
기후 데이터 작업
목표
- 간단한 REST API를 활용해서 데이터셋을 다운로드하는 파이썬 프로그램을 작성한다.
- CSV가 무엇인지 설명하고 CSV 데이터셋을 읽는다.
1 단계: 데이터 찾기
점점 더 많은 조직에서 REST(REpresentational State Transfer)로 불리는 형식으로 웹상에 데이터셋을 공개한다. REST의 상세한 사항(그리고 사항)이 중요한 것은 아니다; 중요하는 것은 REST가 언제 사용되고, 모든 데이터셋이 URL로 식별된다는 것이다.
예제로 세계은행 기후 데이터 API(Climate Data API)로 제공되는 15개 지구순환모델로 생성되는 데이터를 사용한다. API 홈페이지에 따르면, 다양한 값에 대한 연평균치를 담고 있는 데이터셋은 URL 형태로 식별된다.
http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/var/year/iso3.ext
각 요소는 다음과 같다.:
- var는
pr(강수량) 혹은tas(“지표면 온도”)다; - iso3 국제표준기구(International Standards Organization, ISO)가 정한 국가별 3-문자 코드다. 예를 들어 “CAN”은 캐나다, “BRA”는 브라질이다.
- ext (확장 “extension” 줄임말)은 다운로드받을 데이터 형식을 지정한다. 형식에 대한 몇가지 선택지가 있지만, 가장 간단한 것이 CSV(comma-separated values,콤마구분값)로, 각 레코드는 행이고, 각 행 값은 콤마로 구분된다. (CSV는 스프레드쉬트 데이터에 자주 사용된다.)
예를 들어, 캐나다 연평균기온을 CSV 파일형식으로 원한다면, URL은 다음과 같다:
http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/CAN. csv
상기 URL을 웹브라우져에 붙여넣고 엔터를 치면, 다음이 화면에 출력된다.
year,data
1901,-7.67241907119751
1902,-7.862711429595947
1903,-7.910782814025879
...
2007,-6.819293975830078
2008,-7.2008957862854
2009,-6.997011661529541무대 뒤에서(Behind the Scenes)
상기 특정 데이터셋은 서버에 파일형태로 저장될 수도 있고, 서버가 다음을 수행할 수도 있다:
- 사용자가 입력한 URL을 받는다.
- URL을 조각으로 나눈다.
- 3개 핵심 필드를 추출한다.(변수(var), iso3(국가코드), ext(파일형식)).
- 데이터베이스에서 요청 데이터를 가져온다.
- 데이터를 CSV 형식으로 저장한다.
- 작업결과를 웹브라우져에 전송한다.
세계은행(World Bank)이 URL을 변경하지 않는다면, 프로그램을 변경하지 않고 원하는 데이터를 조건만 변경하여 다운로드할 수 있다.
도전 과제
- 기후자료API(Climate Data API)에 대한 문서(documentation)를 읽고나서, 1980년에서 1999년까지 아프카니스탄(Afghanistan) 평균온도를 검색하는 URL을 작성하세요.
2 단계: 데이터 가져오기
만약 2개 혹은 3개 국가에 대한 데이터만 살펴본다면, 하나씩 파일을 다운로드하기만 하면 된다. 하지만, 다른 많은 나라에 데이터를 비교하고자 한다면 프로그램을 작성해야 한다.
파이썬에는 URL 작업을 위한 urllib2 라이브러리가 있지만, 사용하기가 좀 투박하다. 그래서 많은 사람들은 Requests라는 써드파티 라이브러리를 선호한다. 설치하기 위해서 다음 명령어를 실행한다.
!pip install requests
Requirement already satisfied (use --upgrade to upgrade): requests in c:\python\user\lib\site-packages
Cleaning up...(이미 설치를 했기 때문에 상기 메시지가 나온다; 만약 설치하지 않았다면, 다른 메시지가 나올 것이다.) 이제 다음과 같이 데이터를 불러올 수 있다.
import requests
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/CAN.csv'
response = requests.get(url)
if response.status_code != 200:
print 'Failed to get data:', response.status_code
else:
print 'First 100 characters of data are'
print response.text[:100]
First 100 characters of data are
year,data
1901,-7.67241907119751
1902,-7.862711429595947
1903,-7.910782814025879
1904,-8.15572929382프로그램 첫번째 행은 requests 라이브러리를 가져온다. 두번째 행은 가져올 데이터 URL을 정의한다; 세번째 행에 requests.get 호출에 인자로 URL을 넘길 수도 있지만, 변수로 대입하는 것이 찾기가 더 쉽다.
사실 requests.get이 데이터를 가져온다. 좀더 구체적으로 살펴보면:
climatedataapi.worldbank.org서버에 연결을 생성한다;- 서버에 URL로
/climateweb/rest/v1/country/cru/tas/year/CAN.csv을 전송한다; - 서버 응답결과를 담기 위해서 사용자 컴퓨터 메모리에 객체를 생성한다;
- 요청결과가 성공했는지 아닌지를 식별하기 위해서 객체의
status_code멤버 변수에 숫자를 할당한다. - 웹서버에서 전송받은 데이터를 객체
text멤버 변수에 할당한다.
서버는 다른 많은 상태 코드(status codes)를 반환할 수 있다; 가장 일반적인 것은 다음과 같다:
| 200 | 성공(OK) | 요청 성공. |
| 204 | 콘텐츠 없음(No Content) | 서버가 요청을 수행했지만, 어떤 데이터도 반환할 필요가 없다. |
| 400 | 잘못된 요청(Bad Request) | 서버가 요청의 구문을 인식하지 못했다. |
| 401 | 권한없음(Unauthorized) | 이 요청은 인증이 필요하다. |
| 404 | 찾을 수 없음(Not Found) | 서버가 요청한 페이지를 찾을 수 없다. |
| 408 | 요청 시간초과(Timeout) | 서버의 요청 대기가 시간을 초과하였다. |
| 418 | I’m a teapot | No, really… |
| 500 | 내부 서버 오류(Internal Server Error) | 서버에 오류가 발생하여 요청을 수행할 수 없다. |
상기 상태코드 중에서 정말 신경쓸 것은 단하나 200다; 만약 다른 것을 보게 된다면, 응답은 아마도 실제 데이터를 포함하고 있지 않는다. (오류 메시지를 포함할 수도 있지만)
몇몇 사람들은 규칙을 지키지 않는다.
불행하게도, 몇몇 사이트는 유의미한 상태코드를 반환하지 않는다. 대신에 모두 200를 반환하고, 응답 텍스트에 오류 메시지를 넣는다. 결과가 사람에게 보여진다면 의미가 있지만, 실질적으로 읽을 수 없는 프로그램이 “읽게”된다면 프로그램이 중단된다.
도전 과제
- 상기 프로그램 URL을 변경해서, 존재하지 않는 국가코드를 데이터로 전달해서 상태코드가 어떻게 되는지 살펴보세요.
3 단계: 데이터 파싱
앞에서 작성한 작은 프로그램이 원하는 데이터를 물어다준다. 하지만, 숫자 리스트보다는 한줄 긴 문자열로 반환한다. 긴 문자열을 숫자 리스트로 변환하는 방법이 두가지 있다.
- 함수를 작성해서 개행문자로 문자열을 쪼개서 행을 생성하고 나서, 콤마로 행을 다시 쪼개고 나서, 마지막으로 콤마로 구분된 각 부분을 숫자로 변환한다.
- 사용자를 위해서 상기 작업을 해주는 파이썬 라이브러리를 사용한다.
대부분 경험 많은 프로그래머는 두번째 접근법이 더 쉽다고 말하지만, “쉽다”는 것은 상대적이다: 만약 라이브러리가 존재한다는 것을 인지하고, 충분히 알고 있어서, 라이브러리가 수행하는 것으로 문제를 해결하는 방식을 알고 있다면, 표준 라이브러리를 사용하는 것이 실무에서 좀더 효과적이 된다.
두가지 방식을 함께 시도해 보자. 첫번째 방식으로 작성하는 작은 프로그램이 다음에 있다.
input_data = '''1901,12.3
1902,45.6
1903,78.9'''
as_lines = input_data.split('\n')
print 'input data as lines:'
print as_lines
for line in as_lines:
fields = line.split(',') # turn '1901,12.3' into ['1901', '12.3']
year = int(fields[0]) # turn the text '1901' into the integer 1901
value = float(fields[1]) # turn the text '12.3' into the number 12.3
print year, ':', value
input data as lines:
['1901,12.3', '1902,45.6', '1903,78.9']
1901 : 12.3
1902 : 45.6
1903 : 78.9입력 데이터로 사용될 문자열을 정의하면서 프로그램을 시작한다. 그렇게 함으로서 출력결과의 정합성을 담보할 수 있다. 첫 3줄 코드는 개행문자(프로그램에서 \n을 사용)로 쪼개서 한 다중행 문자열을 문자열 리스트로 변환한다. 그리고 나서, for 루프가 콤마로 행을 쪼개고 숫자로 변환해서 각 행에서 연도(year)와 값(value)을 추출한다.
이스케이프 시퀀스(Escape Sequences)
문자열에 인용부호, 이중 인용부호, 그리고 다른 특수 문자를 표현할 방법이 필요하다. 이를 위해서 이스케이프 시퀀스(escape sequences)를 사용한다.
\'는 단일 인용부호,\"는 이중 인용부호,\n는 개행문자. 등등'This can\'t be\nwritten without\n\"escape sequences\".' 이 의미하는 바는 다음과 같다.출력은 다음과 같다. ~ This can’t be written without “escape sequences”. ~
이제 몇몇 표준 파이썬 라이브러리를 통해서 데이터를 파싱하는 방법을 살펴보자. 첫번째 라이브러리(cStringIO)는 문자열을 마치 입력파일처럼 처리한다.
import cStringIO
data = '''first
second
third'''
reader = cStringIO.StringIO(data)
for line in reader:
print line
first
second
thirdreader에 대입하는 cStringIO.StringIO 객체는 파일처럼 동작하는 객체다. 하지만 하드 드라이브에서 무언가를 읽는 대신에 문자열로부터 문자를 읽어온다. 연습문제에서 보듯이, StringIO 객체에 쓸 수도 있어서, 프로그램을 테스트할 때 매우 유용하다.
왜 ‘c’ 일까?
cStringIO맨처음의 ’c’는 C언어로 작성된 다소 오래되고 속도가 늦은StringIO라이브러리를 다시 작성한 것에 기인한다.
두번재 라이브러리로 csv을 사용한다. csv 라이브러리는 그 자체로 데이터를 읽어들이지 않는다: 대신에, 무언가로 읽어온 행을 받고서, 콤마로 쪼개고 리스트 값으로 변환한다.
import csv
data = '''first,FIRST
second,SECOND
third,THIRD'''
reader = cStringIO.StringIO(data)
wrapper = csv.reader(reader)
for record in wrapper:
print record
['first', 'FIRST']
['second', 'SECOND']
['third', 'THIRD']지금까지 작업한 것을 조합하면, 다음과 같이 Canada에 대한 데이터를 얻을 수 있다.
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/CAN.csv'
response = requests.get(url)
if response.status_code != 200:
print 'Failed to get data:', response.status_code
else:
reader = cStringIO.StringIO(response.text)
wrapper = csv.reader(reader)
for record in wrapper:
year = int(record[0])
value = float(record[1])
print year, ':', value
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-6-da21db395042> in <module>()
7 wrapper = csv.reader(reader)
8 for record in wrapper:
----> 9 year = int(record[0])
10 value = float(record[1])
11 print year, ':', value
ValueError: invalid literal for int() with base 10: 'year'데이터의 첫번째 줄 때문에 오류가 발생했다:
year,data문자열 'year'을 정수형으로 변환할 때, 파이썬이 바로 항의한다. 오류수정은 복잡하지 않다: 단어 year로 시작하는 행을 무시하고 넘어간다. 그리고, 결과를 얻었을 때, 화면에 출력하는 대신에 리스트에 결과를 넣는다.
import requests
import cStringIO
import csv
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/CAN.csv'
response = requests.get(url)
if response.status_code != 200:
print 'Failed to get data:', response.status_code
else:
reader = cStringIO.StringIO(response.text)
wrapper = csv.reader(reader)
results = []
for record in wrapper:
if record[0] != 'year':
year = int(record[0])
value = float(record[1])
results.append([year, value])
print 'first five results'
print results[:5]
first five results
[[1901, -7.67241907119751], [1902, -7.862711429595947], [1903, -7.910782814025879], [1904, -8.155729293823242], [1905, -7.547311305999756]]도전과제
StringIO를 출력에도 사용할 수 있다. 이것을 사용해서print_count함수가 올바로 작동하는 테스트 함수를 작성하세요. ~ def print_count(output, num): for i in range(num): print >> output, num ~
4 단계: 재사용가능한 함수 작성하기
캐나다에 대한 데이터를 얻는 방법을 이제 알게되었으니, 임의 나라에 대해서 동일한 작업을 수행하는 함수를 작성하자. 단계는 단순하다: 작성한 코드를 복사해서 매개변수로 3-문자 국가코드를 받아서 적당한 곳에 URL에 국가코드를 삽입하는 함수를 작성한다.
def get_annual_mean_temp_by_country(country):
'''Get the annual mean temperature for a country given its 3-letter ISO code (such as "CAN").'''
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/' + country + '.csv'
response = requests.get(url)
if response.status_code != 200:
print 'Failed to get data:', response.status_code
else:
reader = cStringIO.StringIO(response.text)
wrapper = csv.reader(reader)
results = []
for record in wrapper:
if record[0] != 'year':
year = int(record[0])
value = float(record[1])
results.append([year, value])
return results다음과 같이 동작한다.
canada = get_annual_mean_temp_by_country('CAN')
print 'first five entries for Canada:', canada[:5]
first five entries for Canada: [[1901, -7.67241907119751], [1902, -7.862711429595947], [1903, -7.910782814025879], [1904, -8.155729293823242], [1905, -7.547311305999756]]하지만 문제가 있다. 유효하지 않는 국가 식별자를 매개변수로 전달할 때 무슨일이 발생하는지 살펴보자.
latveria = get_annual_mean_temp_by_country('LTV')
print 'first five entries for Latveria:', latveria[:5]
first five entries for Latveria: []Latveria는 존재하지 않는다. 그래서 왜 작성한 함수는 오류 메시지를 출력하는 대신에 빈 리스트를 반환할까? 오류 메시지가 없다는 의미는 응답코드가 200을 의미한다: 만약 그렇다면, else 브랜치로 가서 result에 빈 리스트를 대입하고 그리고… 흠… 좋아… 만약 응답코드가 200 이고 데이터가 없다면, 그 자체가 사용자가 보는 것을 설명한다.
편집(Editing) vs. 복사(Copying)
실제 자료분석에서 사용하려고 함수를 작성하고 있다면, 다시 돌아가서 그 위치에서 변경한다. 오류 버젼과 수정버젼을 함께 보여주기 위해서 대신에 함수를 복사했다.
def get_annual_mean_temp_by_country(country):
'''Get the annual mean temperature for a country given its 3-letter ISO code (such as "CAN").'''
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/' + country + '.csv'
print 'url used is', url
response = requests.get(url)
print 'response code:', response.status_code
print 'length of data:', len(response.text)
if response.status_code != 200:
print 'Failed to get data:', response.status_code
else:
reader = cStringIO.StringIO(response.text)
wrapper = csv.reader(reader)
results = []
for record in wrapper:
if record[0] != 'year':
year = int(record[0])
value = float(record[1])
results.append([year, value])
return results
latveria = get_annual_mean_temp_by_country('LTV')
print 'number of records for Latveria:', len(latveria)
url used is http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/LTV.csv
response code: 200
length of data: 0
number of records for Latveria: 0훌륭해: 약간 더 실험한 후에, 세계은행 사이트는 항상 200 상태 코드를 반환하는 것을 발견했다. 실제 데이터가 있는지 없는지를 알 수 있는 유일한 방식은 response.text가 비었는지(empty) 점검하는 것이다. 다음에 갱신된 함수가 있다.
def get_annual_mean_temp_by_country(country):
'''
Get the annual mean temperature for a country given its 3-letter ISO code (such as "CAN").
Returns an empty list if the country code is invalid.
'''
url = 'http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/' + country + '.csv'
response = requests.get(url)
results = []
if len(response.text) > 0:
reader = cStringIO.StringIO(response.text)
wrapper = csv.reader(reader)
for record in wrapper:
if record[0] != 'year':
year = int(record[0])
value = float(record[1])
results.append([year, value])
return results
print 'number of records for Canada:', len(get_annual_mean_temp_by_country('CAN'))
print 'number of records for Latveria:', len(get_annual_mean_temp_by_country('LTV'))
number of records for Canada: 112
number of records for Latveria: 0도전 과제
- 다운로드 받을 데이터가 없을 때, 함수는 오류 메시지를 출력해야할까요? 왜 혹은 왜 그렇지 않을까요?
5 단계: 국가 비교하기
다른 국가에 대한 지상 기온을 얻을 수 있기 때문에, 국가 온도를 비교하는 함수를 작성할 수 있다. (이제 궁극적으로 작업하려는 것에 대해 명확해졌기 때문에, 바로 함수를 작성한다.) 다음에 작성한 첫번째 함수가 있다.
def diff_records(left, right):
'''Given lists of [year, value] pairs, return list of [year, difference] pairs.'''
num_years = len(left)
results = []
for i in range(num_years):
left_year, left_value = left[i]
right_year, right_value = right[i]
difference = left_value - right_value
results.append([left_year, difference])
return results여기서 루프 제어를 위해서 left에 항목 숫자를 사용한다. (항목숫자는 len(left)로 알 수 있다.)
다음 표현식
for i in range(num_years):0부터 num_years-1까지 i를 실행한다. 정확하게 left 인덱스와 상응한다. 루프 내부에서 리스트 항목에서 왼쪽, 오른쪽 년도와 값을 풀어서 년도와 차이값을 results에 추가한다. 그리고 마지막에 결과를 반환한다.
작성한 함수가 동작하는지 살펴보기 위해서, 몇개 테스트 데이터를 작성해서 실행한다.
print 'one record:', diff_records([[1900, 1.0]],
[[1900, 2.0]])
print 'two records:', diff_records([[1900, 1.0], [1901, 10.0]],
[[1900, 2.0], [1901, 20.0]])
one record: [[1900, -1.0]]
two records: [[1900, -1.0], [1901, -10.0]]매우 좋아 보인다— 하지만, 다음 테스트 케이스는 어떨까?
print 'mis-matched years:', diff_records([[1900, 1.0]],
[[1999, 2.0]])
print 'left is shorter', diff_records([[1900, 1.0]],
[[1900, 10.0], [1901, 20.0]])
print 'right is shorter', diff_records([[1900, 1.0], [1901, 2.0]],
[[1900, 10.0]])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-15-7582f56db8bf> in <module>()
4 [[1900, 10.0], [1901, 20.0]])
5 print 'right is shorter', diff_records([[1900, 1.0], [1901, 2.0]],
----> 6 [[1900, 10.0]])
<ipython-input-13-67464343fd99> in diff_records(left, right)
5 for i in range(num_years):
6 left_year, left_value = left[i]
----> 7 right_year, right_value = right[i]
8 difference = left_value - right_value
9 results.append([left_year, difference])
IndexError: list index out of range
mis-matched years: [[1900, -1.0]]
left is shorter [[1900, -9.0]]
right is shorter설사 년도가 매칭되지 않지만, 첫번째 테스트는 답을 제시한다: 결과값을 얻었지만, 무의미하다. 두번째 테스트 케이스는 부분적인 결과를 제시한다. 이번에도 문제가 있다고 보고하지는 않는다. 하지만, 세번째는 프로그램이 중단된다. 왜냐하면 레코드 숫자를 결정하는데 left를 사용하지만, right는 그만큼의 숫자를 가지고 있지 않기 때문이다.
첫 두 문제는 세번째 것보다 사실 더 나쁘다. 왜냐하면 첫 두 문제가 침묵하는 실패(silent failures)이기 때문이다: 함수가 잘못된 것을 수행하지만, 어떤 방식으로도 나타내지 않는다. 버그를 수정해보자:
def diff_records(left, right):
'''
Given lists of [year, value] pairs, return list of [year, difference] pairs.
Fails if the inputs are not for exactly corresponding years.
'''
assert len(left) == len(right), \
'Inputs have different lengths.'
num_years = len(left)
results = []
for i in range(num_years):
left_year, left_value = left[i]
right_year, right_value = right[i]
assert left_year == right_year, \
'Record {0} is for different years: {1} vs {2}'.format(i, left_year, right_year)
difference = left_value - right_value
results.append([left_year, difference])
return results“착한” 테스트 케이스는 통과했나요?
print 'one record:', diff_records([[1900, 1.0]],
[[1900, 2.0]])
print 'two records:', diff_records([[1900, 1.0], [1901, 10.0]],
[[1900, 2.0], [1901, 20.0]])
one record: [[1900, -1.0]]
two records: [[1900, -1.0], [1901, -10.0]]이제 실패가 예상되는 세가지 테스트 케이스는 어떤가요?
print 'mis-matched years:', diff_records([[1900, 1.0]],
[[1999, 2.0]])
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-18-c101917a748e> in <module>()
1 print 'mis-matched years:', diff_records([[1900, 1.0]],
----> 2 [[1999, 2.0]])
<ipython-input-16-d41327791c15> in diff_records(left, right)
10 left_year, left_value = left[i]
11 right_year, right_value = right[i]
---> 12 assert left_year == right_year, 'Record {0} is for different years: {1} vs {2}'.format(i, left_year, right_year)
13 difference = left_value - right_value
14 results.append([left_year, difference])
AssertionError: Record 0 is for different years: 1900 vs 1999
mis-matched years:
print 'left is shorter', diff_records([[1900, 1.0]],
[[1900, 10.0], [1901, 20.0]])
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-19-682d448d921e> in <module>()
1 print 'left is shorter', diff_records([[1900, 1.0]],
----> 2 [[1900, 10.0], [1901, 20.0]])
<ipython-input-16-d41327791c15> in diff_records(left, right)
4 Fails if the inputs are not for exactly corresponding years.
5 '''
----> 6 assert len(left) == len(right), 'Inputs have different lengths.'
7 num_years = len(left)
8 results = []
AssertionError: Inputs have different lengths.
left is shorter
print 'right is shorter', diff_records([[1900, 1.0], [1901, 2.0]],
[[1900, 10.0]])
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-20-a475e608dd70> in <module>()
1 print 'right is shorter', diff_records([[1900, 1.0], [1901, 2.0]],
----> 2 [[1900, 10.0]])
<ipython-input-16-d41327791c15> in diff_records(left, right)
4 Fails if the inputs are not for exactly corresponding years.
5 '''
----> 6 assert len(left) == len(right), 'Inputs have different lengths.'
7 num_years = len(left)
8 results = []
AssertionError: Inputs have different lengths.
right is shorter정말 훌륭해요: 만약 형식이 올바르지 않거나 부합하지 않는 데이터를 처리하려고 한다면, 추가한 가정대입문이 이제 경고를 보낸다.
더 좋은 방법이 있다.
프로그램 셀 내부에서 각 테스트를 실행해야만 한다. 왜냐하면, 가정대입문이 실패하자마자 코드 실행을 파이썬이 멈추기 때문이고, 테스트 3개가 모두 실질적으로 실행되도록 확실히 하고자 한다. 단위 테스트 (unit testing) 라이브러리가 사용자를 대신해서 처리하고, 또한 그밖의 더 많은 것도 수행한다; 파이썬 중급과정에서 단위 테스트 라이브러리를 다룬다.
도전 과제
데이터를 다운로드 받지 못할 경우,
get_annual_mean_temp_by_country함수는 가정대입문을 사용해야 할까? 왜 혹은 왜 그렇지 않을까?for에서 종종 사용되는enumerate라는 함수가 파이썬에 포함되어 있다. 다음 루프는 ~ for (i, c) in enumerate(‘abc’): print i, ‘=’, c ~ 아래와 같이 출력한다. ~ 0 = a 1 = b 2 = c ~enumerate를 사용해서diff_records를 재작성하세요.
6 단계: 모두 함께 놓아보자
이제 국가별로 기온차이를 시각화하는데 필요한 모든 도구를 갖게 되었다.
%matplotlib inline
from matplotlib import pyplot as plt
australia = get_annual_mean_temp_by_country('AUS')
canada = get_annual_mean_temp_by_country('CAN')
diff = diff_records(australia, canada)
plt.plot(diff)
plt.show()
png
이것은 원하는 바가 아니다: 라이브러리가 리스트 짝을 하나의 곡선에 대한 (x,y) 좌표라기 보다는 두개 상응하는 곡선으로 해석했다. (year, difference) 리스트 짝을 NumPy 배열로 변환하자.
import numpy as np
d = np.array(diff)그리고 나서, 두번째 칼럼에 첫번째 칼럼을 플롯(plot)한다.
plt.plot(d[:, 0], d[:, 1])
plt.show()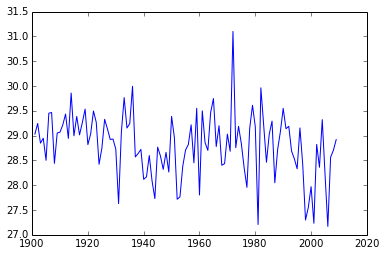
png
차이(difference)가 천천히 줄어드는 것처럼 보이지만, 신호(signal)에 잡음(noise)이 많다. 이 지점에서, 만약 실질적 해답을 구한다면, 곡선맞춤(curve-fitting) 라이브러리를 열어볼 시점이다.
도전 과제
- 플롯(plot) 명령어를 변경해서 Y축 스케일을 0에서 32로 바꾼다. 이렇게 스케일을 변경하는 것이 데이터에 대한 좀더 정확한 혹은 덜 정확한 시점을 준다고 생각합니까?
주요점
- 많은 인터넷 사이트는 특정 방식으로 데이터를 가공해서 URL을 통해서 다운로드할 수 있도록 데이터를 공개한다.
requests라이브러리를 사용해서 파이썬 프로그램에서 데이터를 다운로드한다.cStringIO라이브러리를 사용해서 텍스트를 입력 혹은 출력 파일로 다룰 수 있다.csv라이브러리를 사용해서 콤마 구분 값(comma-separated values)을 읽어온다.- 테스트를 작성한다.