
xwMOOC 기계학습
기계학습 예측모형 기초
학습목표
- 예측모형 개발에 필요한 중요개념을 학습한다.
- 내표본, 외표본, 교차검증에 대해 살펴본다.
- 훈련/검증 데이터 쪼개기를 실습한다.
- 범주 예측에 활용되는 오차행렬를 생성한다.
caret팩키지 개발 배경을 이해한다.
1. 전통적 통계모형과 예측모형 비교
예측모형(Predictive Model)은 정확도가 높은 모형을 개발하는 과정이다. 따라서, 전통적 통계학에서 강조하는 추론, 타당성, 유의성, 가정과 같은 개념적인 것보다는 “실질적으로 정확하게 예측을 할 수 있는가?” 라는 문제늘 더 중요하게 다루고 있다.
예측모형에서 중요하게 고려되는 사항
- 예측모형 성능
- 예측의 단순성
- 복잡성과 컴퓨팅 비용을 줄이도록 변수(특성, Feature) 축소
- 예측수식 평활(smoothness)
- 예측모형의 강건성
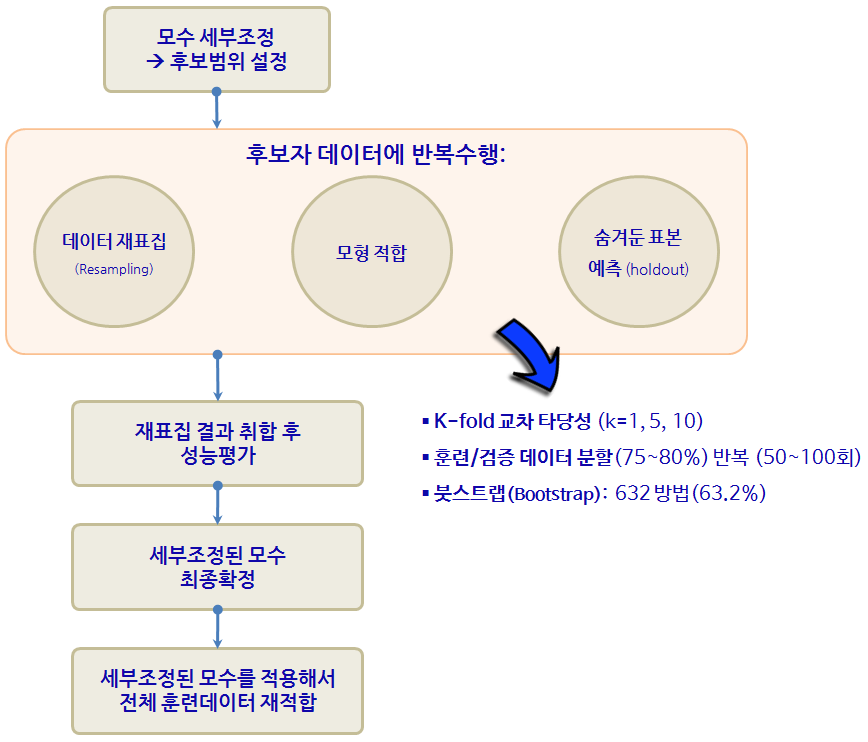
2. 찾으려는 예측모형 특성
오랜기간 좋은 예측모형을 찾으려고 백방으로 수소문하여 현재까지 가장 좋은 예측모형은 지금까지 보지 않던 표본 데이터에 가장 좋은 성능을 보여주는 예측모형이 답이다.
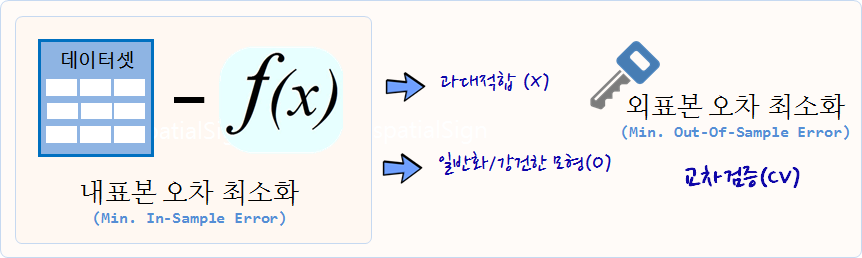
주어진 데이터에서 다양한 예측모형을 개발하지만, 결국 예측모형이 처음으로 접하는 데이터에도 좋은 성능을 내는, 즉 외표본 오차를 최소화하는 예측모형이 찾고자하는 모형이다.
이를 위해서 과대적합(Overfitting)하지 말하야 되고, 일반적/강건한 모형이 되어야 한다. 교차검증(Cross-Validation, CV) 방법이 이 문제에 대한 열쇠를 쥐고 있다.
2.1. 내표본 오차
과대적합에 대한 치료법으로 교차검증이 많이 활용되는데 먼저 내표본(In-sample) 오차를 계산한다. 가장 먼저 선형회귀모형을 보스톤 집값 데이터에 적합을 시키기 위해서 모형에 들어갈 변수를 선정하고, 예측모형을 lm 함수에 밀어 넣는데, 첫번째부터 100개 관측점만 모형에 사용한다.
그리고 나서, 선형 회귀식에 예측값을 산출하고 실제값과 RMSE 오차를 계산한다.
##==========================================================================================
## 03. 과대적합 - 교차검증
##==========================================================================================
#-------------------------------------------------------------------------------------------
# 03.01. 내표본 오차 계
#-------------------------------------------------------------------------------------------
glimpse(BostonHousing)Observations: 506
Variables: 14
$ crim <dbl> 0.00632, 0.02731, 0.02729, 0.03237, 0.06905, 0.02985, ...
$ zn <dbl> 18.0, 0.0, 0.0, 0.0, 0.0, 0.0, 12.5, 12.5, 12.5, 12.5,...
$ indus <dbl> 2.31, 7.07, 7.07, 2.18, 2.18, 2.18, 7.87, 7.87, 7.87, ...
$ chas <fctr> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
$ nox <dbl> 0.538, 0.469, 0.469, 0.458, 0.458, 0.458, 0.524, 0.524...
$ rm <dbl> 6.575, 6.421, 7.185, 6.998, 7.147, 6.430, 6.012, 6.172...
$ age <dbl> 65.2, 78.9, 61.1, 45.8, 54.2, 58.7, 66.6, 96.1, 100.0,...
$ dis <dbl> 4.0900, 4.9671, 4.9671, 6.0622, 6.0622, 6.0622, 5.5605...
$ rad <dbl> 1, 2, 2, 3, 3, 3, 5, 5, 5, 5, 5, 5, 5, 4, 4, 4, 4, 4, ...
$ tax <dbl> 296, 242, 242, 222, 222, 222, 311, 311, 311, 311, 311,...
$ ptratio <dbl> 15.3, 17.8, 17.8, 18.7, 18.7, 18.7, 15.2, 15.2, 15.2, ...
$ b <dbl> 396.90, 396.90, 392.83, 394.63, 396.90, 394.12, 395.60...
$ lstat <dbl> 4.98, 9.14, 4.03, 2.94, 5.33, 5.21, 12.43, 19.15, 29.9...
$ medv <dbl> 24.0, 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16.5, ...
# 1. 독립변수 선택
ind <- dput(names(BostonHousing))c("crim", "zn", "indus", "chas", "nox", "rm", "age", "dis", "rad",
"tax", "ptratio", "b", "lstat", "medv")
ind_sel <- setdiff(ind, c("medv", "chas"))
# 2. 모형 개발
housing_model <- as.formula(paste("medv", "~", paste(ind_sel, collapse="+"),collapse=""))
# 3. 모형 적합
model <- lm(housing_model, data=BostonHousing[1:100,])
# 4. 내표본 예측값 산출
predicted <- predict(model, BostonHousing[1:100, ], type = "response")
# 5. RMSE 오차 계산
actual <- BostonHousing[1:100, "medv"]
sqrt(mean((predicted - actual)^2)) [1] 2.037201
2.2. 내표본 오차
내표본 오차가 최소화되는 모형이 좋지만, 결국 중요한 것은 지금까지 보지 못한 사례 외표본에 대한 RMSE 오차를 계산하는 것이 성능이 좋은 예측모형인지 판단하는 근거가 된다.
#-------------------------------------------------------------------------------------------
# 03.02. 외표본 오차
#-------------------------------------------------------------------------------------------
# 3. 모형 적합
model <- lm(housing_model, data=BostonHousing[1:100,])
# 4. 내표본 예측값 산출
predicted <- predict(model, BostonHousing[101:200, ], type = "response")
# 5. RMSE 오차 계산
actual <- BostonHousing[101:200, "medv"]
sqrt(mean((predicted - actual)^2)) [1] 7.658793
2.3. 교차검증
내표본 오차와 외표본 오차 개념을 바탕으로 교차검증을 통해 선형회귀모형에 10번 적용한 후 가장 좋은 모형을 자동으로 뽑아낸다. caret 팩키지 train() 함수에 method = "cv", number = 10 인자를 설정하여 교차검증 방법을 적용한 선형회귀모형을 실행시킨다.
#-------------------------------------------------------------------------------------------
# 03.03. Cross Validation
#------------------------------------------------------------------------------------------
set.seed(77)
model <- train(housing_model, BostonHousing,
method = "lm",
trControl = trainControl(method = "cv", number = 10, verboseIter = TRUE)
)+ Fold01: parameter=none
- Fold01: parameter=none
+ Fold02: parameter=none
- Fold02: parameter=none
+ Fold03: parameter=none
- Fold03: parameter=none
+ Fold04: parameter=none
- Fold04: parameter=none
+ Fold05: parameter=none
- Fold05: parameter=none
+ Fold06: parameter=none
- Fold06: parameter=none
+ Fold07: parameter=none
- Fold07: parameter=none
+ Fold08: parameter=none
- Fold08: parameter=none
+ Fold09: parameter=none
- Fold09: parameter=none
+ Fold10: parameter=none
- Fold10: parameter=none
Aggregating results
Fitting final model on full training set
modelLinear Regression
506 samples
13 predictor
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 457, 456, 455, 454, 456, 455, ...
Resampling results:
RMSE Rsquared
4.774371 0.72811
2.4. 데이터 쪼개기
데이터 중심 예측모형을 개발하는 경우 데이터를 훈련 데이터와 검증 데이터로 나누어야 한다. base 팩키지에 준비된 sample 함수를 활용하여 7:3 테스트:검증 비율을 정해 데이터를 준비하는 것도 가능하다.
다른 한가지 방법은 caret 팩키지의 createDataPartition 팩키지 함수에 인자를 던져 7:3 테스트:검증 데이터를 생성하는 것이다.
#-------------------------------------------------------------------------------------------
# 03.01. 데이터 쪼개기
#-------------------------------------------------------------------------------------------
# 1. 데이터 랜덤 정렬
set.seed(77)
Sonar <- Sonar[sample(nrow(Sonar)), ]
# 2. 70:30 데이터 분리
idx <- round(nrow(Sonar) * .7)
train <- Sonar[1:idx, ]
test <- Sonar[(idx+1):nrow(Sonar), ]
# 3. 70:30 데이터 검증
nrow(train) / nrow(Sonar)[1] 0.7019231
nrow(test) / nrow(Sonar)[1] 0.2980769
#-------------------------------------------------------------------------------------------
# 03.02. 데이터 쪼개기: caret
#-------------------------------------------------------------------------------------------
# 1. 70:30 데이터 분리
idx <- createDataPartition(Sonar$Class, p = .70, list= FALSE)
caret_train <- Sonar[idx, ]
caret_test <- Sonar[-idx, ]
# 2. 70:30 데이터 검증
nrow(caret_train) / nrow(Sonar)[1] 0.7019231
nrow(caret_test) / nrow(Sonar)[1] 0.2980769
3. caret 팩키지
caret 팩키지와 같은 예측모형 전용 팩키지가 필요한 이유는 너무나 많은 예측모형이 존재하고, 더 큰 문제는 사용법과 해석이 모두 다르다는데 있다. 너무 많은 사람이들이 오랜기간에 걸쳐 개발하다보니 어쩌면 당연한 문제라고 볼 수도 있다.
3.1. R 팩키지 구문
기계학습에서 가장 많이 작업하는 것 중에 하나가 분류문제에 대한 예측 알고리즘을 제시하는 것이다. 데이터도 다양하지만, 분류문제에 대한 다양한 이론이 존재하고, R로 구현된 팩키지도 정말 다양한다. 예를 들어, lda는 판별분석(Linear Discrimant Analsyis)을 돌릴 때 사용되는 것으로 MASS 팩키지에 포함되어 있고, 훈련데이터 혹은 검증데이터에 예측값을 구할 경우 predict 함수에 lda 반환값을 넣어주면 되고 추가설정은 필요없다. glm은 일반화 선형모형을 적합할 때 특히 링크함수로 logit을 넣어 설정하고 stats 팩키지에 포함되어 있고, 구문은 lda와 확연한 차이를 볼 수 있다.
gbm, mda, rpart, Weka, LogitBoost등 다양한 예측 알고리즘이 존재한다. 다음은 Max Kuhn 박사가 caret을 개발한 주요한 사유로 정리한 표다. 이를 일관된 인터페이스로 제공하고 나아가 각 모형의 성능을 객관적으로 비교할 수 있는 성능평가 지표 도출 및 확정을 위해서 꼭 필요한 것으로 판단된다. (본인이 필요해서 개발하지 않았을까 생각되고, 누구나 이런 코드는 갖고 있는데 체계적으로 정리해서 공개한 후, 10년에 걸쳐 시간을 투여한 Kuhn 박사님께 감사드립니다.)
| 예측함수명 | 팩키지명 | predict 함수 예측구문 |
|---|---|---|
| lda | MASS | predict(obj) (추가 인자설정 불필요) |
| glm | stats | predict(obj, type = “response”) |
| gbm | gbm | predict(obj, type = “response”, n.trees) |
| mda | mda | predict(obj, type = “posterior”) |
| rpart | rpart | predict(obj, type = “prob”) |
| Weka | RWeka | predict(obj, type = “probability”) |
| LogitBoost | caTools | predict(obj, type = “raw”, nIter) |
caret에서 지원하는 예측모형 목록 중 일부는 다음과 같고, 전체 목록은 예측모형 caret 목록을 참조한다. 2014년 2월 기준 예측모형과 예측함수 147개, 2016년 1월 기준 216개 폭증.
| 모형 | 예측함수명 | 팩키지 | 세부조정 모수 |
|---|---|---|---|
| 재귀적 분할 | rpart | rpart | maxdepth |
| Boosted trees | gbm | gbm | interaction.depth, n.trees, shrinkage |
| Random forests | rf | randomForest | mtry |
| 신경망 | nnet | nnet | decay, size |
| Support Vector Machine (RBF 커널) | svmRadial | kernlab | sigma, C |
| Support Vector Machine (다항식 커널) | svmPoly | kernlab | scale, degree, C |
| 선형회귀 | lm | stats | 없음 |
| … | … | … | … |
4. 오차 행렬(Confusion Matrix)
범주형 특히, 채무불이행과 정상과 같은 두가지 범주를 예측하는 경우 예측모형을 사용해서 도출된 값은 0과 1사이 확률값으로 나타난다. glm 함수에 family = "binomial" 인자를 넣어 로지스틱 모형을 개발하고, predict 함수에 모형과 검증 데이터를 넣게 되면 검증 데이터의 확률값이 생성된다.
##==========================================================================================
## 03. 모형적합
##==========================================================================================
#-------------------------------------------------------------------------------------------
# 03.01. 데이터 쪼개기
#-------------------------------------------------------------------------------------------
# 1. 데이터 랜덤 정렬
set.seed(77)
Sonar <- Sonar[sample(nrow(Sonar)), ]
# 2. 70:30 데이터 분리
idx <- round(nrow(Sonar) * .7)
train <- Sonar[1:idx, ]
test <- Sonar[(idx+1):nrow(Sonar), ]
# 3. 70:30 데이터 검증
nrow(train) / nrow(Sonar)[1] 0.7019231
nrow(test) / nrow(Sonar)[1] 0.2980769
#-------------------------------------------------------------------------------------------
# 03.02. 이항회귀 모형
#-------------------------------------------------------------------------------------------
# 모형적합
model_logit <- glm(Class ~ ., family = "binomial", data=train)ifelse 함수를 사용해서 컷오프 기준(예를 들어, 0.5)을 정하고 기뢰(“M”), 바위(“R”)를 예측한다. 이를 검증데이터 실제값과 교차분석 표를 생성하게 되면 오차행렬을 통해 예측모형에 대한 성능이 도출된다.
confusionMatrix 행렬을 사용하게 되면 훨씬 더 유용한 정보가 많이 도출된다.
##==========================================================================================
## 04. 성능평가
##==========================================================================================
#-------------------------------------------------------------------------------------------
# 04.01. 이항회귀 모형 성능평가: 기본
#-------------------------------------------------------------------------------------------
# 확률 -> 범주예측값 전환
logit_prob <- predict(model_logit, test, type = "response")
logit_prob_class <- ifelse(logit_prob > .5, "M", "R")
table(logit_prob_class)logit_prob_class
M R
21 41
# 오차행렬
table(logit_prob_class, test[["Class"]])
logit_prob_class M R
M 4 17
R 31 10
#-------------------------------------------------------------------------------------------
# 04.02. 이항회귀 모형 성능평가: `caret`
#-------------------------------------------------------------------------------------------
# install.packages("e1071")
confusionMatrix(logit_prob_class, test[["Class"]]) Confusion Matrix and Statistics
Reference
Prediction M R
M 4 17
R 31 10
Accuracy : 0.2258
95% CI : (0.1293, 0.3497)
No Information Rate : 0.5645
P-Value [Acc > NIR] : 1.0000
Kappa : -0.4865
Mcnemar's Test P-Value : 0.0606
Sensitivity : 0.11429
Specificity : 0.37037
Pos Pred Value : 0.19048
Neg Pred Value : 0.24390
Prevalence : 0.56452
Detection Rate : 0.06452
Detection Prevalence : 0.33871
Balanced Accuracy : 0.24233
'Positive' Class : M