
xwMOOC 기계학습
3가지 기계학습 원리
학습목표
- 3가지 기계학습 원리에 대해 이해한다.
- 오컴의 면도날, 표집 편향, 데이터 염탐 편향을 이해한다.
3대 기계학습 원리 1
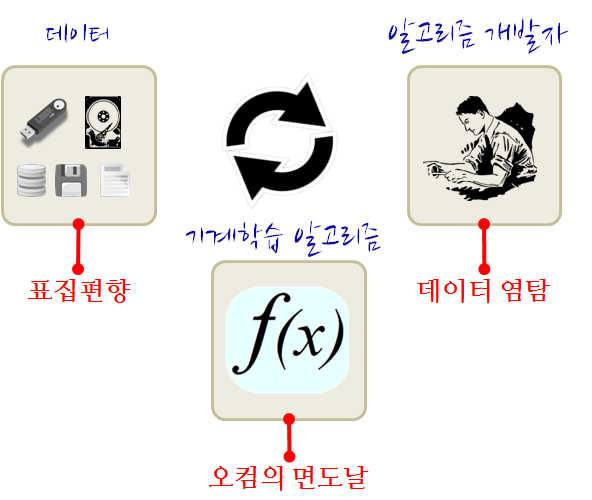
기계학습 알고리즘 개발자가 데이터를 학습시켜 기계학습 알고리즘을 뽑아내는 과정에 3대 기계학습 원리가 적용된다.
- 오컴의 면도날(Occam’s Razor): 사고 절약의 원리(Principle of Parsimony)라고도 불리며, 같은 현상을 설명하는 두가지 모형이 있다면, 단순한 모형을 선택한다.
- 표집 편향(Sampling Bias): 모집단을 대표성의 원리에 따라 표본을 추출하지 못할 때, 기계학습 알고리즘도 편향된 표본을 학습하여 결과를 왜곡시킨다.
- 데이터 염탐 편향(Data Snooping Bias): 데이터를 본 후에 기계학습 알고리즘을 결정하는 것으로, 사실 데이터를 보기 전에 기계학습 알고리즘을 선정해야 된다.
1. 오컴의 면도날
동일한 조건이면 더 단순한 것을 선택하는 것으로, 가장 큰 이유는 갖고 있는 데이터를 벗어나 새로운 데이터를 갖게 될 경우 학습시킨 기계학습 알고리즘이 더 좋은 성능을 보인다는 것이다. 결국 수많은 가능한 모형중에서 하나를 선택하는 기준이 된다.
An explanation of the data should be made as simple as possible, but no simpler – Albert Einstein
2. 표집 편향
1948년 미국 대통령선거에서 트루먼이 듀이 후보를 물리치고 대통령이 된 것은 알려진 사실이다. 하지만, 대부분의 여론조사에서 듀이의 승리를 예상했지만, 사실은 그 반대로 나타났다. 그 당시 여론조사를 전화기를 사용하였는데, 문제는 전화기가 부유층이 많이 소유하고 있어 미국 대통령선거 모집단을 대표하는 대표성에 문제가 있어 왜곡된 결과가 도출된 것이다.
상업적으로 개인금융의 신용카드발급, 신용평가에도 동일한 문제가 발생한다. 사실 수익성은 저신용자가 높아 이를 살펴보면, 신용평가에 사용될 데이터는 저신용자는 카드를 발급받을 수 없어 데이터베이스에는 표집편향된 고객정보만 존재하는 것을 어렵지 않게 볼 수 있다.
If the data is sampled in a biased way, learning will produce a similarly biased outome.
3. 데이터 염탐 편향
데이터를 본 후에 기계학습 알고리즘을 결정하는 것으로, 사실 데이터를 보기 전에 기계학습 알고리즘을 선정해야 하지만, 현실적으로 현업에서 작업하는 사람들이 흔히 범하는 실수다. 동일한 데이터에 대해 갖가지 기계학습 알고리즘을 적용해서 가장 좋은 성능이 나오는 알고리즘을 선정한다. 문제는 데이터가 바뀌면 어떨까? 아마 기대했던 성능이 나오지 못할 가능성이 크다.
If you torture the data long enough, it will confess