
다수의 데이터셋 분석하기
하나의 데이터셋에 대해서 일별 염증율의 최소값, 평균값, 최대값의 그래프를 생성하는 함수 analyze를 만들었다.
%matplotlib inline
import numpy as np
from matplotlib import pyplot as plt
def analyze(filename):
data = np.loadtxt(fname=filename, delimiter=',')
plt.figure(figsize=(10.0, 3.0))
plt.subplot(1, 3, 1)
plt.ylabel('average')
plt.plot(data.mean(0))
plt.subplot(1, 3, 2)
plt.ylabel('max')
plt.plot(data.max(0))
plt.subplot(1, 3, 3)
plt.ylabel('min')
plt.plot(data.min(0))
plt.tight_layout()
plt.show()
analyze('inflammation-01.csv')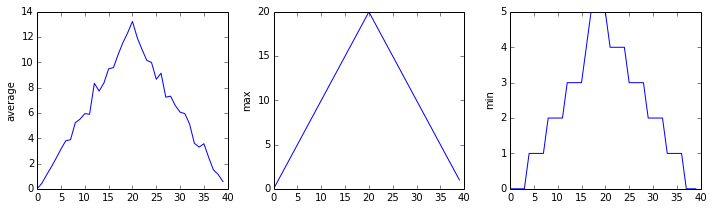
작성한 함수를 사용해서 다른 데이터셋도 하나씩 하나씩 분석할 수 있다.
analyze('inflammation-02.csv')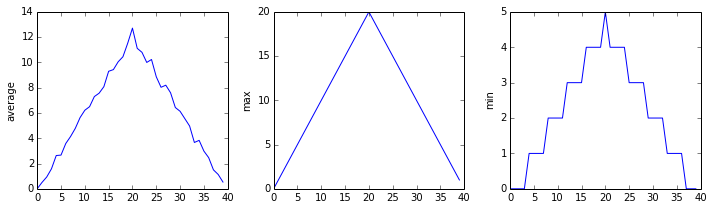
하지만, 지금 당장 12개의 데이터셋이 있고 앞으로 더많은 데이터가 있을 것이다. 하나의 문장으로 모든 데이터에 대해서 그래프를 생성하고자 한다. 이를 위해서 어떻게 반복하는지를 컴퓨터를 학습시켜야 한다.
목표
- for 루프가 무엇을 수행하는지 설명한다.
- 올바르게 for 루프를 작성해서 간단한 계산을 반복한다.
- 루프가 실행될 때, 루프 변수의 변경을 추적한다.
- for 루프로 다른 변수가 갱신될 때, 다른 변수의 변경사항도 추적한다.
- 리스트(list)가 무엇인지 설명한다.
- 간단한 값의 리스트를 생성하고 인덱스한다.
- 라이브러리 함수를 사용해서 간단한 패턴이 매칭되는 파일 목록을 얻는다.
- for 루프를 사용해서 다수의 파일을 처리한다.
For 루프
문장에 각 단어를 출력하고자 한다고 가정하자. 한 방법은 6개의 print 문을 사용한다.
def print_characters(element):
print element[0]
print element[1]
print element[2]
print element[3]
print_characters('lead')l
e
a
d
하지만, 두개의 이유로 좋지 못한 접근법이다.
확장성이 좋지 않다. 만약 수백개 문자로 구성된 문자열의 문자를 화면에 출력한다면, 단순하게 타이핑하는게 더 좋을 것이다.
강건하지가 못하다. 만약 조금 더 긴 벡터를 주면 데이터의 일부분만 화면에 출력한다. 만약 조금 짧은 입력을 준다면, 오류를 생성하는데 이유는 존재하지 않는 문자에 대해서 요청했기 때문이다.
print_characters('tin')---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-13-5bc7311e0bf3> in <module>()
----> 1 print_characters('tin')
<ipython-input-12-11460561ea56> in print_characters(element)
3 print element[1]
4 print element[2]
----> 5 print element[3]
6
7 print_characters('lead')
IndexError: string index out of ranget
i
n
좀더 좋은 접근법이 다음에 있다.
def print_characters(element):
for char in element:
print char
print_characters('lead')좀더 짧고 더 강건하다. 100개 문자열의 각 문자를 화면에 출력하는 것보다 확실히 짧다.
print_characters('oxygen')print_characters 함수의 개선된 버젼은 연산을 반복하기 위해서 for 루프(for loop)를 사용한다. 이 경우에 각각에 대해서 한번만 출력한다. 루프의 일반적인 형태는 다음과 같다.
for variable in collection:
do things with variable
원하는 이름으로 루프 변수(loop variable)를 할 수 있으나, 루프가 시작하는 라인의 끝에 콜론(‘:’)이 있어야 하고 루프의 몸통 부문은 들여쓰기를 해야한다.
반복적으로 변수를 갱신하는 또 다른 루프가 있다.
length = 0
for vowel in 'aeiou':
length = length + 1
print 'There are', length, 'vowels'상기 작은 프로그램의 실행을 단계별로 추적할 가치가 있다. 'aeiou'에 5개 문자가 있어서, 3번 라인의 문장은 5번 실행된다. 첫번째 루프를 돌 때, length는 0 (첫번째 라인에 할당된 값)이고, vowel은 'a'다. length의 이전 값에 1을 더해서 1 이 되고, 새로운 값을 참조하여 length 값을 갱신한다. 다음번에는 vowel이 'e'가되고 length는 1 이 되고, length을 갱신하여 2 가 된다. 3회 더 갱신한 후에 length는 5 가 된다. 파이썬이 처리할 더 이상의 값이 'aeiou'에 남아있지 않아서, 루프는 종료되고, 4번째 라인의 print문이 최종값을 출력한다.
루프 변수는 루프의 상태를 기록하기 위해 사용되는 단지 변수에 불과하다. 루프가 종료된 후에도 여전히 존재한다. 또한 루프 변수와 마찬가지로 앞에서 정의한 변수를 재사용할 수 있다.
letter = 'z'
for letter in 'abc':
print letter
print 'after the loop, letter is', letter문자열의 길이를 찾는 것은 일반적인 연산이라 파이썬은 len으로 불리는 내장 함수가 있음을 주목하세요.
print len('aeiou')len 함수는 여러분이 스스로 작성하는 다른 어떤 함수보다도 훨씬 빠르고 두줄 루프보다 훨씬 읽기 쉽다. len 함수를 사용해서 아직 만나보지 못한 많은 다른 것의 길이도 알 수 있다. 그런 이유로 사용할 수 있다면 len 함수를 항상 사용해야 한다.
도전 과제
파이썬에는 숫자 리스트를 생성하는
range내장 함수가 있다.range(3)는[0, 1, 2],range(2, 5)는[2, 3, 4]숫자 리스트를 생성한다.range를 사용하여 ,N개 숫자를 출력하는 함수를 작성하세요.print_N(3) 1 2 3누승(Exponentiation)은 파이썬의 내장함수다.
print 5**3 125동일한 결과를 계산하는
pow함수도 있다. 동일한 결과를 계산하기 위해서 루프를 사용하는expo함수를 작성하세요.벡터 값의 합을 계산하는 total 함수를 작성하세요. R에는 내장함수 sum이 있어서 동일한 계산을 대신할 수 있지만, 이번 도전과제에는 사용하지 마세요. 문자열을 입력으로 받는
rev함수를 작성해서 역순으로된 문자를 가지는 새로운 문자열을 생성하게 하세요.
항상 그렇지만, docstring을 반듯이 포함하도록 하세요.print rev('Newton') notweN
리스트(Lists)
for 루프가 연산을 많이 하는 방법이듯이, 리스트는 많은 값을 저장하는 방식이다. NumPy 배열과는 다르게, 리스트는 파이썬 언어에 내장되었다. 꺾쇄 괄호에 값을 넣어서 리스트를 생성한다.
odds = [1, 3, 5, 7]
print 'odds are:', odds인덱스를 사용해서 리스트에서 각각의 요소값을 선택한다.
print 'first and last:', odds[0], odds[-1]리스트에 루프를 돌리게 되면, 루프 변수가 루프를 돌 때 한번에 요소값에 할당된다.
for number in odds:
print number리스트와 문자열 사이의 중요한 차이점이 있다. 리스트의 값은 변경할 수 있지만, 문자열의 문자는 변경할 수 없다. 예를 들어,
names = ['Newton', 'Darwing', 'Turing'] # typo in Darwin's name
print 'names is originally:', names
names[1] = 'Darwin' # correct the name
print 'final value of names:', names상기 리스트는 동작하지만,
name = 'Bell'
name[0] = 'b'문자열에서는 동작하지 않는다.
변-변-변-변경(Ch-Ch-Ch-Changes)
변경될 수 있는 데이터는 변경가능(mutable)하다고 하는 반면에 변경할 수 없는 데이터는 변경불가능(immutable)하다고 한다. 문자열과 마찬가지로 숫자도 변경불가능하다. 숫자 0 가 값 1을 갖도록 하거나 그 반대로 만들 수 있는 방법은 없다. (최소한 파이썬은 아니지만, 사용자가 이와 같은 것을 할 수 있게 하는 언어가 있기는 하지만, 예측컨데 혼동스러운 결과를 줄 수 있다.) 반대로 리스트와 배열은 변경가능해서, 생성된 뒤에도 변경할 수 있다. 데이터를 변경하는 프로그램은 변경하지 못하는 프로그램보다 이해하기 더 어려울 수 있는데 이유는 최종 값이 무엇인지를 알아내기 위해서 코드의 많은 행을 읽고 머릿속으로 요약해야 하기 때문이다. 반대로, 작은 변경사항이 생길 때마다 원본과 거의 동일한 복사본을 생성하는 대신에 데이터를 변경하는 프로그램은 훨씬 더 효율적이다.
요소(element)에 할당하는 것과는 별도로 리스트의 내용을 변경하는 방법은 많이 있다.
odds.append(11)
print 'odds after adding a value:', oddsdel odds[0]
print 'odds after removing the first element:', oddsodds.reverse()
print 'odds after reversing:', odds도전 과제
total이라는 함수를 작성해서 리스트의 모든 값의 합을 계산하도록 하세요. (파이썬이sum이라는 내장함수가 있지만 이번 도전과제로 사용하지 마세요.)
다수 파일 처리하기
이제 모든 데이터 파일의 처리에 필요한 거의 모든 것을 갖추었다. 빠진 단 한가지는 다소 유쾌하지 않은 이름을 가진 라이브러리다.
import globglob 라이브러리는 동일하게 glob이라고 불리는 단 한개의 함수가 포함되어 있다. 파일 이름을 패턴과 매칭하여 파일을 찾아내는 함수다. 패턴을 문자열로 전달하는데 와일드 카드 문자 *은 0 혹은 그 이상의 문자를 매칭하는 반면에 ?은 임의의 한 문자만 매칭한다. 지금까지 생성한 모든 IPython Notebooks의 이름을 얻는데 상기 와일드 카드 문자를 사용한다.
print glob.glob('*.ipynb')['01-numpy.ipynb', '02-func.ipynb', '03-loop.ipynb', '04-cond.ipynb', '05-defensive.ipynb', '06-cmdline.ipynb', 'spatial-intro.ipynb']
혹은, 모든 csv 파일 목록을 출력하기 위해서 와일드 카드 문자를 사용한다.
print glob.glob('*.csv')['inflammation-01.csv', 'inflammation-02.csv', 'inflammation-03.csv', 'inflammation-04.csv', 'inflammation-05.csv', 'inflammation-06.csv', 'inflammation-07.csv', 'inflammation-08.csv', 'inflammation-09.csv', 'inflammation-10.csv', 'inflammation-11.csv', 'inflammation-12.csv', 'small-01.csv', 'small-02.csv', 'small-03.csv', 'swc_bc_coords.csv']
상기 예제가 보여주듯이, glob.glob의 결과는 문자열 리스트로 각 파일이름에 대해서 뭔가를 하기 위해서 루프를 반복해야 한다는 것이다. 지금 사례의 경우, 작업하려는 것은 analyze 함수다. 리스트의 첫 3개 파일을 분석해서 시험해보자.
filenames = glob.glob('*.csv')
filenames = filenames[0:3]
for f in filenames:
print f
analyze(f)inflammation-01.csv
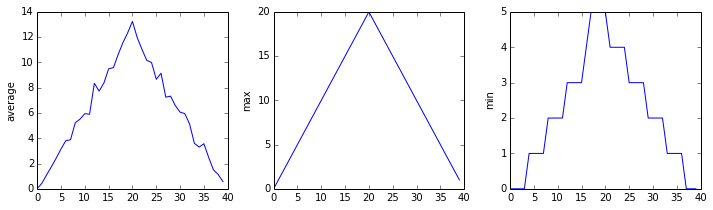
inflammation-02.csv
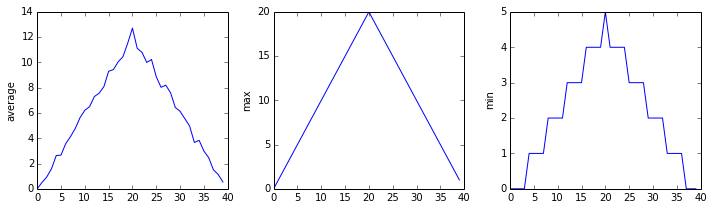
inflammation-03.csv
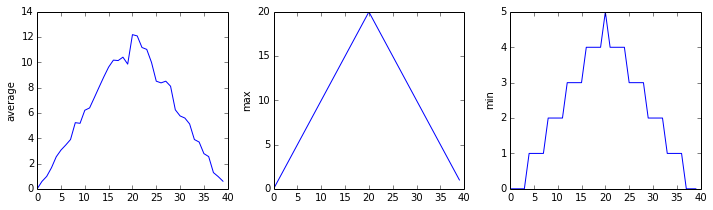
물론, 데이터셋의 최대값은 처음과 동일한 경사를 보여주고, 최소값은 동일한 계단구조를 보여준다.
도전 과제
- 파일 이름 패턴을 인자로만 받는
analyze_all함수를 작성해서 파일 이름과 패턴이 매칭되는 파일에 대해서analyze를 실행하세요.
주요점
for variable in collection을 사용해서 한번에 하나씩 요소를 처리하세요.- for 루프의 몸통 부문은 들여쓰기를 해야한다.
- 다른 값을 담고 있는 것의 길이를 알기 위해서
len(thing)을 사용하세요. [value1, value2, value3, ...]은 리스트를 생성한다.- 문자열과 배열과 동일한 방식으로 리스트를 인덱싱하고 슬라이싱한다.
- 리스트는 변경가능하다. 즉, 값이 변경될 수 있다.
- 문자열은 변경가능하지 않다. 즉, 문자열의 문자는 변경될 수 없다.
glob.glob(pattern)을 사용해서 파일 이름과 패턴이 매칭되는 파일 목록을 생성하세요.- 와일드 카드
*을 사용하여 패턴에서 0 혹은 그 이상 문자를 매칭하고,?은 임의의 한 문자만 매칭하는데 사용한다.
다음 단계
이제 원래 문제를 해결했다. 단일 명령문으로 임의 데이터 파일을 분석할 수 있다. 좀더 중요한 것은 프로그래밍에서 가장 중요한 두가지 아이디어를 경험했다.
- 함수를 사용해서 코드를 재사용하기 쉽게하고 이해하기 쉽게 했다.
- 리스트와 배열을 사용해서 관련된 값을 저장했고, 루프를 사용하여 데이터에 대한 연산을 반복했다.
한가지 더 소개할 큰 아이디가 있다. 그리고 나서 다시 돌아가서 첫번째 데이터셋을 표현하는데 사용된 것과 같은 히트맵(heat map)을 생성한다.