
환자 데이터(Patient Data) 분석
관절염에 새로운 치료법이 처방된 환자의 염증에 대한 연구를 진행하고 있고, 첫 12 데이터셋(Data Set)을 분석할 필요가 있다. 데이터셋은 CSV 형식(comma-separated values, 구분자가 콤마 값을 가진 파일 형식)으로 저장되어 있다. 각 행은 환자 한명의 정보로 구성되어 있고, 열은 일련의 날짜 정보를 나타낸다. 첫번째 파일의 첫 몇 행의 정보는 다음과 같다.
0,0,1,3,1,2,4,7,8,3,3,3,10,5,7,4,7,7,12,18,6,13,11,11,7,7,4,6,8,8,4,4,5,7,3,4,2,3,0,0
0,1,2,1,2,1,3,2,2,6,10,11,5,9,4,4,7,16,8,6,18,4,12,5,12,7,11,5,11,3,3,5,4,4,5,5,1,1,0,1
0,1,1,3,3,2,6,2,5,9,5,7,4,5,4,15,5,11,9,10,19,14,12,17,7,12,11,7,4,2,10,5,4,2,2,3,2,2,1,1
0,0,2,0,4,2,2,1,6,7,10,7,9,13,8,8,15,10,10,7,17,4,4,7,6,15,6,4,9,11,3,5,6,3,3,4,2,3,2,1
0,1,1,3,3,1,3,5,2,4,4,7,6,5,3,10,8,10,6,17,9,14,9,7,13,9,12,6,7,7,9,6,3,2,2,4,2,0,1,1
다음을 수행해야 된다.
- CSV 형식 데이터 파일을 주기억장치에 로딩(loading)한다.
- 모든 환자에 대해서 각 날짜별로 평균 염증을 계산한다.
- 결과값을 플롯(plot)한다.
상기 모든 것을 수행하기 위해서, 프로그래밍에 관해 약간 학습할 필요가 있다.
목표
- 라이브러리가 무엇인지와, 무슨 라이브러리가 사용되는지 설명한다.
- 파이썬 라이브러리를 로드(load)하고 라이브러리가 담고있는 것을 사용한다.
- 파일에서 테이블 형식 데이터를 프로그램으로 읽어온다.
- 값을 변수에 할당한다.
- 데이터에서 각각의 값과 일부를 선택한다.
- 배열 데이터에 연산을 수행한다.
- 단순 그래프를 화면에 출력한다.
데이터 로딩(Loading)
데이터 로딩(Loading)
단어는 유용하지만, 좀더 유용한 것은 단어로 작성된 문장과 스토리다. 마찬가지로 많은 강력한 툴이 파이썬 같은 언어에 내장되어 있지만, 좀더 생동감 있는 라이브러리(libraries)로 강력한 툴을 만들 수 있다.
염증 데이터를 로드하기 위해서, NumPy라는 라이브러리를 가져오기(import)를 할 필요가 있다. 일반적으로 숫자로 멋진 것을 하려고 하거나, 특히, 행렬을 가지고 있다면 NumPy 라이브러리를 사용해야 한다.
import numpy라이브러리를 가져오는 것은 물품 보관함에서 연구실 장비를 꺼내서 벤치에 설치하는 것과 같다. 완료되면, 라이브러리에게 데이터를 읽어오라고 지시할 수 있다.
numpy.loadtxt(fname='inflammation-01.csv', delimiter=',')array([[ 0., 0., 1., ..., 3., 0., 0.],
[ 0., 1., 2., ..., 1., 0., 1.],
[ 0., 1., 1., ..., 2., 1., 1.],
...,
[ 0., 1., 1., ..., 1., 1., 1.],
[ 0., 0., 0., ..., 0., 2., 0.],
[ 0., 0., 1., ..., 1., 1., 0.]])numpy.loadtxt(...) 표현식은 함수 호출(function call)로 파이썬에게 numpy라이브러리에 속해 있는 loadtxt 함수를 실행하게 한다. 점 표기법(dotted notation)은 파이썬에서 도처에서 사용되는데 thing.component 같은 어떤 것의 부분을 나타낸다.
numpy.loadtxt는 매개변수(parameters)가 두개 있다. 읽어 오려고 하는 파일이름과 라인에서 값을 구분하는 구분자(delimiter)다. 둘다 문자의 열, 짧게 줄여서 문자열(strings)이 되어야 한다. 그래서 인용부호 안에 넣는다.
타이핑을 마치고 쉬프트+엔터(Shift+Enter)를 누를 때, 노트북은 명령어를 실행한다. 함수 출력에 대해서 어떤 것도 지시한 것이 없기 때문에, 노트북은 출력 결과를 화면에 출력한다. 이 경우 출력결과는 방금 전에 로드한 데이터 자체다. 디폴트로, 단지 몇개의 행과 열만 보여진다. (커다란 배열을 화면에 출력할 때는 요소를 생략하기 위해서 ...를 사용하여 표기한다.) 공간을 절약하기 위해서 파이썬은
소수점 다음에 흥미로운 것이 없을 때는 숫자를 1.0 대신에 1.을 사용한다.
numpy.loadtxt 함수 호출은 파일을 읽어들이지만, 주기억장치에 데이터를 저장하지는 않는다. 저장하기 위해서는 변수(variable)를 배열에
할당(assign)할 필요가 있다.
변수는 x, current_temperature, subject_id 같은 값에 대한 이름이다.
파이썬 변수는 문자로 시작해야만 한다. 값을 변수에 =을 사용하여 간단하게 할당할 수 있다.
일례로, 한걸음 물러나서 테이블 데이터를 고려하는 대신에 가장 단순한 데이터 "집합(컬렉션,collection)", 단일 값을 고려하자.
다음 라인은 변수에 값을 할당한다.
weight_kg = 55변수가 값을 가지게 되면 출력할 수도 있다.
print weight_kg55
변수로 산수를 할 수 있다.
print 'weight in pounds:', 2.2 * weight_kgweight in pounds: 121.0
변수에 새로운 값을 할당해서 변수의 값도 변경할 수 있다.
weight_kg = 57.5
print 'weight in kilograms is now:', weight_kgweight in kilograms is now: 57.5
상기 예제가 보여주듯이, 한번에 여러개를 콤마로 구분해서 출력할 수 있다.
만약 변수를 이름이 써진 포스트잇 같은 스티커 노트라고 가정한다면, 할당은 특정한 값에 스티커 노트를 붙이는 것과 같다.

이것이 의미하는 바는 한 개체에 값을 할당하는 것이 다른 변수의 값을 변경시키지는 않는다. 예를 들어, 변수에 개체의 무게를 파운드로 저장하자.
weight_lb = 2.2 * weight_kg
print 'weight in kilograms:', weight_kg, 'and in pounds:', weight_lbweight in kilograms: 57.5 and in pounds: 126.5

그리고 나서 weight_kg를 변경하자.
weight_kg = 100.0
print 'weight in kilograms is now:', weight_kg, 'and weight in pounds is still:', weight_lbweight in kilograms is now: 100.0 and weight in pounds is still: 126.5

weight_lb 변수는 값이 어디에서 왔는지 기억하지 않기 때문에, 자동적으로 weight_kg이 변경될 때 갱신되지 않는다. 엑셀같은 스프레드쉬트가 동작하는 방식과 이런 점이 다르다.
변수에 어떻게 값을 할당하듯이 동일한 구문을 사용하여 변수에 배열 값을 할당할 수도 있다.
read.csv을 다시 실행하고 결과를 저장하자. numpy.loadtxt을 다시 시작하고 결과를 저장하자.
data = numpy.loadtxt(fname='inflammation-01.csv', delimiter=',')상기 문장은 결과를 출력하지 않는데 할당은 어떤 것도 화면에 출력하지 않기 때문이다. 데이터가 주기억장치에 로딩되었는지 확인하고자 한다면, 변수의 값을 출력할 수 있다.
print data[[ 0. 0. 1. ..., 3. 0. 0.]
[ 0. 1. 2. ..., 1. 0. 1.]
[ 0. 1. 1. ..., 2. 1. 1.]
...,
[ 0. 1. 1. ..., 1. 1. 1.]
[ 0. 0. 0. ..., 0. 2. 0.]
[ 0. 0. 1. ..., 1. 1. 0.]]
도전 과제
-
도표를 그려서 다음 프로그램의 각 문장이 실행된 후에 무슨 변수가 무슨 값을 참조하는지 보이세요.
mass = 47.5 age = 122 mass = mass * 2.0 age = age - 20 -
다음 프로그램이 출력하는 것은 무엇인가요?
first, second = 'Grace', 'Hopper' third, fourth = second, first print third, fourth
데이터 능숙하게 다루기
데이터가 주기억장치에 올라갔기 때문에, 데이터를 가지고 무언가를 시작할 수 있다. 먼저 data가 무슨 형식(type)인지 확인해보자.
print type(data)<type 'numpy.ndarray'>
출력결과를 통해서 NumPy 라이브러리로 생성된 N-차원의 배열임을 확인할 수 있다. 데이터가 어떤 형태(shape)인지도 알 수 있다.
print data.shape(60, 40)
data가 60 행과 40 열로 구성된 것을 알 수 있다.
data.shape은 data의 멤버(member)다.
즉, 더 커다란 값의 일부로 저장되어 있다.
라이브러리의 함수에 사용한 동일한 점표기법을 값의 멤버에 대해서 사용하는데 이유는 동일한 "부분과 전체" 관계를 가지기 때문이다.
행렬에서 값 하나를 얻으려고 한다면, 수학에서 하는 것과 같은 방식으로 꺾쇄 괄호내부에 인덱스(index)를 넣을 수 있다.
print 'first value in data:', data[0, 0]first value in data: 0.0
print 'middle value in data:', data[30, 20]middle value in data: 13.0
data[30, 20] 표현식은 놀랍지 않지만, data[0, 0] 표현식은 여러분을 놀라게 할지 모른다.
Fortran이나 Matlab 같은 프로그래밍 언어는 1에서 샘을 시작하는데 이유는 수천년동안 인류가 해왔던 동일한 방식이다.
C++, Java, Perl, Python을 포함하는 C 언어 패밀리는 0에서 샘을 시작하는데 이유는 컴퓨터에게 더 간단하기 때문이다.
결과적으로, 파이썬에서 M×N 배열을 가지고 있다면, 인덱스는 첫번째 축으로 0에서 M-1, 두번째 축으로 0에서 N-1까지 간다.
익숙해지는데는 조금 시간이 걸리지만, 규칙을 기억하는 방식은 인덱스는 출발점에서 원하는 항목까지 도달하는데 얼마나 많은 단계를 거치는지 세는 것이다.
구석에서(In the Corner)
또한 여러분을 놀라게 하는 것은 파이썬이 배열을 출력할 때, 왼쪽 하단보다 왼쪽 상단 구석에
[0, 0]인텍스를 가진 요소가 위치한다. 수학자가 행렬을 그리는 것과 일치하지만, 데카르트 좌표계(Cartesian coordinates)와는 다르다. 인덱스가 같은 이유로 (열, 행) 대신에 (행, 열)이여서, 데이터를 가지고 그래프를 그릴 때 혼동될 수 있다.
[30, 20] 같이 인텍스를 넣어서 배열의 요소값을 하나 선택할 수 있지만, 전체도 선택할 수 있다. 예를 들어, 다음과 같이 첫 환자 네명(행)에 대한 첫 10일치(열) 값을 선택할 수 있다.
print data[0:4, 0:10][[ 0. 0. 1. 3. 1. 2. 4. 7. 8. 3.]
[ 0. 1. 2. 1. 2. 1. 3. 2. 2. 6.]
[ 0. 1. 1. 3. 3. 2. 6. 2. 5. 9.]
[ 0. 0. 2. 0. 4. 2. 2. 1. 6. 7.]]
슬라이스(slice) 0:4가 뜻하는 것은 "0번 인덱스에서 시작해서 4번 인덱스까지 가는데 인덱스 4는 포함하지 않는다."
인덱스 몇번까지는 가지만 포함하지 않는다는 것에 익숙해지는데 시간이 걸리지만, 상한과 하한의 차이가 슬라이스에 있는 값의 갯수라는 것이 규칙이다.
슬라이스가 반드시 0번에서 시작할 필요는 없다.
print data[5:10, 0:10][[ 0. 0. 1. 2. 2. 4. 2. 1. 6. 4.]
[ 0. 0. 2. 2. 4. 2. 2. 5. 5. 8.]
[ 0. 0. 1. 2. 3. 1. 2. 3. 5. 3.]
[ 0. 0. 0. 3. 1. 5. 6. 5. 5. 8.]
[ 0. 1. 1. 2. 1. 3. 5. 3. 5. 8.]]
슬라이스의 상한과 하한을 반듯이 포함할 필요는 없다. 하한을 포함하지 않는다면, 파이썬은 디폴트 값으로 0을 사용한다. 만약 상한을 포함하지 않는다면, 슬라이스는 그 해당 축의 끝까지 간다. 만약 상한이나 하한을 포함하지 않는다면 (즉, ':'만 사용한다면), 슬라이스는 모든 것을 포함한다.
small = data[:3, 36:]
print 'small is:'
print smallsmall is:
[[ 2. 3. 0. 0.]
[ 1. 1. 0. 1.]
[ 2. 2. 1. 1.]]
배열은 자체로 일반적인 수학 연산을 배열값에 수행한다. 데이터를 가지고 할수 있는 가장 단순한 연산은 사칙연산(덧셈, 뺄셈, 곱셈, 나눗셈)이다. 배열에 사칙연산을 수행할 때, 배열의 각각의 요소에 대해서 연산을 수행한다.
doubledata = data * 2.0그래서 상기 연산은 data에 해당 요소값 각각에 2를 곱한 값을 가지는 doubledata 배열을 생성한다.
print 'original:'
print data[:3, 36:]
print 'doubledata:'
print doubledata[:3, 36:]original:
[[ 2. 3. 0. 0.]
[ 1. 1. 0. 1.]
[ 2. 2. 1. 1.]]
doubledata:
[[ 4. 6. 0. 0.]
[ 2. 2. 0. 2.]
[ 4. 4. 2. 2.]]
배열을 가지고 상기에서 처럼 단일 값 각각에 연산을 수행하는 대신에 만약 동일한 크기와 형태를 가진 다른 배열이 있다면, 두 배열의 해당 요소에 연산을 수행할 수 있다.
tripledata = doubledata + data따라서 상기 표현식은 doubledata[0,0]을 data[0,0]에 더해서 tripledata[0,0]이 되고, 배열의 다른 모든 요소에도 동일하게 계산된 결과 배열이 될 것이다.
print 'tripledata:'
print tripledata[:3, 36:]tripledata:
[[ 6. 9. 0. 0.]
[ 3. 3. 0. 3.]
[ 6. 6. 3. 3.]]
종종 데이터의 값을 더하고, 빼고, 곱하고, 나누는 것 이상 원한다. 배열을 통해서 배열의 값에 좀더 복잡한 연산을 수행할 수 있다. 예를 들어, 모든 환자에 대한 모든 날짜의 평균 염증값을 얻고자 한다면, 배열에 평균값을 단순히 요청하면된다.
print data.mean()6.14875
mean은 배열의 메쏘드(method)다.
즉, 멤버 shape가 하는 동일한 방식으로 배열에 속한 함수다.
만약 변수가 명사라면, 메쏘드는 동사라고 볼 수 있고 문제의 것이 어떻게 수행하는지를 알고 있다.
왜 data.shape이 호출될 필요가 없고(단지 사물이다.), data.mean()은 호출(액션이다.)되는지 설명하는 이유다.
또한, data.mean()에 대해서 빈 괄호가 필요한 이유이기도 하다. 심지어 어떤 매개 변수도 전달할 필요가 없을 때,
괄호은 파이썬에게 가서 무언가 어떻게 하라고 하는 것이다.
NumPy 배열에는 많은 유용한 메쏘드가 있다.
print 'maximum inflammation:', data.max()
print 'minimum inflammation:', data.min()
print 'standard deviation:', data.std()maximum inflammation: 20.0
minimum inflammation: 0.0
standard deviation: 4.61383319712
하지만, 데이터를 분석할 때, 종종 환자마다 최대값 혹은 일자별 평균값 같은 부분 통계량을 보고자 한다. 이를 수행하는 방법은 데이터 선택해서 임시 배열로 생성하고 계산을 수행하는 것이다.
patient_0 = data[0, :] # 0 on the first axis, everything on the second
print 'maximum inflammation for patient 0:', patient_0.max()maximum inflammation for patient 0: 18.0
실질적으로 변수의 행을 저장할 필요하는 없다. 대신에 선택한 것과 메쏘드 호출을 조합할 수 있다.
print 'maximum inflammation for patient 2:', data[2, :].max()maximum inflammation for patient 2: 19.0
만약 모든 환자에 대한 최대 염증값 혹은 각 날짜별로 평균값이 필요하다면 어떨까? 다음 도표처럼, 축을 따라서 연산을 수행하고자 한다.
이러한 기능을 지원하기 위해서, 대부분의 배열 메쏘드는 작업하고자 하는 축을 지정할 수 있다. 만약 0번 축을 따라서 평균을 구하고자 한다면, 다음을 얻게 된다.
print data.mean(axis=0)[ 0. 0.45 1.11666667 1.75 2.43333333 3.15
3.8 3.88333333 5.23333333 5.51666667 5.95 5.9
8.35 7.73333333 8.36666667 9.5 9.58333333
10.63333333 11.56666667 12.35 13.25 11.96666667
11.03333333 10.16666667 10. 8.66666667 9.15 7.25
7.33333333 6.58333333 6.06666667 5.95 5.11666667 3.6
3.3 3.56666667 2.48333333 1.5 1.13333333
0.56666667]
빠른 점검 목적으로 배열에게 어떤 모양인지 확인할 수 있다.
print data.mean(axis=0).shape(40,)
(40,) 결과값은 N×1 벡터임을 보여줘서 모든 환자에 대해서 날짜별 평균 염증값임을 알 수 있다.
만약 1번 축으로 평균값을 구한다면, 다음을 얻게 된다.
print data.mean(axis=1)[ 5.45 5.425 6.1 5.9 5.55 6.225 5.975 6.65 6.625 6.525
6.775 5.8 6.225 5.75 5.225 6.3 6.55 5.7 5.85 6.55
5.775 5.825 6.175 6.1 5.8 6.425 6.05 6.025 6.175 6.55
6.175 6.35 6.725 6.125 7.075 5.725 5.925 6.15 6.075 5.75
5.975 5.725 6.3 5.9 6.75 5.925 7.225 6.15 5.95 6.275 5.7
6.1 6.825 5.975 6.725 5.7 6.25 6.4 7.05 5.9 ]
상기 값은 모든 날짜에 대해서 환자별로 평균 염증값을 보여준다.
도전 과제
배열의 일부를 슬라이스(slice)라고 부른다. 문자열에 대해서도 또한 슬라이스를 취할 수 있다.
element = 'oxygen'
print 'first three characters:', element[0:3]
print 'last three characters:', element[3:6]first three characters: oxy
last three characters: gen
-
element[:4]의 값은 무엇인가?element[4:]의 값은 무엇인가? 혹은element[:]의 값은 무엇인가? -
element[-1]의 값은 무엇인가?element[-2]의 값은 무엇인가? 상기 해답이 주어졌을 때,element[1:-1]의 값이 무엇인지 설명하시오. -
element[3:3]의 표현식은 빈 문자열(empty string)을 출력한다. 즉, 어떠한 문자도 포함하지 않은 문자열이다. 만약data가 환자 데이터의 배열이라면,data[3:3, 4:4]은 무슨 값을 출력할까?data[3:3, :]은 무슨 값을 출력할까?
플로팅(Plotting)
수학자 Richard Hamming은 "컴퓨팅의 목적은 숫자가 아니라 직관(insight)다." 그래서 직관을 키우는 가장 좋은 방법은 종종 데이터를 시각화하는 것이다. 시각화에 대한 온전한 강의를 펼칠만 하지만,여기서는 파이썬 matplotlib의 기능 몇가지만 살펴본다.
"공식적인" 플로팅 라이브러리는 없지만, matplotlib가 사실상의 표준이다.
먼저, IPython Notebook에게 별도의 윈도우에 떨어져서 보이기 보다는 플롯이 인라인(inline)으로 즉시 화면에 출력되도록 설정한다.
%matplotlib inline라인의 시작에 % 기호는 파이썬 문장(statement)보다는 notebook에 대한 명령어라는 신호를 준다. 다음으로,
matplotlib에서 pyplot 모듈을 가져와서 함수 두개를 사용해서 자료에 대한 히트맵(heat map)을 생성하여 화면에 출력한다.
from matplotlib import pyplot
pyplot.imshow(data)
pyplot.show()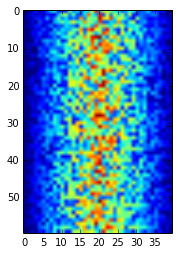
히트맵의 파란색 지역은 값이 낮은 반면에 붉은 지역은 높은 값을 나타낸다. 염증값은 40일에 걸쳐 오르고 내린다. 시간에 따른 평균 염증값을 살펴보자.
ave_inflammation = data.mean(axis=0)
pyplot.plot(ave_inflammation)
pyplot.show()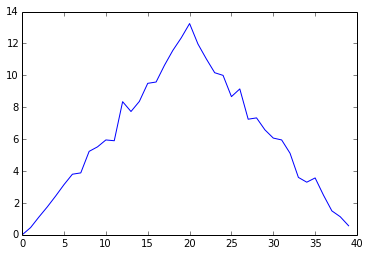
여기서, ave_inflammation 변수에 모든 환자에 대해서 날짜별로 평균 염증값을 저장하고,
pyplot으로 평균 염증값의 선 그래프를 생성하여 화면에 출력한다.
결과는 대략 선형적으로 올라가고 내려가지만 의심스럽다.
다른 연구 결과에 기초하여 좀더 빠른 급격한 상승과 좀더 완만한 하강이 예측됐다.
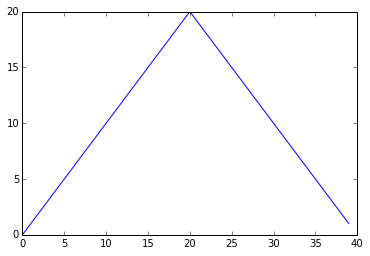
또 다른 두개의 통계량 (일자별로 최대 그리고 최소 염증값)을 살펴보자.
print 'maximum inflammation per day'
pyplot.plot(data.max(axis=0))
pyplot.show()
print 'minimum inflammation per day'
pyplot.plot(data.min(axis=0))
pyplot.show()maximum inflammation per day
minimum inflammation per day
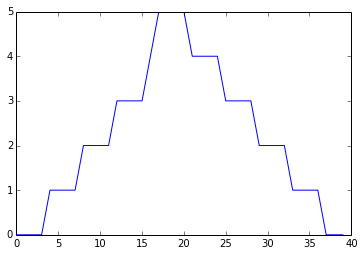
최대값은 완벽하게 매끄럽게 상승하고 하강하지만, 최소값은 계단 함수(Step function) 모양으로 보인다. 어느쪽의 결과도 그럴듯하지 못해서 계산에서 실수가 있거나 데이터에 뭔가 잘못되었다.
도전 과제
-
왜 모든 플롯이 그래프 상단이 짤리나요? 왜 날짜별 최소 염증값의 플롯에 수직라인이 완벽하게 수직이 아니죠?
-
모든 환자에 대해서 각 일자별로 염증 데이터의 표준편차를 보이는 그래프를 생성하세요.
요약하기
타이핑하는 양을 줄이기 위해서 라이브러리를 가져오기 할 때 에일리어스(alias, 별명)를 사용하는 것은 매우 일반적이다.
numpy와 pyplot에 대해서 에일리어스를 사용해서 차례로 플롯 3개를 작성했다.
import numpy as np
from matplotlib import pyplot as plt
data = np.loadtxt(fname='inflammation-01.csv', delimiter=',')
plt.figure(figsize=(10.0, 3.0))
plt.subplot(1, 3, 1)
plt.ylabel('average')
plt.plot(data.mean(0))
plt.subplot(1, 3, 2)
plt.ylabel('max')
plt.plot(data.max(0))
plt.subplot(1, 3, 3)
plt.ylabel('min')
plt.plot(data.min(0))
plt.tight_layout()
plt.show()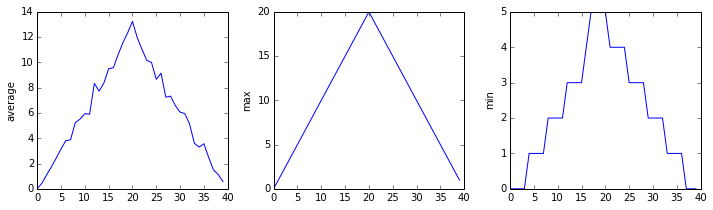
첫 두 라인은 대부분의 파이썬 프로그래머가 사용하는 에일리어스인 np과 plt으로 라이브러리를 다시 적재한다.
loadtxt을 호출하여 데이터를 읽어들이고, 프로그램의 나머지는 플롯팅 라이브러리에게 그래프가 얼마나 커야하는지,
3개의 하위 플롯을 생성한다고, 각각의 하위 플롯에 무엇을 그려넣을 것인지, 그리고 빡빡한 레이아웃으로 설정한다는 것을 담고있다.
(만약 plt.tight_layout()에 맡겨놓으며, 그래프가 좀더 가깝게 압착하게 될 것이다.)
도전 과제
- 프로그램을 변경하여 옆으로 배열되는 대신에 위에서 아래로 배열되도록 3개의 플롯을 화면에 출력하세요.
주요점
import libraryname을 사용하여 프로그램에 라이브러리를 가져온다.numpy라이브러리르 사용하여 파이썬의 배열자료를 작업한다.- 주기억장치 메모리에 값을 저정하기 위해서
variable = value을 사용하여 변수에 값을 할당한다. - 값이 변수에 할당될 때마다 변수가 즉석에서 생성된다.
print something을 사용해서something의 값을 화면에 출력한다.array.shape표현식은 배열의 모양을 반환한다.array[x, y]을 사용하여 배열의 특정 한 요소를 선택한다.- 배열 인덱스는 1이 아니고, 0에서 시작한다.
low:high을 사용해서low에서high-1까지 인텍스를 포함하는 슬라이스를 지정한다.- 배열에서 동작하는 모든 슬라이싱과 인덱싱은 문자열에도 동일하게 동작한다.
# some kind of explanation을 사용하여 프로그램에 주석을 추가한다.- 단순한 통계량을 계산하기 위해서
array.mean(),array.max(),array.min()을 사용한다. array.mean(axis=0)혹은array.mean(axis=1)을 사용하여 주어진 축을 따라서 통계량을 계산한다.matplotlib에서pyplot라이브러리를 사용해서 간단한 시각화 플롯을 생성한다.
다음 단계
지금까지 작업 결과를 통해 데이터 파일에 뭔가 잘못된 것이 있다는 것을 확인했다. 다른 11개 파일도 같은 방식으로 확인하고자 하지만, 동일한 명령어를 반복적으로 타이핑하는 것은 지루하고 오류에 쉽게 노출된다. 컴퓨터는 우리가 알고 있는 한 지루해 하지 않기 때문에, 단일 명령어로 전체 분석을 수행할 수 있는 방법을 생성하고 나서 각 파일에 대해서 각 단계를 어떻게 반복하는지를 해결해야 한다. 이런 작업이 다음 두 학습 주제다.