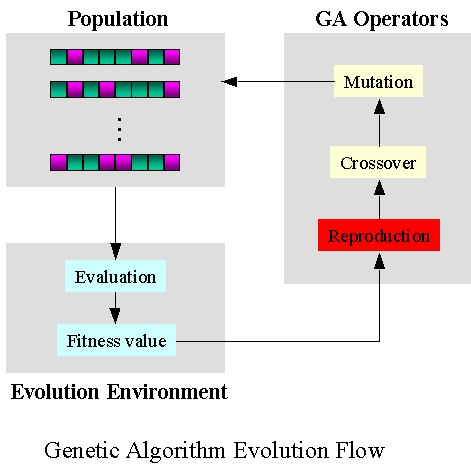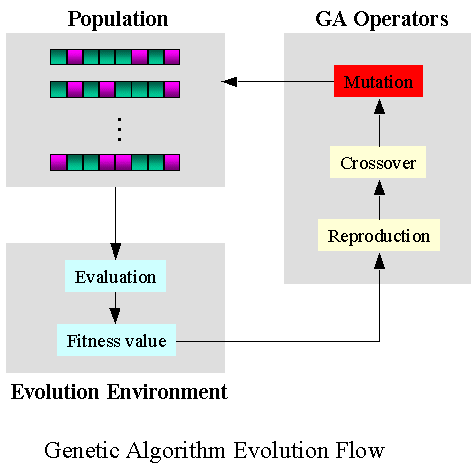
2.3.2. 유전 프로그래밍(Genetic Programming)
유전 프로그래밍(Genetic programming)은 사용자가 원하는 작업을 수행하는 컴퓨터 프로그램을 찾아내는 방법이다. 생물학적 진화를 통해 착안한 알고리즘으로, 유전 알고리즘의 확장된 형태이고 기본적인 특성은 기존 유전 알고리즘 방식과 흡사하다
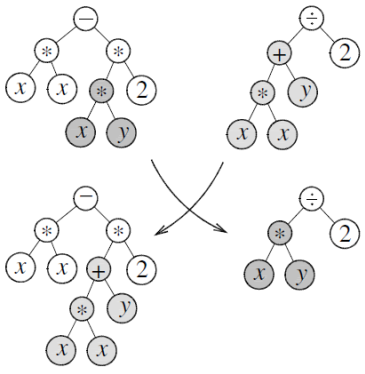
2.3.3. 성공사례 4
레고블록같은 부품을 조합해서 로봇이 되고, 다시 3D 프린터로 새로운 부품을 만들어 새로운 로봇이되고 이 과정을 반복해서 궁극의 로봇이 되는 실험이 진행되고 있다.
2.4. 베이지안
- 주요 인물
- David Heckerman
- Judea Pearl
- Micheal Jordan
2.4.1. 확률 추론 – 베이즈 정리
\(\Pr(H|e)=\frac{\Pr(e|H)\Pr(H)}{\Pr(e)}\propto \mathcal L(H|e)\Pr(H)\)
- 우도(Likelihood, \(\Pr(e|H)\)) : 가정이 참이라고 가정할 때 증거 데이터의 가능성은 얼마나 되나?
- 사전 확률(Prior, \(\Pr(H)\)) : 증거 데이터를 관측하기 전에 가설의 가능성은 얼마나 되나?
- 사후 확률(Posterior, \(\Pr(H|e)\)) : 관측 데이터가 주어졌을 때 가설의 가능성은 얼마나 되나?
- 주변확률(Marginal, \(\Pr(e)=\sum \Pr(e|H_{i})\Pr(H_{i})\)) : 가능한 모든 가설아래 새로운 증거 데이터의 가능성은 얼마나 되나?
2.4.2. 성공사례 – 전자우편 스팸
전자우편이 왔을 때 특정 단어(\(W\))가 스팸일 확률.
\(\Pr(S|W)=\frac{\Pr(W|S) \cdot \Pr(S)}{\Pr(W|S) \cdot \Pr(S) + \Pr(W|H) \cdot \Pr(H)}\)
- \(\Pr(S|W)\) : 특정 단어가 전자우편에 포함되었을 때 전자우편이 스팸일 확률.
- \(\Pr(S)\) : 전자우편이 스팸일 사전 확률.
- \(\Pr(W|S)\) : 특정 단어가 스팸 전자우편에 나올 확률.
- \(\Pr(H)\) : 전자우편이 스팸이 아닐 사전 확률.
- \(\Pr(W|H)\) : 특정 단어가 정상 전자우편에 나올 확률.

2.5. 유사론자
- 주요 인물
- Peter Hart
- Vladimir Vapnik
- Douglas Hofstadter
2.5.1. 최근접 이웃 (Nearest Neighbor) 알고리즘
\(k-\)최근접 이웃 알고리즘(또는 줄여서 k-NN)은 분류나 회귀에 사용되는 비모수 방식으로, 모두 입력이 특징 공간 내 k개의 가장 가까운 훈련 데이터로 구성되고, 출력은 k-NN이 분류로 사용되었는지 또는 회귀로 사용되었는지에 따라 다르다. 5
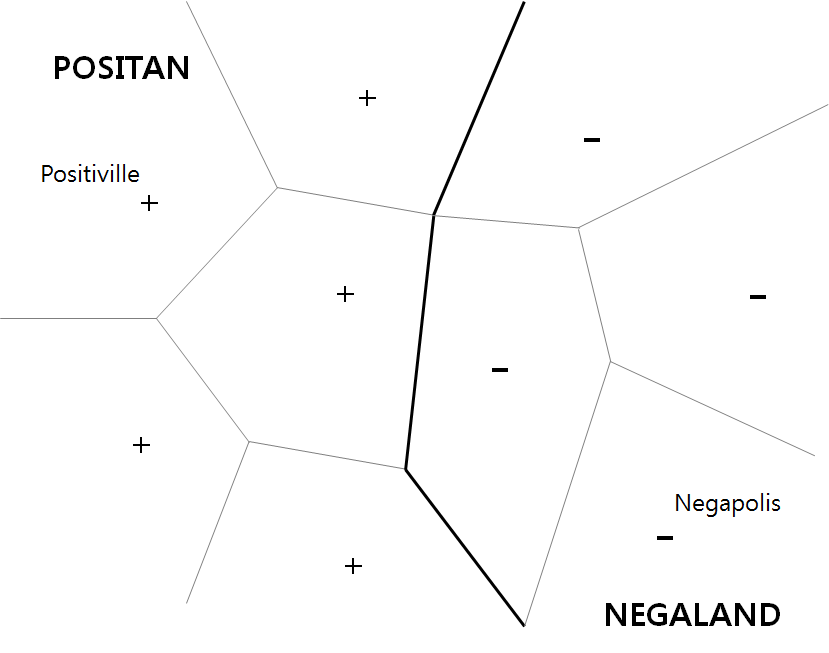
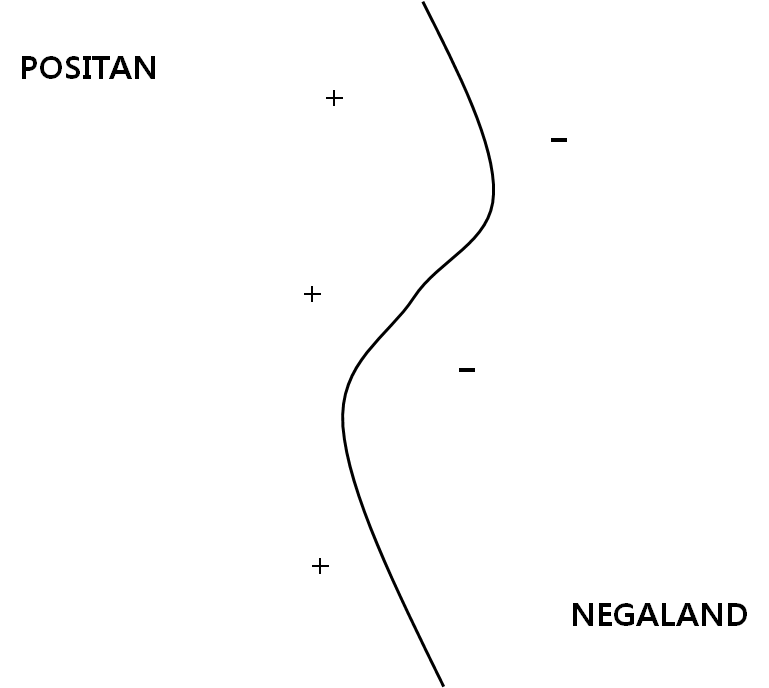
2.5.2. 커널 기계(Kernel Machine) - SVM
3. 활용분야
- 가정용 로봇
- 암 치료
- 360 \(^{\circ}\) 전방위 추천
- 월드 와이드 웹을 두뇌로 확장