
데이터 과학
데이터 가져오기
학습 목표 1
- R로 다양한 원천자료를 가져온다.
- 로컬디스크, 데이터베이스, 웹 인터넷 데이터 출처를 이해한다.
- 활성도가 높은 R 팩키지를 취사선택하여 데이터 가져오기 프로세스를 정형화한다.
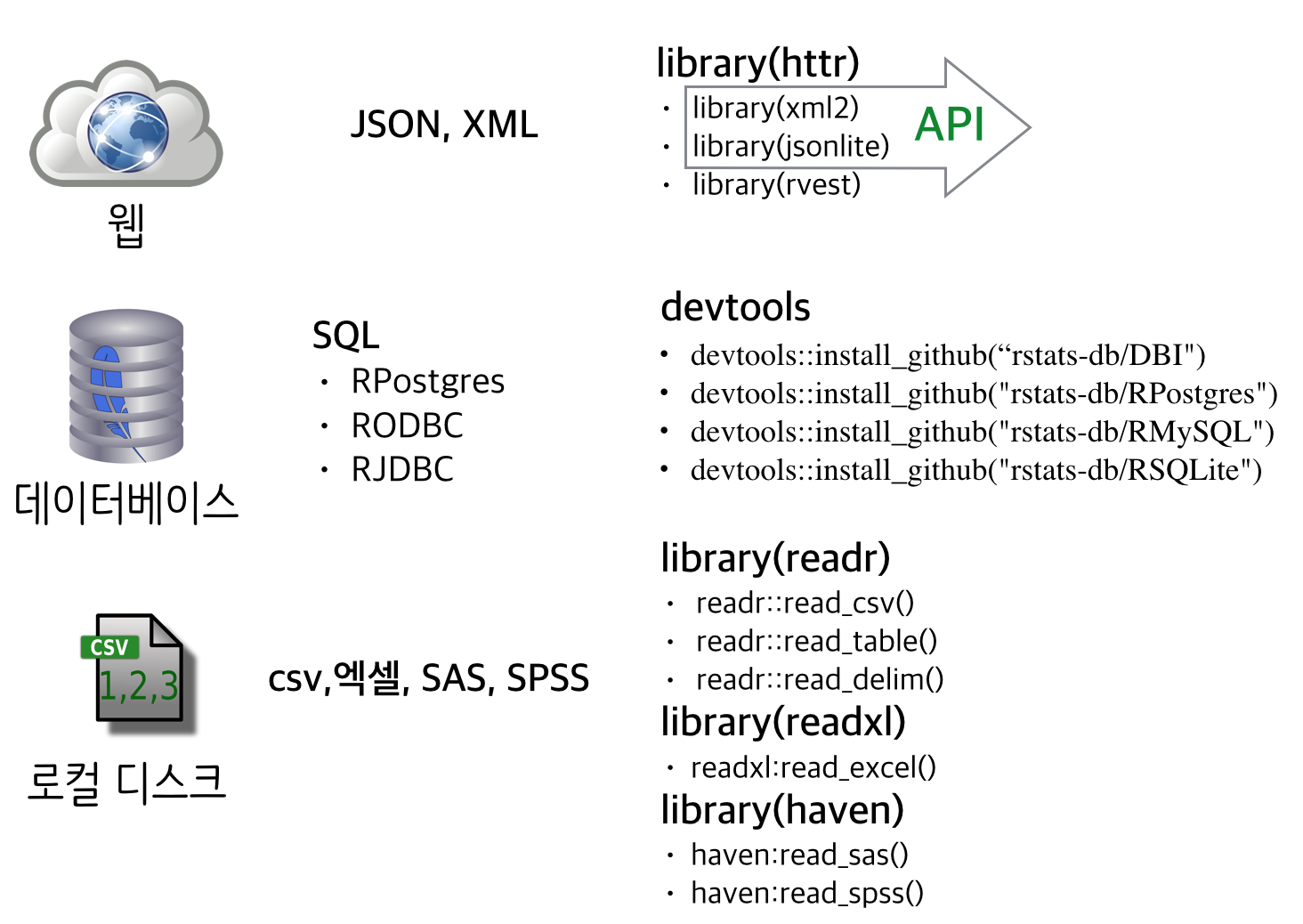
1. 공공데이터 출처
공공데이터는 과거 로컬디스크에서 . csv, .xlsx, SAS, SPSS, 미니탭 등 형식 파일로 제공되었으나, SQL 데이터베이스에 ODBC, JDBC, DBI 등 인터페이스를 통해 직접 접근하여 데이터를 뽑아올 수도 있고, 인터넷 웹을 통해 XML, JSON 등의 형식으로 받아올 수도 있다.
R로 데이터를 불러와야만 자료분석을 시작이 시작된다. 전통적인 방법으로 자료분석(로컬 컴퓨터에 파일형태로 저장된 다양한 파일을 불러오는 방법)을 시작할 수 있는 방법이 statmethods.net 사이트에 소개되어 있다.
- CSV :
.csv파일 - Excel :
.xlsx파일 - 통계 팩키지
- SPSS :
.por파일 - SAS :
xpt파일 - 미니탭 :
.mtp파일
- SPSS :
다양한 데이터를 R로 불러와서 작업하는 방법은 Datacamp 블로그와 r-bloggers에서 확인이 가능하다.
2. 로컬 데이터
전통적으로 많이 활용하는 방식으로 . csv, .xlsx, SAS, SPSS, 미니탭 등 다양한 파일 형식에 담긴 정보를 R에서 readr, readxl, haven 팩키지를 활용하여 R에서 분석할 수 있는 R 데이터프레임으로 불러온다.
2.1. readr 데이터 가져오기 2
readr에는 다양한 데이터 가져오기 기능이 제공된다. 다음과 같은 형태의 데이터프레임을 생성하는 것이 목표다. 하지만, 원본 데이터를 살펴보니 탭구분자로 나눠져있고, 칼럼명은 존재하지 않고 첫줄부터 바로 데이터가 들어 있는 형태다. 데이터의 일부를 텍스트 벡터로 불러온다.
spec_tsv 함수를 통해 파일에 포함된 데이터 자료구조에 대해서 확인이 가능하다. col_names = FALSE 명령어로 첫행부터 데이터가 시작된다고 일러준다. 그리고, na = c("", "NA", "null")을 통해 결측값에 대해서도 확인한다.
| professor | department | age | tenure | gender | salary |
|---|---|---|---|---|---|
| Prof | B | 19 | 18 | Male | 139750 |
| Prof | B | 20 | 16 | Male | 173200 |
| AsstProf | B | 4 | 3 | Male | 79750 |
| Prof | B | 45 | 39 | Male | 115000 |
| Prof | B | 40 | 41 | Male | 141500 |
| AssocProf | B | 6 | 6 | Male | 97000 |
library(readr)
spec_tsv("data/salary.txt", col_names = FALSE, na = c("", "NA", "null"))Parsed with column specification:
cols(
X1 = col_character(),
X2 = col_character(),
X3 = col_integer(),
X4 = col_character(),
X5 = col_character(),
X6 = col_integer()
)
cols(
X1 = col_character(),
X2 = col_character(),
X3 = col_integer(),
X4 = col_character(),
X5 = col_character(),
X6 = col_integer()
)
spec_tsv를 통해 제시된 칼럼형식이 맞는지 점검하고 이를 복사해서 read_tsv 파일로 불러 읽어온다. 마지막으로 칼럼명을 names 함수를 사용해서 부여하면 칼럼명 없이 탭구분자로 구분된 파일을 데이터프레임으로 가져오게 된다.
df <- read_tsv("data/salary.txt", col_names = FALSE, na = c("", "NA", "null"),
cols(
X1 = col_character(),
X2 = col_character(),
X3 = col_integer(),
X4 = col_integer(),
X5 = col_character(),
X6 = col_integer())
)
names(df) <- c("professor", "department", "age", "tenure", "gender", "salary")탭구분자를 갖는 read_tsv 파일 대신에 콤마 구분자를 갖는 경우 read_csv가 되고, spec_csv 로 칼럼 데이터형을 유추하는 함수명만 달라질 뿐 파일데이터를 데이터프레임으로 불러오는 과정은 동일하다.
3. 데이터베이스(SQL)
데이터베이스에서 R로 데이터를 불러오는 방식은 기본적으로 DBI, RODBC 등 팩키지를 불러와서 적재한다. 목표 데이터베이스에 연결하고, SQL 쿼리를 데이터베이스에 던져 결과를 얻어와서 데이터프레임에 저장한다. 데이터 정합성 검사를 하고 모든 것이 정상적이면 데이터베이스 연결을 끊어 자원을 반납한다.
3.1. 데이터베이스 연결 작업흐름
# 1) DBI 팩키지 불러오기
library(DBI)
# 2) 특정 데이터베이스 연결
db <- dbConnect(RPostgres::Postgres(), user, pass, ...)
db <- dbConnect(RMySQL::MySQL(), user, pass, ...)
db <- dbConnect(RSQLite::SQLite(), path)
# 3) SQL 쿼리
dbGetQuery(db, "SELECT * FROM mtcars")
# 4) 연결 끊기
dbDisconnect(db)3.2. rstats-db
GitHub에 rstats-db 저장소에는 MySQL, Postgres, SQLite 등 다양한 데이터베이스에 연결해서 R로 데이터를 가져오는 팩키지가 개발되고 있다. library 함수보다 devtools 함수를 사용해서 연관된 팩키지를 설치하여 데이터를 가져올 필요가 있다.
# http://github.com/rstats-db/
devtools::install_github("rstats-db/DBI")
devtools::install_github("rstats-db/RPostgres")
devtools::install_github("rstats-db/RMySQL")
devtools::install_github("rstats-db/RSQLite")4. 웹 인터넷 데이터
최근에 많은 공공데이터가 웹인터넷을 통해 배포되고 있다. XML, JSON이 많이 사용되고 있다. 특히, XML, JSON은 API를 통해 제공되는 정형화된 데이터로 통용되며, 그렇지 않고 데이터가 제공되는 경우 HTML 페이지를 웹스크래핑해서 데이터를 퍼온다.
XML libxml2에 대응되는 xml2 팩키지를 사용하고, JSON의 경우, jsonlite 팩키지를 사용한다. API를 통해 데이터가 제공되지 않는 경우, rvest 팩키지를 통해 HTML 페이지 데이터를 긁어온다.
4.1. JSON 데이터 가져오기
JSON 팩키지에는 다양한 팩키지가 존재한다. 역시 R이 발전한 이유인 다양성과 유연성이 JSON에도 존재하는 것이 확인된다. jsonlite 최근에 업데이트되어 사용하는 것도 좋을 듯 하다.
JSON 데이터를 R로 불러오는 경우 JSON 파일 형식에 특별히 신경을 써야한다. 우선 JSON 로그 데이터가 많은 경우 쉘에서 전처리 작업을 통해 sample.json 파일 형식으로 JSON 데이터를 준비한 후, fromJSON 함수로 불러오면 R에서 작업할 수 있는 데이터프레임으로 변환된다.
- jsonlite: RJSONIO를 포크해서 시작했으나 완전히 새롭게 작성됨.
- RJSONIO: 저자 Duncan Temple Lang
- rjson
- tidyjson : JSON을 깔끔한 tidy 형식으로 변환.
library(jsonlite)Loading required package: methods
sample.json <-
'[
{"Name" : "Mario", "Age" : 32, "Occupation" : "Plumber"},
{"Name" : "Peach", "Age" : 21, "Occupation" : "Princess"},
{},
{"Name" : "Bowser", "Occupation" : "Koopa"}
]'
sample.df <- fromJSON(sample.json)
sample.df Name Age Occupation
1 Mario 32 Plumber
2 Peach 21 Princess
3 <NA> NA <NA>
4 Bowser NA Koopa
JSON 쉘관련 전처리 작업에 유용하게 사용되는 명령어를 정리하면 다음과 같다.
sample-file.json 파일에 행바뀜 마지막에 ,를 추가하는 명령어는 sed -i ':a;N;$!ba;s/\n/,\n/g'이고, 첫줄에 [, 마지막 줄에 ]을 넣어 위와 같이 sample.json 파일이 되도록 JSON 파일을 준비한다.
$ sed -i ':a;N;$!ba;s/\n/,\n/g' sample-file.json
$ sed -i '1i [' sample-file.json
$ echo "]" >> sample-file.json