
유닉스 쉘(Unix Shell)
파이프와 필터
학습 목표
- 명령어 출력결과를 파일로 다시 보낸다.
- 키보드 입력 대신에 다시 보내기(redirection)를 사용하여 파일을 처리한다.
- 2단계 혹은 3단계로 명령문 파이프라인을 구성한다.
- 프로그램 혹은 파이프라인에 처리할 입력을 주지 않았을 때 통상 발생하는 일을 설명한다.
- “작은 조각, 느슨하게 결합하기(small pieces, loosely joined)”라는 유닉스 철학을 설명한다.
몇가지 기초 유닉스 명령어를 배웠기 때문에, 마침내 쉘의 가장 강령한 기능을 살펴볼 수 있게 되었다: 새로운 방식으로 기존에 존재하던 프로그램을 쉽게 조합해 낼 수 있게 한다. 간단한 유기분자 설명을 하는 6개 파일을 담고 있는 molecules(분자)라는 디렉토리에서 시작한다. .pdb 파일 확장자는 단백질 데이터 은행 (Protein Data Bank) 형식으로, 분자의 각 원자 형식과 위치를 표시하는 간단한 텍스트 형식으로 되어 있다.
$ ls moleculescubane.pdb ethane.pdb methane.pdb
octane.pdb pentane.pdb propane.pdb명령어 cd로 해당 디렉토리로 가서 wc *.pdb 명령어를 실행한다. wc 명령어는 “word count”의 축약어로 파일의 라인 수, 단어수, 문자수를 개수한다. *.pdb에서 *은 0 혹은 더 많이 일치하는 문자를 찾는다. 그래서 쉘은 *.pdb을 통해 .pdb 전체 리스트 목록을 반환한다:
$ cd molecules
$ wc *.pdb 20 156 1158 cubane.pdb
12 84 622 ethane.pdb
9 57 422 methane.pdb
30 246 1828 octane.pdb
21 165 1226 pentane.pdb
15 111 825 propane.pdb
107 819 6081 totalwc 대신에 wc -l을 실행하면, 출력결과는 파일마다 행수만을 보여준다:
$ wc -l *.pdb 20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 total단어 숫자만을 얻기 위해서 -w, 문자 숫자만을 얻기 위해서 -c을 사용할 수 있다.
파일 중에서 어느 파일이 가장 짧을까요? 단지 6개의 파일이 있기 때문에 질문에 답하기는 쉬울 것이다. 하지만 만약에 6000 파일이 있다면 어떨까요? 해결에 이르는 첫번째 단계로 다음 명령을 실행한다:
$ wc -l *.pdb > lengths.txt> 은 쉘로 하여금 화면에 처리 결과를 뿌리는 대신에 파일로 되돌리기(redirect)게 한다. 만약 파일이 존재하지 않으면 파일을 생성하고 파일이 존재하면 파일에 내용을 덮어쓰기 한다. 조용하게 덮어쓰기 하기 때문에 자료가 유실될 수 있어서 주의가 요구된다. (이것이 왜 화면에 출력결과가 없는 이유다. wc가 출력하는 모든 것은 lengths.txt 파일에 대신 들어간다.) ls lengths.txt 을 통해 파일이 존재하는 것을 확인한다:
$ ls lengths.txtlengths.txtcat lengths.txt을 사용해서 화면으로 lengths.txt의 내용을 보낼 수 있다. cat은 “concatenate”를 줄인 것이고 하나씩 하나씩 파일의 내용을 출력한다. 이번 사례에는 단지 하나의 파일이 있어서 cat는 단지 한 파일이 담고 있는 내용만을 보여준다:
$ cat lengths.txt 20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 totalsort 명령어를 사용해서 파일 내용을 정렬합니다. -n 옵션을 사용해서 알파벳 대신에 숫자 방식으로 정렬할 것임을 표시한다. 이 명령어는 파일 자체를 변경하지 않고 대신에 정렬된 결과를 화면으로 보낸다:
$ sort -n lengths.txt 9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
107 total> lengths.txt을 사용해서 wc 실행결과를 lengths.txt에 넣었듯이, 명령문 다음에 > sorted-lengths.txt을 넣음으로서, 임시 파일이름인 sorted-lengths.txt에 정렬된 목록 정보를 담을 수 있다. 이것을 실행한 다음에, 또 다른 head 명령어를 실행해서 sorted-lengths.txt에서 첫 몇 행을 뽑아낼 수 있다:
$ sort -n lengths.txt > sorted-lengths.txt
$ head -1 sorted-lengths.txt 9 methane.pdbhead에 -1 매개변수를 사용해서 파일의 첫번째 행만이 필요하다고 지정한다. -20은 처음 20개 행만을 지정한다. sorted-lengths.txt이 가장 작은 것에서부터 큰 것으로 정렬된 파일 길이 정보를 담고 있어서, head의 출력 결과는 가장 짧은 행을 가진 파일이 되어야만 된다.
이것이 혼란스럽다고 생각한다면, 여러분은 정말 좋은 회사에 다니고 있는 것이다: wc, sort, head 명령어가 무엇을 수행하는지 이해해도, 중간에 산출되는 파일에 무슨 일이 진행되고 있는지 따라가기는 쉽지 않다. sort와 head을 함께 실행해서 이해하기 훨씬 쉽게 만들 수 있다:
$ sort -n lengths.txt | head -1 9 methane.pdb두 명령문 사이의 수직 막대를 파이프(pipe)라고 부른다. 수직막대는 쉘에게 왼편 명령문의 출력결과를 오른쪽 명령문의 입력값으로 사용된다는 말을 전달한다. 컴퓨터는 필요하면 임시 파일을 생성하거나, 한 프로그램에서 주기억장치의 다른 프로그램으로 데이터를 복사하거나, 혹은 완전히 다른 작업을 수행할 수도 있다; 사용자는 알 필요도 없고 관심을 가질 이유도 없다.
또 다른 파이프를 사용해서 wc의 출력결과를 sort에 바로 보내고 나서, 다시 처리 결과를 head에 보낸다:
$ wc -l *.pdb | sort -n | head -1 9 methane.pdb이것이 정확하게 수학자가 log(3x) 같은 중첩함수를 사용하는 것과 같다. “log(3x)은 x에 3을 곱하고 로그를 취하는 것과 같다.” 이번 경우는, *.pdb의 행수를 세어서 정렬된 첫 부분을 계산하는 것이 된다.
파이프를 생성할 때 뒤에서 실질적으로 일어나는 일은 다음과 같다. 컴퓨터가 한 프로그램(어떤 프로그램도 동일)을 실행할 때 프로그램에 대한 소프트웨어와 현재 상태 정보를 담기 위해서 주기억장치 메모리에 프로세스(process)를 생성한다. 모든 프로세스는 표준 입력(standard input)이라는 입력 채널을 가지고 있다. (여기서 이름이 너무 기억하기 좋아서 놀랄지도 모른다. 하지만 걱정하지 마세요. 대부분의 유닉스 프로그래머는 “stdin”이라고 부른다). 또한 모든 프로세스는 표준 출력(standard output)(혹은 “stdout”)이라고 불리는 기본디폴트 출력 채널도 있다.
쉘은 실질적으로 또다른 프로그램이다. 정상적인 상황에서 사용자가 키보드로 무엇을 타이핑하는 모든 것은 표준 입력으로 쉘에 보내지고, 표준 출력에서 만들어지는 무엇이든지 화면에 출력된다. 쉘에게 프로그램을 실행하게 할때, 새로운 프로게스를 생성하고, 임시로 키보드에 타이핑하는 무엇이든지 그 프로세스의 표준 입력으로 보내지고, 프로세스는 표준 출력에 무엇이든지 화면에 전송한다.
wc -l *.pdb > lengths을 실행할 때 여기서 일어나는 것을 설명하면 다음과 같다. wc 프로그램을 실행할 새로운 프로세스를 생성하라고 컴퓨터에 말하면서 쉘이 시작된다. 파일이름을 매개변수로 제공했기 때문에 표준입력 대신 wc는 매개변수에서 입력값을 읽어온다. >을 사용해서 출력값을 파일에 되돌리기 하는데 사용했기 때문에, 쉘은 프로세스의 표준 출력결과를 파일에 연결한다.
wc -l *.pdb | sort -n을 실행한다면, 쉘은 프로세스 두개를 생성한다. (파이프 프로세스 각각에 대해서 하나씩) 그래서 wc과 sort은 동시에 실행된다. wc의 표준출력은 직접적으로 sort의 표준 입력으로 들어간다; >같은 되돌리기가 없기 때문에 sort의 출력은 화면으로 나가게 된다. wc -l *.pdb | sort -n | head -1을 실행하면, 파일에서 wc에서 sort로, sort에서 head을 통해 화면으로 나가게 되는 데이터 흐름을 가진 프로세스 3개가 있게 된다.
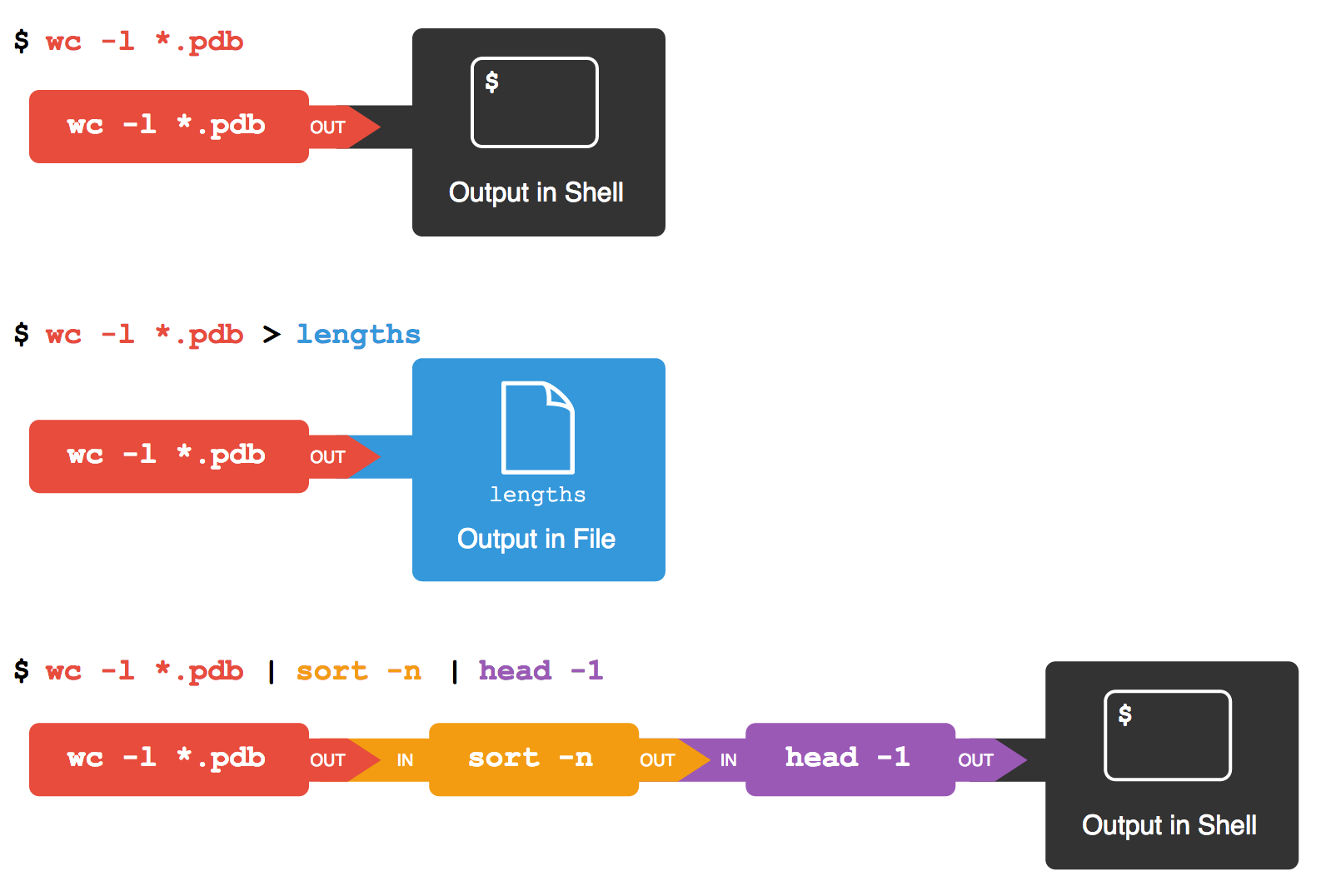
되돌리기와 파이프
이 간단한 아이디어가 왜 유닉스가 그토록 성공적이었는지를 보여준다. 다른 많은 작업을 수행하는 거대한 프로그램을 생성하는 대신에, 유닉스 프로그래머는 각자가 한가지 작업만을 잘 수행하는 간단한 도구를 많이 생성하는데 집중하고, 서로간에 유기적으로 잘 작동하게 만든다. 이러한 프로그래밍 모델을 파이프와 필터(pipes and filters)라고 부른다; 파이프는 이미 살펴봤고, 필터(filter)는 wc, sort같은 프로그램으로 입력 스트림을 출력 스트림으로 변환하는 것이다. 거의 모든 표준 유닉스 도구는 이런 방식으로 동작한다: 별도로 언급되지 않는다면, 표준 입력에서 읽고, 읽은 것을 가지고 무언가를 수행하고 표준출력에 쓴다.
중요한 점은 표준입력에서 텍스트 행을 읽고 표준 출력에 텍스트 행을 쓰는 임의 프로그램은 이런 방식으로 동작하는 모든 다른 프로그램과 조합될 수 있다는 것이다. 여러분도 여러분이 작성한 프로그램을 이러한 방식으로 작성할 수 있어야 하고 작성해야 한다. 그래서 여러분과 다른 사람들이 이러한 프로그램을 파이프에 넣어서 프로그램의 힘을 배가할 수 있다.
Nelle의 파이프라인 Pipeline: 파일 확인하기
앞에서 설명한 것처럼 Nelle은 분석기를 통해 시료를 시험해서 1520개 파일을 north-pacific-gyre/2012-07-03 디렉토리에 생성했다. 빠르게 건전성 확인하기 위해, 홈디렉토리에서 시작해서, 다음과 같이 타이핑한다:
$ cd north-pacific-gyre/2012-07-03
$ wc -l *.txt결과는 다음과 같은 1520 행이 출력된다:
300 NENE01729A.txt
300 NENE01729B.txt
300 NENE01736A.txt
300 NENE01751A.txt
300 NENE01751B.txt
300 NENE01812A.txt
... ...이번에는 다음과 같이 타이핑한다:
$ wc -l *.txt | sort -n | head -5 240 NENE02018B.txt
300 NENE01729A.txt
300 NENE01729B.txt
300 NENE01736A.txt
300 NENE01751A.txt이런, 파일중에 하나가 다른 것보다 60행이 짧다. 다시 돌아가서 확인하면, 월요일 아침 8:00 시각에 분석을 수행한 것을 알고 있다 — 아마도 누군가 주말에 기계를 사용했고, 다시 재설정하는 것을 깜빡 잊었을 것이다. 시료를 다시 시험하기 전에 파일중에 너무 큰 데이터가 있는지를 확인한다:
$ wc -l *.txt | sort -n | tail -5 300 NENE02040A.txt
300 NENE02040B.txt
300 NENE02040Z.txt
300 NENE02043A.txt
300 NENE02043B.txt숫자는 좋아 보인다 — 하지만 끝에서 세번째 줄에 ‘Z’는 무엇일까? 모든 시료는 ’A’ 혹은 ’B’로 표시되어야 한다. 시험실 관례로 ’Z’는 결측치가 있는 시료를 표식하기 위해 사용된다. 더 많은 결측 시료를 찾기 위해, 다음과 같이 타이핑한다:
$ ls *Z.txtNENE01971Z.txt NENE02040Z.txt노트북의 로그 이력을 확인할 때, 상기 샘플 각각에 대해 깊이(depth) 정보에 대해서 기록된 것이 없었다. 다른 방법으로 정보를 더 수집하기에는 너무 늦어서, 분석에서 두 파일을 제외하기로 했다. rm 명령어를 사용하여 삭제할 수 있지만, 향후에 깊이(depth)정보가 관련없는 다른 분석을 실시할 수도 있다. 그래서 와일드 카드 표현식 *[AB].txt을 사용하여 파일을 조심해서 선택하기로 한다. 언제나 그렇듯이, ’*’는 임의 숫자의 문자를 매칭한다. [AB] 표현식은 ’A’혹은 ’B’를 매칭해서 Nelle이 가지고 있는 유효한 데이터 파일 모두를 매칭한다.
sort -n 명령어는 어떤 작업을 수행할까?
다음 파일에 sort를 실행하면:
10
2
19
22
6출력결과는 다음과 같다.
10
19
2
22
6동일한 입력에 대해서 sort -n을 실행하면, 대신에 다음 결과를 얻게 된다:
2
6
10
19
22인수 -n이 왜 이런 효과를 가지는지 설명하세요.
<은 무엇을 의미하는가?
다음 명령문과
wc -l < mydata.dat다음 명령문의 차이점은 무엇인지 설명하세요.
wc -l mydata.dat>>은 무엇을 의미하는가?
다음 명령문과
echo hello > testfile01.txt다음 명령문의 차이점은 무엇인지 설명하세요.
echo hello >> testfile02.txt힌트: 각 명령문을 연속해서 두번 실행하고 나서, 출력결과로 나온 파일을 면밀히 조사한다.
명령문을 함께 파이프로 연결하기
현재 작업 디렉토리에, 최소 3줄씩을 갖는 파일 세개가 있다. 아래 열거된 어떤 명령어 중 어떤 것이 제대로 동작할까요?
wc -l * > sort -n > head -3wc -l * | sort -n | head 1-3wc -l * | head -3 | sort -nwc -l * | sort -n | head -3
uniq가 왜 인접한 중복 행만을 단지 제거한다고 생각합니까?
명령문 uniq는 입력으로부터 인접한 중복된 행을 제거한다. 예를 들어, salmon.txt 파일에 다음이 포함되었다면,
coho
coho
steelhead
coho
steelhead
steelheaduniq salmon.txt 명령문 실행은 다음을 출력한다.
coho
steelhead
coho
steelheaduniq가 왜 인접한 중복 행만을 단지 제거한다고 생각합니까? (힌트: 매우 큰 파일을 생각해보세요.) 모든 중복된 행을 제거하기 위해, 파이프로 다른 어떤 명령어를 조합할 수 있을까요?
파이프 독해능력
animals.txt로 불리는 파일은 다음 데이터를 포함한다
2012-11-05,deer
2012-11-05,rabbit
2012-11-05,raccoon
2012-11-06,rabbit
2012-11-06,deer
2012-11-06,fox
2012-11-07,rabbit
2012-11-07,bear다음 아래 파이프라인에 각 파이프를 통과하고, 마지막 되돌리기를 마친 텍스트는 무엇일까요?
cat animals.txt | head -5 | tail -3 | sort -r > final.txt파이프 구성하기
다음 명령문을 실행하면,
$ cut -d , -f 2 animals.txt다음 출력결과를 만들어 낸다.
deer
rabbit
raccoon
rabbit
deer
fox
rabbit
bear파일에 담겨 있는 동물이 무엇인지를 알아내려면, 다른 어떤 명령어가 파이프라인에 추가되어야 하나요? (동물 이름에 어떠한 중복도 없어야 합니다.)