
xwMOOC 기계학습
기계학습 운영 - 파이프라인
학습목표
- 기계학습과 딥러닝 실제 적용을 준비한다.
- 다양한 디버깅 전략을 살펴본다.
- 천정 분석에 대한 중요성을 인식한다.
1. 기계학습 완성 과정
- 기계학습 설계 과정
- 목표 설정: 오차 측도 설정, 목표 변수 설정
- 시작과 끝을 잇는 파이프라인 구축: 성능 측정 및 모니터링 측도 포함 자동화 프로세스 구축
- 성능 문제점을 잘 파악하도록 시스템을 계측: 성능이 떨어지는 구성요소를 진단하고, 원인이 과대적합, 과소적합, 데이터 혹은 소프트웨어 결함(defect)인지 파악한다.
- 지속적인 공정 개선: 신규 데이터 수집, 초모수(hyperparameter) 조정, 알고리듬 변경 등
1.1. 목표 설정
오차가 전혀없는 기계학습 알고리듬을 개발하는 것은 불가능하다. 완벽하게 목표변수를 예측하는 데이터 수집이 불가능하기도 하고, 표현하는 알고리즘 자체가 확률적이라 일정부분 오차가 내재하기 때문이다. 또한, 기계학습 알고리듬이 처리할 수 있는 유효범위(Coverage) 를 잘 설정하는 것도 반듯이 필요하다.
1.2. 파이프 라인 구축
다양한 기계학습 알고리듬 적용을 고민할 필요없이, AI-complete 범주에 속하는 문제, 즉, 사물인식, 음성인식, 기계번역 등의 경우 기계학습/딥러닝을 적용한다.
- 기계학습/러닝 모형 선정
- 기존 논문에 제시된 가장 성능좋은 혹은 일반적으로 알려진 기계학습/딥러닝 알고리듬을 비교 벤치마킹 대상으로 선정한다.
- 고정길이 벡터 입력값이며 지도학습 알고리듬 → 전방향 신경망(feedforward network with fully connected layers)
- 영상처럼 위상관계(topology)가 알려진 경우 → 회선 신경망(Convolutional Neural Network)
- 입력 혹은 출력이 순열인 경우 → 창구가 있는 재귀 신경망(Gated Recurrent Neural Network), LSTM 혹 GRU
- 최적화 알고리즘
- 알고리듬 과대적합 방지, 오캄의 면도날
- 정규화 (Regularization)
- Dropout
- 조기 종류(Early Stopping)
1.3. 기계학습/딥러닝 알고리듬 성능 개선
분산과 편향이 높게 나타나서 전체적인 기계학습/딥러닝 알고리듬이 떨어지는 것이 관측되는 경우.
- 신규 학습 데이터 추가 → 분산이 큰 경우 해결책
- 모형에 사용되는 변수를 축소 → 분산이 큰 경우 해결책
- 모형에 변수를 추가 → 편향이 큰 경우 해결책
- 새로운 변수를 추가 → 편향이 큰 경우 해결책
- 최적화 알고리듬을 반복횟수를 증가 → 학습이 덜된 경우 최적화 알고리즘이 해결책
- 뉴톤 알고리듬을 적용 → 학습이 덜된 경우 다른 최적화 알고리즘을 탐색
- 학습율(learning rate), 운동량(moment)를 다르게 시도 → 학습이 덜된 경우 최적화 알고리즘 모수를 조정하는 것이 해결책
- SVM, RF 등 다양한 학습 알고리듬을 적용 → 학습이 잘 되지 않는 경우 다른 최적화 알고리즘 혹은 모형을 탐색
모형 성능에 다양한 초모수가 미치는 영향분석
통계학에 있어 이항 회귀모형과 통계 학습이론의 SVM 등 알고리듬이 성공적인 이유는 모수 1개, 2개만 설정하면 된다는 편리함에 있지만, 기계학습 신경망/딥러닝은 수십개 초모수를 수작업/반자동/자동으로 설정해주어야 좋은 성능을 기대할 수 있다.
| 초모수 | 성능 확장 | 사유 | 사전 주의 |
|---|---|---|---|
| 숨긴 유닛(hidden unit) 수 | 증가 | 모형의 표현력 증가 | 시간과 저장공간 비용 증가를 수반함 |
| 학습율 | 최적화 조정된 경우 | 잘못된 학습율 설정은 최적화 실패로 효과적인 모형이 아님 | |
| 회선 커널 폭 | 증가 | 커널폭을 증가는 모형 모수 증가로 이어짐 | 폭이 큰 커널은 협소한 출력 차원이 되어 모형 성능을 축소, 커널 폭이 커지면 모수 저장에 더 많은 저장영역이 필요하지만, 협소학 출력으로 저장비용은 감소기킴 |
| 묵시적 0 덧붙이기 | 증가 | 표현되는 크기를 크게함 | 연산 대부분에 시간과 저장공간 비용을 증가시킴 |
| 가중치 감쇠 계수 | 감소 | 모형 모수가 더 크게 되는 자유를 부여함 | |
| Dropout 율 | 감소 | 학습 데이터를 적합시키는데 숨긴 유닛이 공모하는 것을 차단 |
초모수 탐색 자동화 및 최적화
초모수 탐색을 자동화하는 알고리듬은 격자탐색(Grid search), 임의탐색(Random search)이 있다. 모형기반 초모수 최적화(Model-based hyperparameter optimization)도 활발하게 연구되고 있는 분야로, 베이즈 초모수 최적화(Bayesian hyperparameter optimization)도 추천되고는 방법론이다.
1.4. 디버깅 전략
기계학습 알고리듬이 잘 동작하지 않을 때 알고리듬 구현에 버그가 있는지, 알고리듬 자체에 문제가 있는지 판별이 되지 못한다. 기계학습 알고리듬이 데이터에 잘 적합하도록 구현을 하지만, 기계가 반환하는 결과가 원래 데이터에 내재된 것인지, 원래 데이터는 잘 준비가 되었으나 구현이 잘못된 것인지 명세를 할 수 없기 때문이다.
- 돌아가는 모형을 시각화: 사진에 담긴 이미지 탐지를 잘하는지, 소리를 잘 학습하는지 표본을 추출하여 모니터링한다. 정확도와 로그-우도비 통계량을 시점별로 모니터링하거나, 정량적인 성능 측도를 주시해 나간다.
- 최악 사례를 시각화: 가장 학습하기 어려운 학습데이터를 기계학습 알고리듬이 학습하는 것을 살펴보면 전처리과정 혹은 학습결과에서 단서를 발견할 수 있다.
- 학습오차, 검증 오차를 사용해서 소프트웨어에 대해 추론: 구현한 기계학습 알고리즘이 정상적으로 동작하는 소프트웨어인지 판별하는 것은 쉽지 않다. 하지만, 학습오차(train error)와 검증 오차(test error)를 통해 단서를 찾을 수는 있다. 예를 들어, 학습오차가 작고 검증오차가 크다면, 알고리듬이 과대적합한 것으로 판단할 수 있다. 혹은 그 반대의 경우도 있을 수 있다. 하지만, 학습오차와 검증오차가 모두 높은 경우 소프트웨어 결함인지 알고리듬 문제인지 단어하기는 쉽지 않다.
- 작은 데이터셋 적합: 학습데이터에 오차가 큰 경우, 소프트웨어 결함인지 순전히 과소적합문제인지 판단하라. 통상 작은 모형도 충분히 작은 데이터셋을 적합하는 것이 가능하다. 단일 사례를 올바르게 판별하는 분류기를 학습시킬 수 없거나, 고신뢰성을 갖고 표본을 일관되게 산출하지 못하는 오토인코더(autoencoder)를 학습시킬 수 없거나, 단일 사례를 닮은 표본을 산출해내는 생성모형을 학습시킬 수 없다면, 소프트웨어 결함이 있는 것으로 볼 수 있다.
- 수치 미분과 역전파 미분을 비교: 경사하강 알고리듬을 본인 구축하거나 미분 라이브러리에 신규 메쏘드를 추가한 경우 검토가 필요하다.
- 기울기와 활성화 히스토그램 주시: 기계학습 알고리듬이 학습을 하면서 생성해내는 데이터 중에서, 신경망 활성화 통계량과 기울기를 시각화는 것이 도움이 많이 된다.
2. 문자인식 및 동일인 인식 사례 1
2.1. 문자인식(OCR) 인식 시스템

기계학습 신경망/딥러닝 알고리즘 시스템 성능향상을 위해 자원을 어디에 가장 많이 사용해야 할까? 예를 들어 문자 인식 시스템 정확도가 다음과 같은 성능을 갖는다고 가정할 때 어느 부분에 가용자원을 투여하는 것이 가장 좋은 성과를 낼 수 있을까? 이것을 천정 분석(ceiling analysis) 라고 부른다. 문자 쪼개는데 많은 시간을 투여하기 보다 동일한 시간을 투여해서 전반적인 성능을 가장 많이 높일 수 있는 1순위로 문자영역 탐지, 2순위로 문자인식에 가용자원을 투여하는 것이 권장된다.
| 구성요소 | 정확도 | 향상 가능성 |
|---|---|---|
| 전체 시스템 | 72% | |
| 문자영역 탐지 | 89% | 17% |
| 문자 쪼개기 | 90% | 1% |
| 문자 인식 | 100% | 10% |
2.2. 동일인 인식 시스템
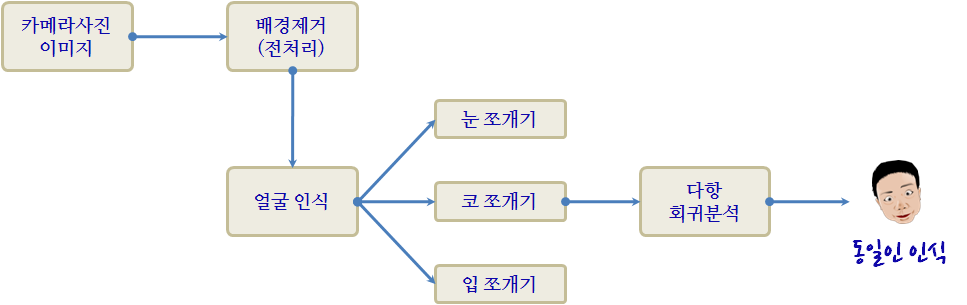
천정분석을 인식하기 전에는 동일인 인식 시스템 성능향상을 위해 스탠포드 대학원생 2명이 배경제거(전처리)에 약 2년 투여되었다. 하지만, 성능향상은 아무리 어렵고 좋은 알고리즘을 사용해도 전반적으로 높일 수 있는 천정이자 한계는 0.1%라 미미했다. 물론, 대학원생은 학회에 그동안의 작업에 대한 연구결과를 발표하고 졸업을 하고 향후 진로를 결정했지만, 아쉬운 점이 남는다. 예를 들어, 얼굴인식이 1순위, 눈쪼개기가 2순위, 다항 회귀분석이 3순위로 가용자원을 투여할 경우 전반적 성능은 더빨리 적은 노력과 비용으로 달성이 되었을 것이다.
| 구성요소 | 정확도 | 향상 가능성 |
|---|---|---|
| 전체 시스템 | 85% | |
| 배경제거(전처리) | 85.1% | 0.1 % |
| 얼굴 인식 | 91% | 5.9% |
| 눈 쪼개기 | 95% | 4% |
| 코 쪼개기 | 96% | 1% |
| 입 쪼개기 | 97% | 1% |
| 다항 회귀분석 | 100% | 3% |
Andrew Ng (2015), “Advice for applying Machine Learning”, Standford University